SDGym
v0.9.1 - 2024-08-29
このリポジトリは、DataceboのプロジェクトであるSynthetic Data Vault Projectの一部です。

Synthetic Data Gym(SDGYM)は、合成データをモデリングおよび生成するためのベンチマークフレームワークです。さまざまな合成データモデリング手法でパフォーマンスとメモリの使用量を測定します - 古典的な統計、深い学習など!
SDGYMライブラリは、合成データボールトエコシステムと統合されています。ベンチマークには、シンセサイザー、データセット、またはメトリックを使用できます。また、プロセスをカスタマイズして、独自の作業を含めることもできます。
PIPまたはCondaを使用してSDGYMをインストールします。デバイス上の他のソフトウェアとの競合を回避するために、仮想環境を使用することをお勧めします。
pip install sdgymconda install -c pytorch -c conda-forge sdgymSDGYMの使用の詳細については、SDGYMドキュメントをご覧ください。
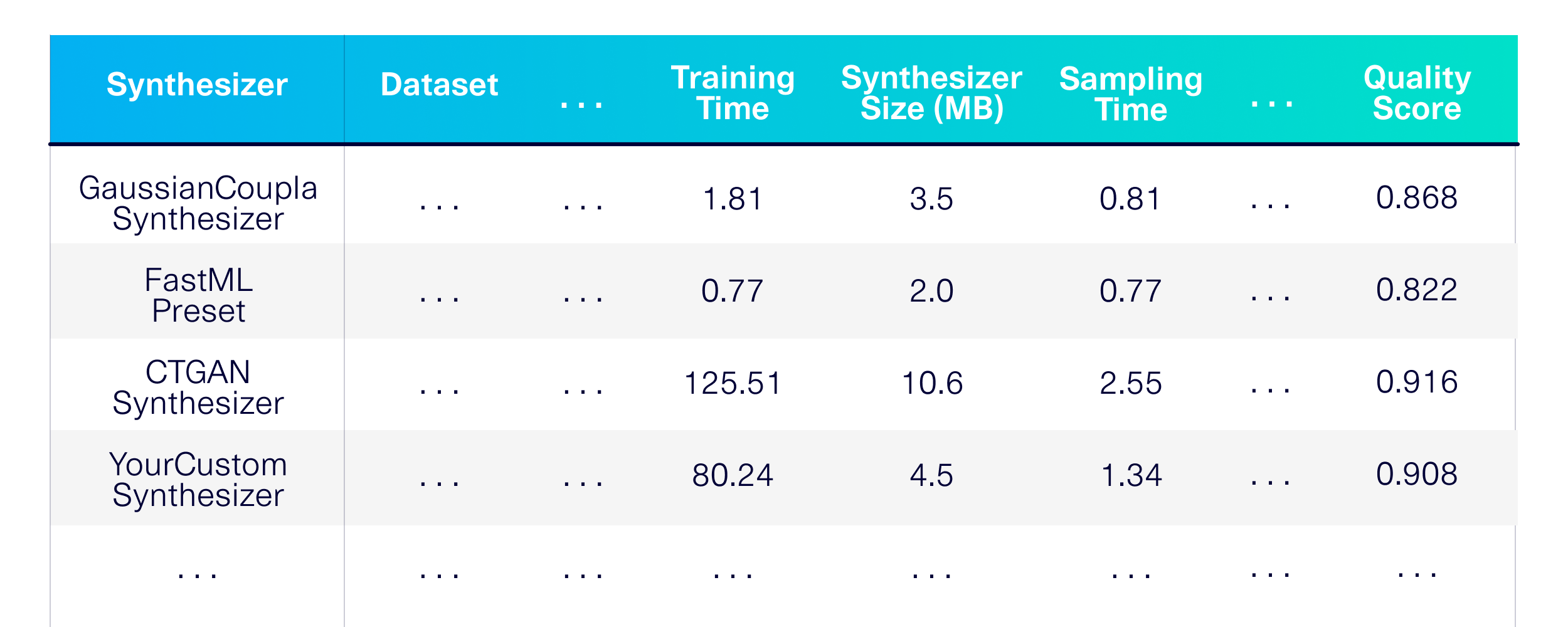
シングルテーブルの合成データ生成をベンチマークしましょう。まず、使用するモデリング手法を定義しましょう。 SDVライブラリからいくつかのシンセサイザーを選択し、ベースラインとして使用する他のいくつかを選択しましょう。
# these synthesizers come from the SDV library
# each one uses different modeling techniques
sdv_synthesizers = [ 'GaussianCopulaSynthesizer' , 'CTGANSynthesizer' ]
# these basic synthesizers are available in SDGym
# as baselines
baseline_synthesizers = [ 'UniformSynthesizer' ]これで、さまざまなテクニックをベンチマークできます。
import sdgym
sdgym . benchmark_single_table (
synthesizers = ( sdv_synthesizers + baseline_synthesizers )
)その結果、さまざまな公開データセットでシンセサイザー全体で詳細なパフォーマンス、メモリ、品質評価が得られます。
独自の合成データ生成手法をベンチマークします。トレーニングロジック(機械学習を使用)とサンプリングロジックを指定して、シンセサイザーを定義します。
def my_training_logic ( data , metadata ):
# create an object to represent your synthesizer
# train it using the data
return synthesizer
def my_sampling_logic ( trained_synthesizer , num_rows ):
# use the trained synthesizer to create
# num_rows of synthetic data
return synthetic_data詳細については、カスタムシンセサイザーガイドをご覧ください。
SDGYMライブラリには、すぐに含めることができる多くの公開されているデータセットが含まれています。 get_available_datasets機能を使用してこれらをリストします。
sdgym . get_available_datasets () dataset_name size_MB num_tables
KRK_v1 0.072128 1
adult 3.907448 1
alarm 4.520128 1
asia 1.280128 1
...
また、Amazon S3バケットにコンピューターに保存されているカスタムのプライベートデータセットを含めることもできます。
my_datasets_folder = 's3://my-datasets-bucket'
詳細については、カスタマイズされたデータセットについては、ドキュメントを参照してください。
詳細については、SDGYMドキュメントをご覧ください!

Synthetic Data Vaultプロジェクトは、2016年にMITのData Data To AI Labに最初に作成されました。エンタープライズとの4年間の研究と牽引の後、2020年にプロジェクトを成長させることを目指してDataceboを作成しました。今日、Dataceboは、合成データ生成と評価のための最大のエコシステムであるSDVの誇り高い開発者です。次のような合成データをサポートする複数のライブラリがあります。
完全に統合されたソリューションであり、合成データのワンストップショップであるSDVパッケージの使用を開始します。または、特定のニーズに合わせてスタンドアロンライブラリを使用します。


