SDGym
v0.9.1 - 2024-08-29
พื้นที่เก็บข้อมูลนี้เป็นส่วนหนึ่งของโครงการ Synthetic Data Vault ซึ่งเป็นโครงการจาก Datacebo

The Synthetic Data Gym (SDGYM) เป็นกรอบการเปรียบเทียบสำหรับการสร้างแบบจำลองและสร้างข้อมูลสังเคราะห์ วัดประสิทธิภาพและการใช้หน่วยความจำในเทคนิคการสร้างแบบจำลองข้อมูลสังเคราะห์ที่แตกต่างกัน - สถิติคลาสสิกการเรียนรู้ลึกและอื่น ๆ !
ห้องสมุด SDGYM รวมเข้ากับระบบนิเวศของข้อมูลสังเคราะห์ คุณสามารถใช้ synthesizers ชุดข้อมูลหรือตัวชี้วัดใด ๆ สำหรับการเปรียบเทียบ นอกจากนี้คุณยังสามารถปรับแต่งกระบวนการเพื่อรวมงานของคุณเอง
ติดตั้ง SDGYM โดยใช้ PIP หรือ Conda เราขอแนะนำให้ใช้สภาพแวดล้อมเสมือนจริงเพื่อหลีกเลี่ยงความขัดแย้งกับซอฟต์แวร์อื่น ๆ บนอุปกรณ์ของคุณ
pip install sdgymconda install -c pytorch -c conda-forge sdgymสำหรับข้อมูลเพิ่มเติมเกี่ยวกับการใช้ SDGYM โปรดเยี่ยมชมเอกสาร SDGYM
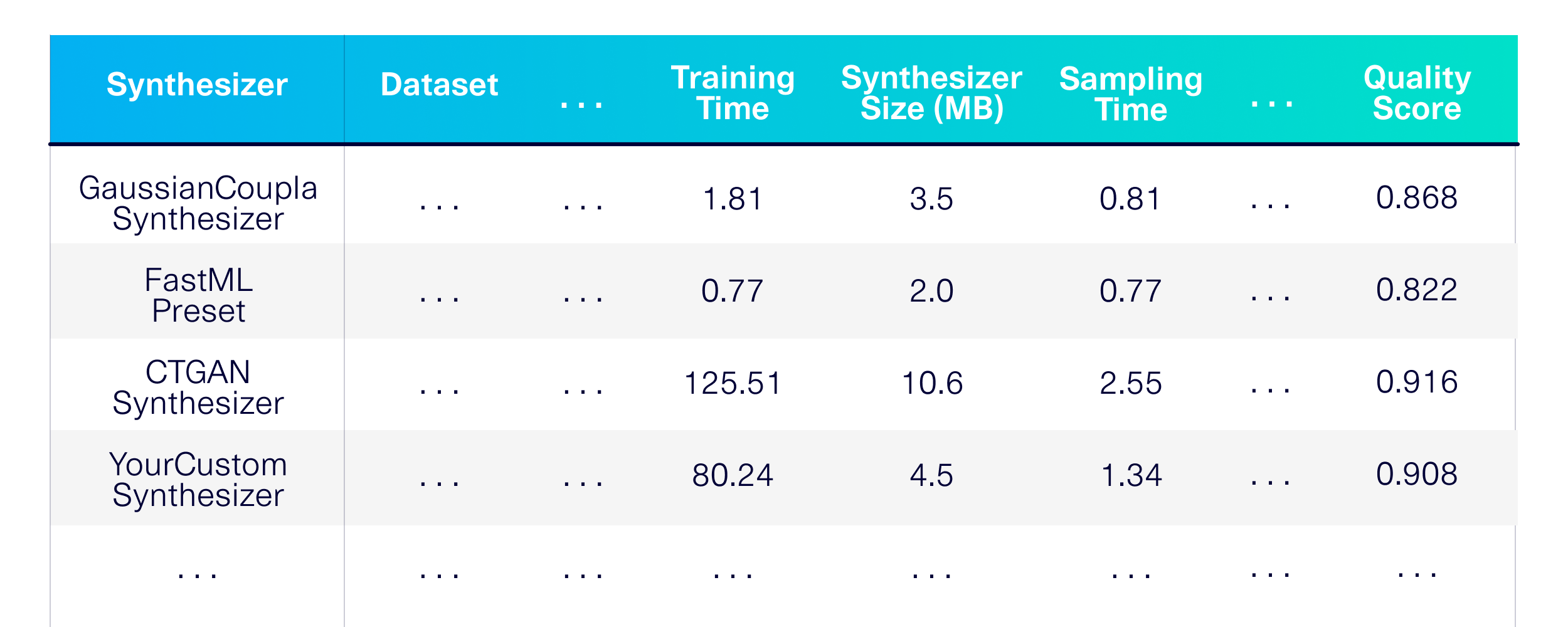
มาเป็นมาตรฐานการสร้างการสร้างข้อมูลสังเคราะห์สำหรับตารางเดี่ยว ก่อนอื่นมากำหนดเทคนิคการสร้างแบบจำลองที่เราต้องการใช้ ลองเลือกซินธิไซเซอร์สองสามตัวจากไลบรารี SDV และอีกสองสามอย่างที่จะใช้เป็น baselines
# these synthesizers come from the SDV library
# each one uses different modeling techniques
sdv_synthesizers = [ 'GaussianCopulaSynthesizer' , 'CTGANSynthesizer' ]
# these basic synthesizers are available in SDGym
# as baselines
baseline_synthesizers = [ 'UniformSynthesizer' ]ตอนนี้เราสามารถเปรียบเทียบเทคนิคต่าง ๆ :
import sdgym
sdgym . benchmark_single_table (
synthesizers = ( sdv_synthesizers + baseline_synthesizers )
)ผลที่ได้คือประสิทธิภาพรายละเอียดหน่วยความจำและการประเมินคุณภาพทั่วทั้งซินธิไซเซอร์ในชุดข้อมูลที่เปิดเผยต่อสาธารณะที่หลากหลาย
เกณฑ์มาตรฐานเทคนิคการสร้างข้อมูลสังเคราะห์ของคุณเอง กำหนดซินธิไซเซอร์ของคุณโดยระบุตรรกะการฝึกอบรม (โดยใช้การเรียนรู้ของเครื่อง) และตรรกะการสุ่มตัวอย่าง
def my_training_logic ( data , metadata ):
# create an object to represent your synthesizer
# train it using the data
return synthesizer
def my_sampling_logic ( trained_synthesizer , num_rows ):
# use the trained synthesizer to create
# num_rows of synthetic data
return synthetic_dataเรียนรู้เพิ่มเติมในคู่มือ synthesizers ที่กำหนดเอง
ห้องสมุด SDGYM มีชุดข้อมูลที่เปิดเผยต่อสาธารณะมากมายที่คุณสามารถรวมได้ทันที แสดงรายการเหล่านี้โดยใช้คุณสมบัติ get_available_datasets
sdgym . get_available_datasets () dataset_name size_MB num_tables
KRK_v1 0.072128 1
adult 3.907448 1
alarm 4.520128 1
asia 1.280128 1
...
นอกจากนี้คุณยังสามารถรวมชุดข้อมูลส่วนตัวที่กำหนดเองที่เก็บไว้ในคอมพิวเตอร์ของคุณในถัง Amazon S3
my_datasets_folder = 's3://my-datasets-bucket'
สำหรับข้อมูลเพิ่มเติมดูเอกสารสำหรับชุดข้อมูลที่กำหนดเอง
เยี่ยมชมเอกสาร SDGYM เพื่อเรียนรู้เพิ่มเติม!

โครงการ Synthetic Data Vault ถูกสร้างขึ้นเป็นครั้งแรกที่ข้อมูลของ MIT ไปยัง AI Lab ในปี 2559 หลังจาก 4 ปีของการวิจัยและการลากกับ Enterprise เราได้สร้าง Datacebo ในปี 2020 โดยมีเป้าหมายในการเติบโตโครงการ วันนี้ Datacebo เป็นผู้พัฒนาที่ภาคภูมิใจของ SDV ซึ่งเป็นระบบนิเวศที่ใหญ่ที่สุดสำหรับการสร้างและประเมินผลข้อมูลสังเคราะห์ เป็นที่ตั้งของห้องสมุดหลายแห่งที่รองรับข้อมูลสังเคราะห์รวมถึง:
เริ่มต้นใช้แพ็คเกจ SDV-โซลูชันแบบครบวงจรและร้านค้าครบวงจรของคุณสำหรับข้อมูลสังเคราะห์ หรือใช้ไลบรารีแบบสแตนด์อโลนสำหรับความต้องการเฉพาะ


