SDGym
v0.9.1 - 2024-08-29
Este repositorio es parte del proyecto de bóveda de datos sintéticos, un proyecto de DataCebo.

El gimnasio de datos sintéticos (SDGYM) es un marco de evaluación comparativa para modelar y generar datos sintéticos. Mida el rendimiento y el uso de la memoria en diferentes técnicas de modelado de datos sintéticos: estadísticas clásicas, aprendizaje profundo y más.
La biblioteca SDGYM se integra con el ecosistema de bóveda de datos sintéticos. Puede usar cualquiera de sus sintetizadores, conjuntos de datos o métricas para la evaluación comparativa. También puede personalizar el proceso para incluir su propio trabajo.
Instale SDGYM con PIP o conda. Recomendamos utilizar un entorno virtual para evitar conflictos con otro software en su dispositivo.
pip install sdgymconda install -c pytorch -c conda-forge sdgymPara obtener más información sobre el uso de SDGYM, visite la documentación SDGYM.
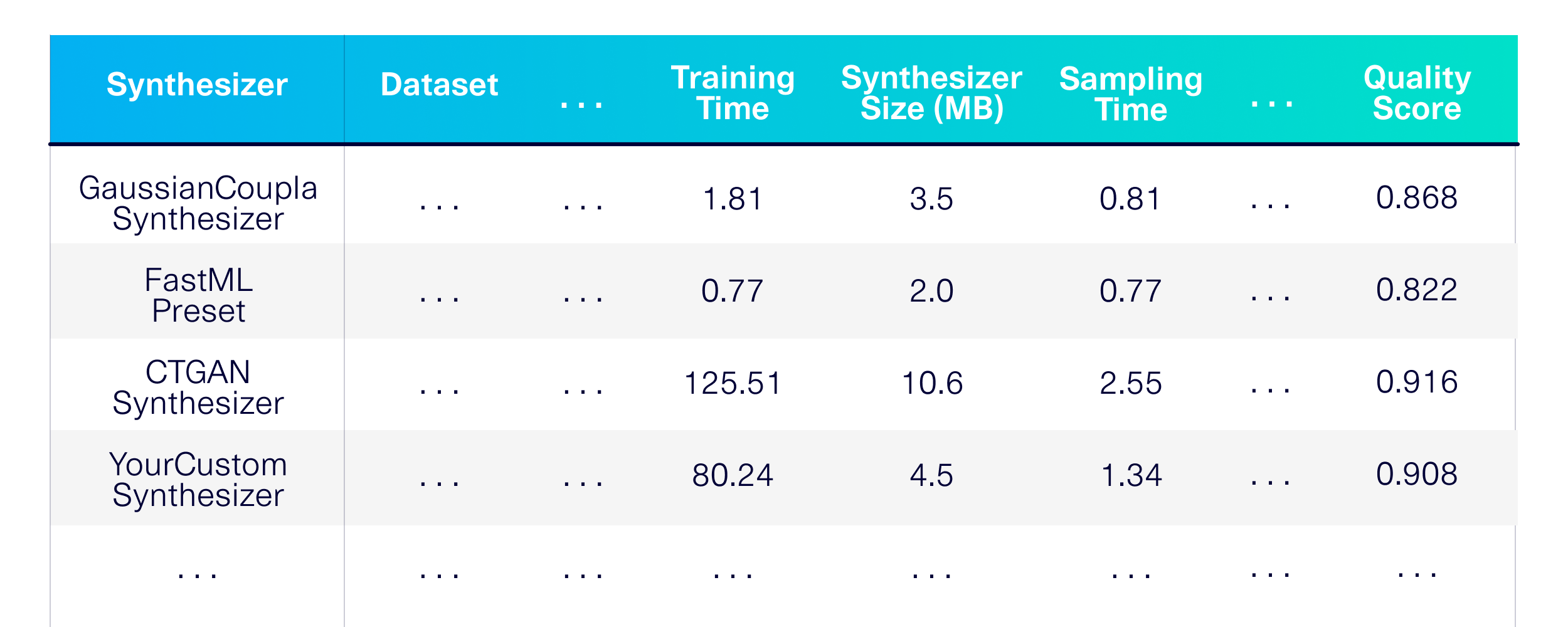
Benchmaramos la generación de datos sintéticos para tablas individuales. Primero, definamos qué técnicas de modelado queremos usar. Elegamos algunos sintetizadores de la biblioteca SDV y algunos otros para usar como líneas de base.
# these synthesizers come from the SDV library
# each one uses different modeling techniques
sdv_synthesizers = [ 'GaussianCopulaSynthesizer' , 'CTGANSynthesizer' ]
# these basic synthesizers are available in SDGym
# as baselines
baseline_synthesizers = [ 'UniformSynthesizer' ]Ahora, podemos comparar las diferentes técnicas:
import sdgym
sdgym . benchmark_single_table (
synthesizers = ( sdv_synthesizers + baseline_synthesizers )
)El resultado es una evaluación detallada de rendimiento, memoria y calidad en los sintetizadores en una variedad de conjuntos de datos disponibles públicamente.
Bencela sus propias técnicas de generación de datos sintéticos. Defina su sintetizador especificando la lógica de entrenamiento (usando el aprendizaje automático) y la lógica de muestreo.
def my_training_logic ( data , metadata ):
# create an object to represent your synthesizer
# train it using the data
return synthesizer
def my_sampling_logic ( trained_synthesizer , num_rows ):
# use the trained synthesizer to create
# num_rows of synthetic data
return synthetic_dataObtenga más información en la Guía de sintetizadores personalizados.
La biblioteca SDGYM incluye muchos conjuntos de datos disponibles públicamente que puede incluir de inmediato. Enumere estos usando la función get_available_datasets .
sdgym . get_available_datasets () dataset_name size_MB num_tables
KRK_v1 0.072128 1
adult 3.907448 1
alarm 4.520128 1
asia 1.280128 1
...
También puede incluir cualquier conjunto de datos privados personalizados que se almacenen en su computadora en un cubo de Amazon S3.
my_datasets_folder = 's3://my-datasets-bucket'
Para obtener más información, consulte los documentos de datos personalizados.
¡Visite la documentación de SDGYM para obtener más información!

El proyecto de bóveda de datos sintéticos se creó por primera vez en los datos del MIT a AI Lab en 2016. Después de 4 años de investigación y tracción con Enterprise, creamos Datacebo en 2020 con el objetivo de hacer crecer el proyecto. Hoy, DataCebo es el orgulloso desarrollador de SDV, el ecosistema más grande para la generación y evaluación de datos sintéticos. Es el hogar de múltiples bibliotecas que admiten datos sintéticos, que incluyen:
Comience a usar el paquete SDV: una solución totalmente integrada y su ventanilla única para datos sintéticos. O use las bibliotecas independientes para necesidades específicas.


