SDGym
v0.9.1 - 2024-08-29
Dieses Repository ist Teil des Synthetic Data Vault Project, einem Projekt von DataCebo.

Das Synthetic Data Gym (SDGYM) ist ein Benchmarking -Framework zum Modellieren und Generieren von synthetischen Daten. Messen Sie die Leistung und den Speicherverbrauch für verschiedene synthetische Datenmodellierungstechniken - klassische Statistiken, Deep -Lernen und mehr!
Die SDGYM -Bibliothek integriert sich in das Ökosystem des synthetischen Datengeworfes. Sie können eine seiner Synthesizer, Datensätze oder Metriken zum Benchmarking verwenden. Sie können den Prozess auch an Ihre eigene Arbeit anpassen.
Installieren Sie SDGYM mit PIP oder Conda. Wir empfehlen, eine virtuelle Umgebung zu verwenden, um Konflikte mit anderer Software auf Ihrem Gerät zu vermeiden.
pip install sdgymconda install -c pytorch -c conda-forge sdgymWeitere Informationen zur Verwendung von SDGYM finden Sie in der SDGYM -Dokumentation.
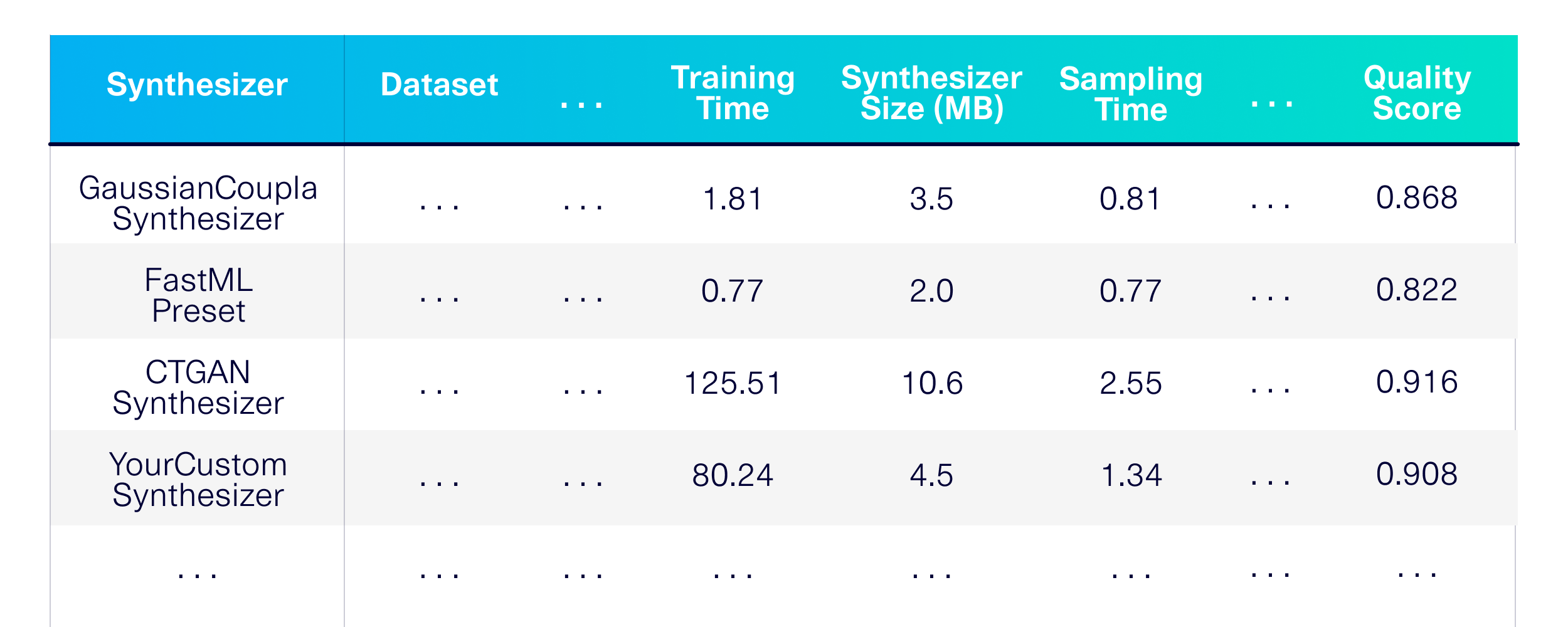
Lassen Sie uns die synthetische Datenerzeugung für einzelne Tabellen bewerten. Lassen Sie uns zunächst definieren, welche Modellierungstechniken wir verwenden möchten. Wählen wir einige Synthesizer aus der SDV -Bibliothek und einige andere als Baselines.
# these synthesizers come from the SDV library
# each one uses different modeling techniques
sdv_synthesizers = [ 'GaussianCopulaSynthesizer' , 'CTGANSynthesizer' ]
# these basic synthesizers are available in SDGym
# as baselines
baseline_synthesizers = [ 'UniformSynthesizer' ]Jetzt können wir die verschiedenen Techniken bewerten:
import sdgym
sdgym . benchmark_single_table (
synthesizers = ( sdv_synthesizers + baseline_synthesizers )
)Das Ergebnis ist eine detaillierte Leistung, Speicher und Qualitätsbewertung in den Synthesizern in einer Vielzahl von öffentlich verfügbaren Datensätzen.
Benchmarke Ihre eigenen Techniken zur Erzeugung von synthetischen Daten. Definieren Sie Ihren Synthesizer, indem Sie die Trainingslogik (mit maschinellem Lernen) und die Stichprobenlogik angeben.
def my_training_logic ( data , metadata ):
# create an object to represent your synthesizer
# train it using the data
return synthesizer
def my_sampling_logic ( trained_synthesizer , num_rows ):
# use the trained synthesizer to create
# num_rows of synthetic data
return synthetic_dataWeitere Informationen finden Sie im Handbuch für benutzerdefinierte Synthesizer.
Die SDGYM -Bibliothek enthält viele öffentlich verfügbare Datensätze, die Sie sofort aufnehmen können. Listen Sie diese mit der Funktion get_available_datasets auf.
sdgym . get_available_datasets () dataset_name size_MB num_tables
KRK_v1 0.072128 1
adult 3.907448 1
alarm 4.520128 1
asia 1.280128 1
...
Sie können auch alle benutzerdefinierten, privaten Datensätze aufnehmen, die auf Ihrem Computer auf einem Amazon S3 -Bucket gespeichert sind.
my_datasets_folder = 's3://my-datasets-bucket'
Weitere Informationen finden Sie in den Dokumenten für angepasste Datensätze.
Besuchen Sie die SDGYM -Dokumentation, um mehr zu erfahren!

Das Synthetic Data Vault -Projekt wurde erstmals 2016 an den Daten von MIT an AI Lab erstellt. Nach 4 Jahren Forschung und Traktion mit Enterprise haben wir 2020 Datacebo erstellt, um das Projekt auszubauen. Heute ist DataceBO der stolze Entwickler von SDV, dem größten Ökosystem für die Erzeugung und Bewertung der synthetischen Daten. Es ist die Heimat mehrerer Bibliotheken, die synthetische Daten unterstützen, einschließlich:
Beginnen Sie mit dem SDV-Paket-einer vollständig integrierten Lösung und Ihrem One-Stop-Shop für synthetische Daten. Oder verwenden Sie die eigenständigen Bibliotheken für bestimmte Anforderungen.


