ai00_server
v0.5.9

AI00 RWKV Server是基于web-rwkv推理引擎的RWKV语言模型的推理API服务器。
它支持Vulkan平行和并发批处理推理,并且可以在支持Vulkan的所有GPU上运行。不需要NVIDIA卡!!! AMD卡甚至集成的图形都可以加速!!!
无需笨重的pytorch , CUDA和其他运行时环境,它是紧凑的,可以开箱即用!
与OpenAI的Chatgpt API接口兼容。
根据麻省理工学院许可,100%开源和商业上可用。
如果您正在寻找快速,高效且易于使用的LLM API服务器,那么AI00 RWKV Server是您的最佳选择。它可用于各种任务,包括聊天机器人,文本生成,翻译和问答。
立即加入AI00 RWKV Server社区,并体验AI的魅力!
QQ Group for for Communication:30920262
RWKV模型,它具有高性能和准确性Vulkan推理加速度,您无需CUDA即可享受GPU加速度!支持AMD卡,集成图形和支持Vulkan所有GPUpytorch , CUDA和其他运行时环境,它是紧凑的,可以开箱即用!直接从发行版中下载最新版本
下载模型后,将模型放在assets/models/路径中,例如assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
可选地修改assets/configs/Config.toml用于模型配置,例如模型路径,量化层等。
在命令行中运行
$ ./ai00_rwkv_server打开浏览器,然后访问http:// localhost:65530(https:// localhost:65530),如果启用了tls ,则
安装生锈
克隆这个存储库
$ git clone https://github.com/cgisky1980/ai00_rwkv_server.git
$ cd ai00_rwkv_server下载模型后,将模型放在assets/models/路径中,例如assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
编译
$ cargo build --release汇编后,运行
$ cargo run --release打开浏览器,然后访问http:// localhost:65530(https:// localhost:65530),如果启用了tls )
它仅支持现在使用.st扩展名的Safetensors模型。使用使用火炬保存的.pth扩展名保存的模型需要在使用前转换。
下载.pth模型
(建议)运行Python脚本convert2ai00.py或convert_safetensors.py :
$ python ./convert2ai00.py --input /path/to/model.pth --output /path/to/model.st要求:Python,安装了torch和safetensors 。
如果您不想安装Python,则可以在版本中找到一个可执行的称为converter的可执行文件。跑步
$ ./converter --input /path/to/model.pth --output /path/to/model.st$ cargo run --release --package converter -- --input /path/to/model.pth --output /path/to/model.st.st模型中的assets/models/路径中,并修改assets/configs/Config.toml中的模型路径--config :配置文件路径(默认: assets/configs/Config.toml )--ip :IP地址服务器绑定到--port :运行端口 API服务从端口65530开始,数据输入和输出格式遵循OpenAI API规范。请注意,某些API(例如chat和completions具有用于高级功能的其他可选字段。请访问http:// localhost:65530/API-DOCS用于API模式。
/api/oai/v1/models/api/oai/models/api/oai/v1/chat/completions/api/oai/chat/completions/api/oai/v1/completions/api/oai/completions/api/oai/v1/embeddings/api/oai/embeddings以下是python中AI00 API调用的盒子外示例:
import openai
class Ai00 :
def __init__ ( self , model = "model" , port = 65530 , api_key = "JUSTSECRET_KEY" ) :
openai . api_base = f"http://127.0.0.1: { port } /api/oai"
openai . api_key = api_key
self . ctx = []
self . params = {
"system_name" : "System" ,
"user_name" : "User" ,
"assistant_name" : "Assistant" ,
"model" : model ,
"max_tokens" : 4096 ,
"top_p" : 0.6 ,
"temperature" : 1 ,
"presence_penalty" : 0.3 ,
"frequency_penalty" : 0.3 ,
"half_life" : 400 ,
"stop" : [ ' x00 ' , ' n n ' ]
}
def set_params ( self , ** kwargs ):
self . params . update ( kwargs )
def clear_ctx ( self ):
self . ctx = []
def get_ctx ( self ):
return self . ctx
def continuation ( self , message ):
response = openai . Completion . create (
model = self . params [ 'model' ],
prompt = message ,
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = response . choices [ 0 ]. text
return result
def append_ctx ( self , role , content ):
self . ctx . append ({
"role" : role ,
"content" : content
})
def send_message ( self , message , role = "user" ):
self . ctx . append ({
"role" : role ,
"content" : message
})
result = openai . ChatCompletion . create (
model = self . params [ 'model' ],
messages = self . ctx ,
names = {
"system" : self . params [ 'system_name' ],
"user" : self . params [ 'user_name' ],
"assistant" : self . params [ 'assistant_name' ]
},
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = result . choices [ 0 ]. message [ 'content' ]
self . ctx . append ({
"role" : "assistant" ,
"content" : result
})
return result
ai00 = Ai00 ()
ai00 . set_params (
max_tokens = 4096 ,
top_p = 0.55 ,
temperature = 2 ,
presence_penalty = 0.3 ,
frequency_penalty = 0.8 ,
half_life = 400 ,
stop = [ ' x00 ' , ' n n ' ]
)
print ( ai00 . send_message ( "how are you?" ))
print ( ai00 . send_message ( "me too!" ))
print ( ai00 . get_ctx ())
ai00 . clear_ctx ()
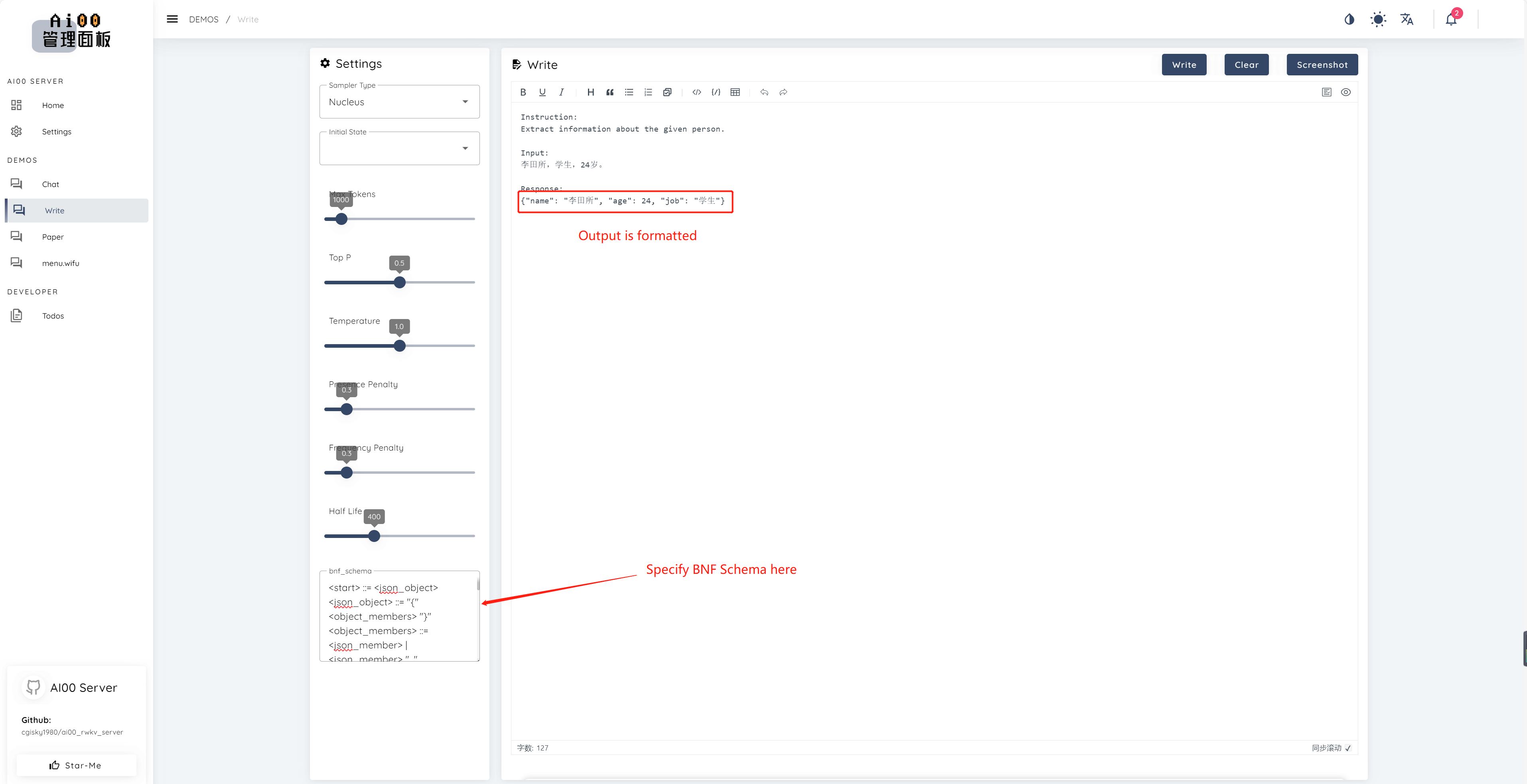
print ( ai00 . continuation ( "i like" ))自V0.5以来,AI00具有称为BNF采样的独特功能。 BNF通过限制模型可以选择的近隔壁的标记来迫使模型以指定格式输出(例如JSON或MARKDOWN)。
这是带有字段“名称”,“年龄”和“ Job”的JSON的示例BNF:
<start> ::= <json_object>
<json_object> ::= "{" <object_members> "}"
<object_members> ::= <json_member> | <json_member> ", " <object_members>
<json_member> ::= <json_key> ": " <json_value>
<json_key> ::= '"' "name" '"' | '"' "age" '"' | '"' "job" '"'
<json_value> ::= <json_string> | <json_number>
<json_string>::='"'<content>'"'
<content>::=<except!([escaped_literals])>|<except!([escaped_literals])><content>|'\"'<content>|'\"'
<escaped_literals>::='t'|'n'|'r'|'"'
<json_number> ::= <positive_digit><digits>|'0'
<digits>::=<digit>|<digit><digits>
<digit>::='0'|<positive_digit>
<positive_digit>::="1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"
text_completions和chat_completions batch serve平行推断int8量化NF4量化LoRA模型LoRA模型的热负载和切换我们一直在寻找有兴趣帮助我们改善项目的人。如果您对以下任何一项感兴趣,请加入我们!
无论您的技能水平如何,我们都欢迎您加入我们。您可以通过以下方式加入我们:
我们迫不及待地想与您合作,使这个项目变得更好!我们希望该项目对您有帮助!
感谢这些令人敬畏的人,他们对该项目的支持和无私的奉献精神!
顾真牛 ? ? ?? | 研究社交 ? ? ? ? | JOSC146 ? ? ? | L15y ? ? | 卡希亚·维拉旺(Cahya Wirawan) ? | yuunnn_w | 朗祖 ?️ |
luoqiqi |


