ai00_server
v0.5.9

AI00 RWKV Server adalah server API inferensi untuk model bahasa RWKV berdasarkan mesin inferensi web-rwkv .
Ini mendukung Vulkan paralel dan inferensi batched bersamaan dan dapat menjalankan semua GPU yang mendukung Vulkan . Tidak perlu kartu nvidia !!! Kartu AMD dan bahkan grafik terintegrasi dapat dipercepat !!!
Tidak perlu untuk pytorch besar, CUDA dan lingkungan runtime lainnya, itu kompak dan siap digunakan di luar kotak!
Kompatibel dengan antarmuka API chatgpt openai.
100% open source dan dapat digunakan secara komersial, di bawah lisensi MIT.
Jika Anda mencari server API LLM yang cepat, efisien, dan mudah digunakan, maka AI00 RWKV Server adalah pilihan terbaik Anda. Ini dapat digunakan untuk berbagai tugas, termasuk chatbots, generasi teks, terjemahan, dan tanya jawab.
Bergabunglah dengan komunitas AI00 RWKV Server sekarang dan alami pesona AI!
QQ Group for Communication: 30920262
RWKV , memiliki kinerja dan akurasi tinggiVulkan , Anda dapat menikmati akselerasi GPU tanpa perlu CUDA ! Mendukung kartu AMD, grafik terintegrasi, dan semua GPU yang mendukung Vulkanpytorch besar, CUDA dan lingkungan runtime lainnya, itu kompak dan siap digunakan di luar kotak!Langsung Unduh Versi Terbaru Dari Rilis
Setelah mengunduh model, tempatkan model dalam assets/models/ jalur, misalnya, assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Secara opsional memodifikasi assets/configs/Config.toml untuk konfigurasi model seperti jalur model, lapisan kuantisasi, dll.
Jalankan di baris perintah
$ ./ai00_rwkv_server Buka browser dan kunjungi webui di http: // localhost: 65530 (https: // localhost: 65530 jika tls diaktifkan)
Pasang karat
Kloning repositori ini
$ git clone https://github.com/cgisky1980/ai00_rwkv_server.git
$ cd ai00_rwkv_server Setelah mengunduh model, tempatkan model dalam assets/models/ jalur, misalnya, assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Menyusun
$ cargo build --releaseSetelah kompilasi, jalankan
$ cargo run --release Buka browser dan kunjungi webui di http: // localhost: 65530 (https: // localhost: 65530 jika tls diaktifkan)
Ini hanya mendukung model Safetensors dengan ekstensi .st sekarang. Model disimpan dengan ekstensi .pth menggunakan obor perlu dikonversi sebelum digunakan.
Unduh model .pth
(Disarankan) Jalankan skrip python convert2ai00.py atau convert_safetensors.py :
$ python ./convert2ai00.py --input /path/to/model.pth --output /path/to/model.st Persyaratan: Python, dengan torch dan safetensors terpasang.
Jika Anda tidak ingin menginstal Python, dalam rilis, Anda dapat menemukan converter yang dapat dieksekusi. Berlari
$ ./converter --input /path/to/model.pth --output /path/to/model.st$ cargo run --release --package converter -- --input /path/to/model.pth --output /path/to/model.st.st dalam assets/models/ path dan ubah jalur model dalam assets/configs/Config.toml --config : Konfigurasi jalur file (default: assets/configs/Config.toml )--ip : Alamat IP yang terikat pada server--port : Port menjalankan Layanan API dimulai pada port 65530, dan format input dan output data mengikuti spesifikasi API OpenAI. Perhatikan bahwa beberapa API seperti chat dan completions memiliki bidang opsional tambahan untuk fungsionalitas lanjutan. Kunjungi http: // localhost: 65530/API-docs untuk skema API.
/api/oai/v1/models/api/oai/models/api/oai/v1/chat/completions/api/oai/chat/completions/api/oai/v1/completions/api/oai/completions/api/oai/v1/embeddings/api/oai/embeddingsBerikut ini adalah contoh out-of-box dari AI00 API Invocation di Python:
import openai
class Ai00 :
def __init__ ( self , model = "model" , port = 65530 , api_key = "JUSTSECRET_KEY" ) :
openai . api_base = f"http://127.0.0.1: { port } /api/oai"
openai . api_key = api_key
self . ctx = []
self . params = {
"system_name" : "System" ,
"user_name" : "User" ,
"assistant_name" : "Assistant" ,
"model" : model ,
"max_tokens" : 4096 ,
"top_p" : 0.6 ,
"temperature" : 1 ,
"presence_penalty" : 0.3 ,
"frequency_penalty" : 0.3 ,
"half_life" : 400 ,
"stop" : [ ' x00 ' , ' n n ' ]
}
def set_params ( self , ** kwargs ):
self . params . update ( kwargs )
def clear_ctx ( self ):
self . ctx = []
def get_ctx ( self ):
return self . ctx
def continuation ( self , message ):
response = openai . Completion . create (
model = self . params [ 'model' ],
prompt = message ,
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = response . choices [ 0 ]. text
return result
def append_ctx ( self , role , content ):
self . ctx . append ({
"role" : role ,
"content" : content
})
def send_message ( self , message , role = "user" ):
self . ctx . append ({
"role" : role ,
"content" : message
})
result = openai . ChatCompletion . create (
model = self . params [ 'model' ],
messages = self . ctx ,
names = {
"system" : self . params [ 'system_name' ],
"user" : self . params [ 'user_name' ],
"assistant" : self . params [ 'assistant_name' ]
},
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = result . choices [ 0 ]. message [ 'content' ]
self . ctx . append ({
"role" : "assistant" ,
"content" : result
})
return result
ai00 = Ai00 ()
ai00 . set_params (
max_tokens = 4096 ,
top_p = 0.55 ,
temperature = 2 ,
presence_penalty = 0.3 ,
frequency_penalty = 0.8 ,
half_life = 400 ,
stop = [ ' x00 ' , ' n n ' ]
)
print ( ai00 . send_message ( "how are you?" ))
print ( ai00 . send_message ( "me too!" ))
print ( ai00 . get_ctx ())
ai00 . clear_ctx ()
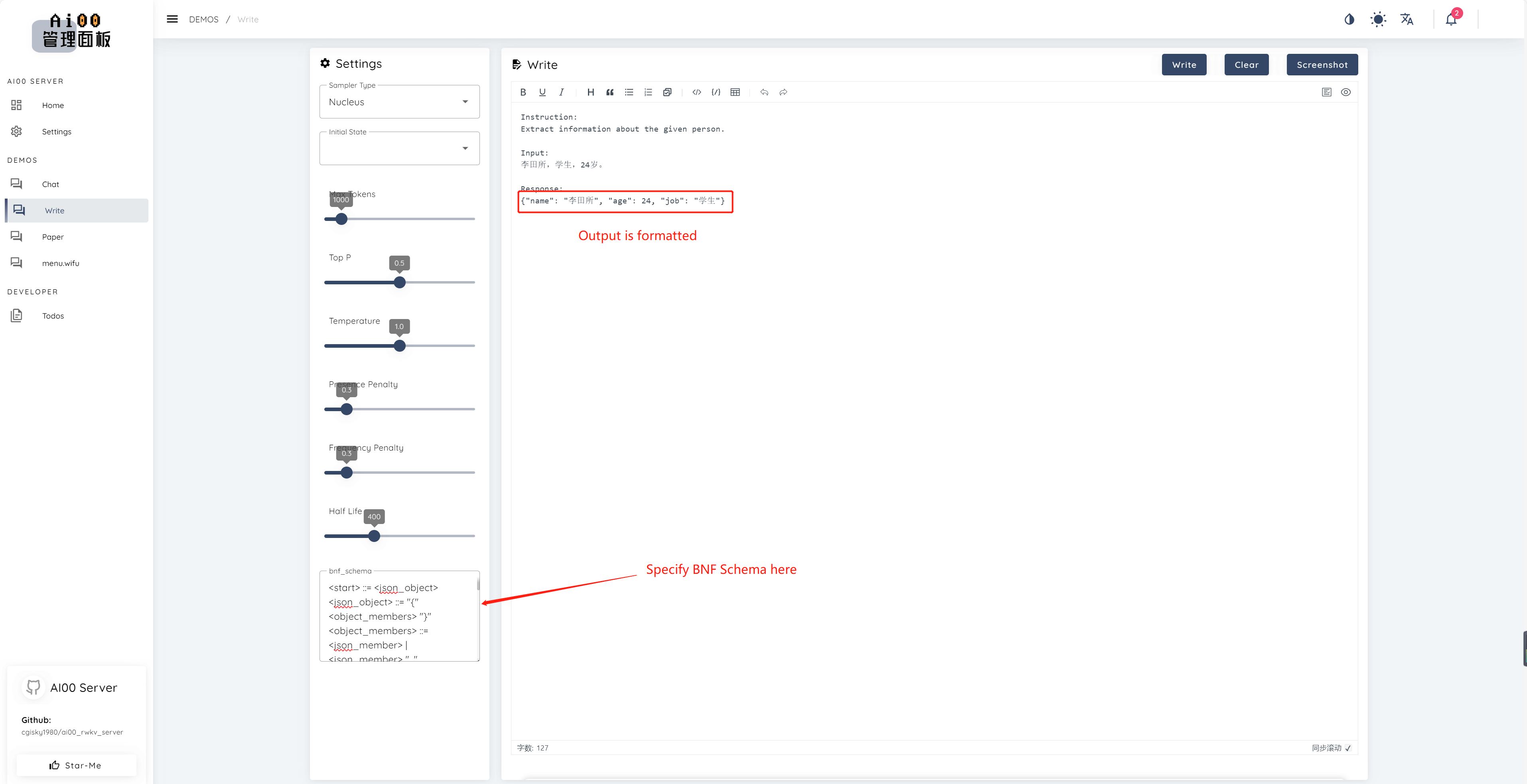
print ( ai00 . continuation ( "i like" ))Sejak v0.5, AI00 memiliki fitur unik yang disebut BNF Sampling. BNF memaksa model untuk output dalam format yang ditentukan (misalnya JSON atau Markdown dengan bidang yang ditentukan) dengan membatasi kemungkinan token di sebelah yang dapat dipilih oleh model.
Berikut adalah contoh BNF untuk JSON dengan Fields "Name", "Age" dan "Job":
<start> ::= <json_object>
<json_object> ::= "{" <object_members> "}"
<object_members> ::= <json_member> | <json_member> ", " <object_members>
<json_member> ::= <json_key> ": " <json_value>
<json_key> ::= '"' "name" '"' | '"' "age" '"' | '"' "job" '"'
<json_value> ::= <json_string> | <json_number>
<json_string>::='"'<content>'"'
<content>::=<except!([escaped_literals])>|<except!([escaped_literals])><content>|'\"'<content>|'\"'
<escaped_literals>::='t'|'n'|'r'|'"'
<json_number> ::= <positive_digit><digits>|'0'
<digits>::=<digit>|<digit><digits>
<digit>::='0'|<positive_digit>
<positive_digit>::="1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"
text_completions dan chat_completions batch serve int8 NF4 LoRA LoRA Kami selalu mencari orang yang tertarik untuk membantu kami meningkatkan proyek. Jika Anda tertarik dengan hal -hal berikut, silakan bergabung dengan kami!
Tidak peduli tingkat keterampilan Anda, kami menyambut Anda untuk bergabung dengan kami. Anda dapat bergabung dengan kami dengan cara berikut:
Kami tidak sabar untuk bekerja dengan Anda untuk membuat proyek ini lebih baik! Kami berharap proyek ini bermanfaat bagi Anda!
Terima kasih kepada orang -orang luar biasa ini yang berwawasan luas dan luar biasa atas dukungan mereka dan dedikasi tanpa pamrih untuk proyek ini!
顾真牛 ? ? ? ? | 研究社交 ? ? ? ? | josc146 ? ? ? | l15y ? ? | Cahya Wirawan ? | yuunnn_w | Longzou ? ️ |
Luoqiqi |


