ai00_server
v0.5.9

AI00 RWKV Server es un servidor API de inferencia para el modelo de idioma RWKV basado en el motor de inferencia web-rwkv .
Apoya la inferencia de Vulkan paralelo y lotes concurrentes y puede ejecutarse en todas las GPU que respaldan Vulkan . ¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡¡Oso ¡!!! ¡Se pueden acelerar las tarjetas AMD e incluso los gráficos integrados!
¡No hay necesidad de pytorch voluminoso, CUDA y otros entornos de tiempo de ejecución, es compacto y listo para usar fuera de la caja!
Compatible con la interfaz API CHATGPT de Openai.
Corriente 100% abierta y comercialmente utilizable, bajo la licencia MIT.
Si está buscando un servidor LLM API rápido, eficiente y fácil de usar, entonces AI00 RWKV Server es su mejor opción. Se puede utilizar para varias tareas, incluidos chatbots, generación de texto, traducción y preguntas y respuestas.
¡Únase a la comunidad AI00 RWKV Server ahora y experimente el encanto de la IA!
Grupo QQ para la comunicación: 30920262
RWKV , tiene un alto rendimiento y precisiónVulkan , ¡puede disfrutar de la aceleración de GPU sin la necesidad de CUDA ! Admite tarjetas AMD, gráficos integrados y todas las GPU que admiten Vulkanpytorch voluminoso, CUDA y otros entornos de tiempo de ejecución, es compacto y listo para usar fuera de la caja!Descargue directamente la última versión del lanzamiento
Después de descargar el modelo, coloque el modelo en los assets/models/ ruta, por ejemplo, assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Opcionalmente, modifique assets/configs/Config.toml para configuraciones del modelo como ruta del modelo, capas de cuantización, etc.
Ejecutar en la línea de comando
$ ./ai00_rwkv_server Abra el navegador y visite el webui en http: // localhost: 65530 (https: // localhost: 65530 si tls está habilitado)
Instalar óxido
Clon este repositorio
$ git clone https://github.com/cgisky1980/ai00_rwkv_server.git
$ cd ai00_rwkv_server Después de descargar el modelo, coloque el modelo en los assets/models/ ruta, por ejemplo, assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Compilar
$ cargo build --releaseDespués de la compilación, ejecute
$ cargo run --release Abra el navegador y visite el webui en http: // localhost: 65530 (https: // localhost: 65530 si tls está habilitado)
Solo admite modelos Safetensors con la extensión .st ahora. Los modelos guardados con la extensión .pth con antorcha deben convertirse antes de su uso.
Descargue el modelo .pth
(Recomendado) Ejecute el script Python convert2ai00.py o convert_safetensors.py :
$ python ./convert2ai00.py --input /path/to/model.pth --output /path/to/model.st Requisitos: Python, con torch y safetensors instalados.
Si no desea instalar Python, en la versión puede encontrar un ejecutable llamado converter . Correr
$ ./converter --input /path/to/model.pth --output /path/to/model.st$ cargo run --release --package converter -- --input /path/to/model.pth --output /path/to/model.st.st en los assets/models/ ruta y modifique la ruta del modelo en assets/configs/Config.toml --config : Configurar la ruta del archivo (predeterminado: assets/configs/Config.toml )--ip : la dirección IP del servidor está vinculado a--port : en ejecución del puerto El servicio API comienza en el puerto 65530, y el formato de entrada y salida de datos sigue la especificación de API de OpenAI. Tenga en cuenta que algunas API como chat y completions tienen campos opcionales adicionales para funcionalidades avanzadas. Visite http: // localhost: 65530/API-DOCS para el esquema API.
/api/oai/v1/models/api/oai/models/api/oai/v1/chat/completions/api/oai/chat/completions/api/oai/v1/completions/api/oai/completions/api/oai/v1/embeddings/api/oai/embeddingsEl siguiente es un ejemplo fuera de caja de invocaciones de API AI00 en Python:
import openai
class Ai00 :
def __init__ ( self , model = "model" , port = 65530 , api_key = "JUSTSECRET_KEY" ) :
openai . api_base = f"http://127.0.0.1: { port } /api/oai"
openai . api_key = api_key
self . ctx = []
self . params = {
"system_name" : "System" ,
"user_name" : "User" ,
"assistant_name" : "Assistant" ,
"model" : model ,
"max_tokens" : 4096 ,
"top_p" : 0.6 ,
"temperature" : 1 ,
"presence_penalty" : 0.3 ,
"frequency_penalty" : 0.3 ,
"half_life" : 400 ,
"stop" : [ ' x00 ' , ' n n ' ]
}
def set_params ( self , ** kwargs ):
self . params . update ( kwargs )
def clear_ctx ( self ):
self . ctx = []
def get_ctx ( self ):
return self . ctx
def continuation ( self , message ):
response = openai . Completion . create (
model = self . params [ 'model' ],
prompt = message ,
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = response . choices [ 0 ]. text
return result
def append_ctx ( self , role , content ):
self . ctx . append ({
"role" : role ,
"content" : content
})
def send_message ( self , message , role = "user" ):
self . ctx . append ({
"role" : role ,
"content" : message
})
result = openai . ChatCompletion . create (
model = self . params [ 'model' ],
messages = self . ctx ,
names = {
"system" : self . params [ 'system_name' ],
"user" : self . params [ 'user_name' ],
"assistant" : self . params [ 'assistant_name' ]
},
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = result . choices [ 0 ]. message [ 'content' ]
self . ctx . append ({
"role" : "assistant" ,
"content" : result
})
return result
ai00 = Ai00 ()
ai00 . set_params (
max_tokens = 4096 ,
top_p = 0.55 ,
temperature = 2 ,
presence_penalty = 0.3 ,
frequency_penalty = 0.8 ,
half_life = 400 ,
stop = [ ' x00 ' , ' n n ' ]
)
print ( ai00 . send_message ( "how are you?" ))
print ( ai00 . send_message ( "me too!" ))
print ( ai00 . get_ctx ())
ai00 . clear_ctx ()
print ( ai00 . continuation ( "i like" ))Desde V0.5, AI00 tiene una característica única llamada BNF Sampling. BNF obliga al modelo a emitir en formatos especificados (p. Ej., JSON o Markdown con campos especificados) limitando las siguientes tokens posibles que el modelo puede elegir.
Aquí hay un ejemplo de BNF para JSON con los campos "nombre", "edad" y "trabajo":
<start> ::= <json_object>
<json_object> ::= "{" <object_members> "}"
<object_members> ::= <json_member> | <json_member> ", " <object_members>
<json_member> ::= <json_key> ": " <json_value>
<json_key> ::= '"' "name" '"' | '"' "age" '"' | '"' "job" '"'
<json_value> ::= <json_string> | <json_number>
<json_string>::='"'<content>'"'
<content>::=<except!([escaped_literals])>|<except!([escaped_literals])><content>|'\"'<content>|'\"'
<escaped_literals>::='t'|'n'|'r'|'"'
<json_number> ::= <positive_digit><digits>|'0'
<digits>::=<digit>|<digit><digits>
<digit>::='0'|<positive_digit>
<positive_digit>::="1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"
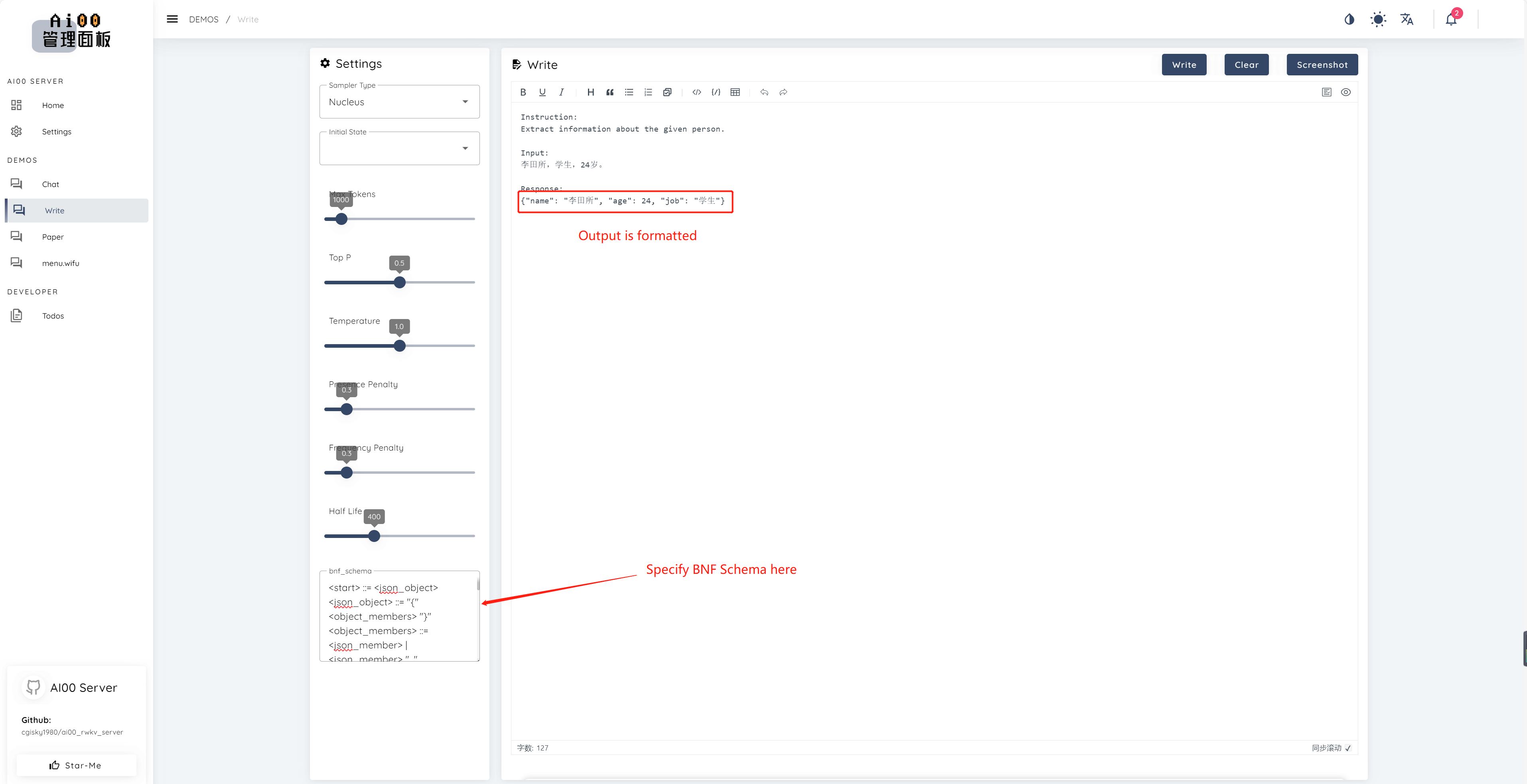
text_completions y chat_completions batch serve int8 NF4 LoRA LoRA Siempre estamos buscando personas interesadas en ayudarnos a mejorar el proyecto. Si está interesado en cualquiera de los siguientes, ¡únase a nosotros!
No importa su nivel de habilidad, le damos la bienvenida para que se una a nosotros. Puedes unirte a nosotros de las siguientes maneras:
¡No podemos esperar a trabajar con usted para mejorar este proyecto! ¡Esperamos que el proyecto te sea útil!
¡Gracias a estas increíbles personas que son perspicaces y sobresalientes por su apoyo y dedicación desinteresada al proyecto!
顾真牛 ? ? ? ? | 研究社交 ? ? ? ? | josc146 ? ? ? | L15Y ? ? | Cahya Wirawan ? | yuunnn_w | longzou ? ️ |
luoqiqi |


