ai00_server
v0.5.9

AI00 RWKV Server เป็นเซิร์ฟเวอร์ API การอนุมานสำหรับรุ่นภาษา RWKV ตามเอ็นจิ้นการอนุมาน web-rwkv
รองรับการอนุมานแบบคู่ Vulkan และพร้อมกันและสามารถทำงานบน GPU ทั้งหมดที่รองรับ Vulkan ไม่จำเป็นต้องใช้การ์ด Nvidia !!! การ์ด AMD และแม้กระทั่งกราฟิกแบบรวมสามารถเร่งได้ !!!
ไม่จำเป็นต้องมี pytorch ขนาดใหญ่ CUDA และสภาพแวดล้อมรันไทม์อื่น ๆ มันมีขนาดกะทัดรัดและพร้อมที่จะใช้นอกกรอบ!
เข้ากันได้กับอินเทอร์เฟซ CHATGPT API ของ OpenAI
โอเพ่นซอร์ส 100% และใช้งานได้ในเชิงพาณิชย์ภายใต้ใบอนุญาต MIT
หากคุณกำลังมองหาเซิร์ฟเวอร์ LLM API ที่รวดเร็วมีประสิทธิภาพและง่ายต่อการใช้งาน AI00 RWKV Server เป็นตัวเลือกที่ดีที่สุดของคุณ มันสามารถใช้สำหรับงานต่าง ๆ รวมถึง chatbots การสร้างข้อความการแปลและคำถาม & คำตอบ
เข้าร่วมชุมชน AI00 RWKV Server ตอนนี้และสัมผัสกับเสน่ห์ของ AI!
กลุ่ม QQ สำหรับการสื่อสาร: 30920262
RWKV มีประสิทธิภาพและความแม่นยำสูงVulkan คุณสามารถเพลิดเพลินกับการเร่งความเร็วของ GPU โดยไม่จำเป็นต้องใช้ CUDA ! รองรับการ์ด AMD กราฟิกแบบรวมและ GPU ทั้งหมดที่รองรับ Vulkanpytorch ขนาดใหญ่ CUDA และสภาพแวดล้อมรันไทม์อื่น ๆ มันมีขนาดกะทัดรัดและพร้อมที่จะใช้นอกกรอบ!ดาวน์โหลดเวอร์ชันล่าสุดโดยตรงจากรีลีส
หลังจากดาวน์โหลดโมเดลวางโมเดลใน assets/models/ พา ธ ตัวอย่างเช่น assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
เลือกแก้ไข assets/configs/Config.toml สำหรับการกำหนดค่ารุ่นเช่นพา ธ รุ่น, เลเยอร์เชิงปริมาณ ฯลฯ
รันในบรรทัดคำสั่ง
$ ./ai00_rwkv_server เปิดเบราว์เซอร์และเยี่ยมชม webui ที่ http: // localhost: 65530 (https: // localhost: 65530 ถ้าเปิดใช้งาน tls )
ติดตั้ง Rust
โคลนที่เก็บนี้
$ git clone https://github.com/cgisky1980/ai00_rwkv_server.git
$ cd ai00_rwkv_server หลังจากดาวน์โหลดโมเดลวางโมเดลใน assets/models/ พา ธ ตัวอย่างเช่น assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
รวบรวม
$ cargo build --releaseหลังจากการรวบรวมแล้วรัน
$ cargo run --release เปิดเบราว์เซอร์และเยี่ยมชม webui ที่ http: // localhost: 65530 (https: // localhost: 65530 ถ้าเปิดใช้งาน tls )
รองรับรุ่น Safetensors เท่านั้นที่มีส่วนขยาย .st โมเดลที่บันทึกด้วยส่วนขยาย .pth โดยใช้คบเพลิงจะต้องถูกแปลงก่อนการใช้งาน
ดาวน์โหลด .pth model
(แนะนำ) เรียกใช้ Python Script convert2ai00.py หรือ convert_safetensors.py :
$ python ./convert2ai00.py --input /path/to/model.pth --output /path/to/model.st ข้อกำหนด: Python โดยติดตั้ง torch และ safetensors
หากคุณไม่ต้องการติดตั้ง Python ในการเปิดตัวคุณสามารถหาเครื่องแปลงที่เรียกว่า converter ได้ วิ่ง
$ ./converter --input /path/to/model.pth --output /path/to/model.st$ cargo run --release --package converter -- --input /path/to/model.pth --output /path/to/model.st.st ใน assets/models/ พา ธ และแก้ไขพา ธ โมเดลใน assets/configs/Config.toml --config : กำหนดค่าพา ธ ไฟล์ (ค่าเริ่มต้น: assets/configs/Config.toml )--ip : ที่อยู่ IP ที่เซิร์ฟเวอร์ถูกผูกไว้--port : พอร์ตเรียกใช้ บริการ API เริ่มต้นที่พอร์ต 65530 และรูปแบบอินพุตและรูปแบบเอาต์พุตตามข้อกำหนดของ OpenAI API โปรดทราบว่า API บางตัวเช่น chat และ completions มีฟิลด์เสริมเพิ่มเติมสำหรับฟังก์ชันการทำงานขั้นสูง เยี่ยมชม http: // localhost: 65530/api-docs สำหรับ API schema
/api/oai/v1/models/api/oai/models/api/oai/v1/chat/completions/api/oai/chat/completions/api/oai/v1/completions/api/oai/completions/api/oai/v1/embeddings/api/oai/embeddingsต่อไปนี้เป็นตัวอย่างนอกกรอบของการเรียกใช้ AI00 API ใน Python:
import openai
class Ai00 :
def __init__ ( self , model = "model" , port = 65530 , api_key = "JUSTSECRET_KEY" ) :
openai . api_base = f"http://127.0.0.1: { port } /api/oai"
openai . api_key = api_key
self . ctx = []
self . params = {
"system_name" : "System" ,
"user_name" : "User" ,
"assistant_name" : "Assistant" ,
"model" : model ,
"max_tokens" : 4096 ,
"top_p" : 0.6 ,
"temperature" : 1 ,
"presence_penalty" : 0.3 ,
"frequency_penalty" : 0.3 ,
"half_life" : 400 ,
"stop" : [ ' x00 ' , ' n n ' ]
}
def set_params ( self , ** kwargs ):
self . params . update ( kwargs )
def clear_ctx ( self ):
self . ctx = []
def get_ctx ( self ):
return self . ctx
def continuation ( self , message ):
response = openai . Completion . create (
model = self . params [ 'model' ],
prompt = message ,
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = response . choices [ 0 ]. text
return result
def append_ctx ( self , role , content ):
self . ctx . append ({
"role" : role ,
"content" : content
})
def send_message ( self , message , role = "user" ):
self . ctx . append ({
"role" : role ,
"content" : message
})
result = openai . ChatCompletion . create (
model = self . params [ 'model' ],
messages = self . ctx ,
names = {
"system" : self . params [ 'system_name' ],
"user" : self . params [ 'user_name' ],
"assistant" : self . params [ 'assistant_name' ]
},
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = result . choices [ 0 ]. message [ 'content' ]
self . ctx . append ({
"role" : "assistant" ,
"content" : result
})
return result
ai00 = Ai00 ()
ai00 . set_params (
max_tokens = 4096 ,
top_p = 0.55 ,
temperature = 2 ,
presence_penalty = 0.3 ,
frequency_penalty = 0.8 ,
half_life = 400 ,
stop = [ ' x00 ' , ' n n ' ]
)
print ( ai00 . send_message ( "how are you?" ))
print ( ai00 . send_message ( "me too!" ))
print ( ai00 . get_ctx ())
ai00 . clear_ctx ()
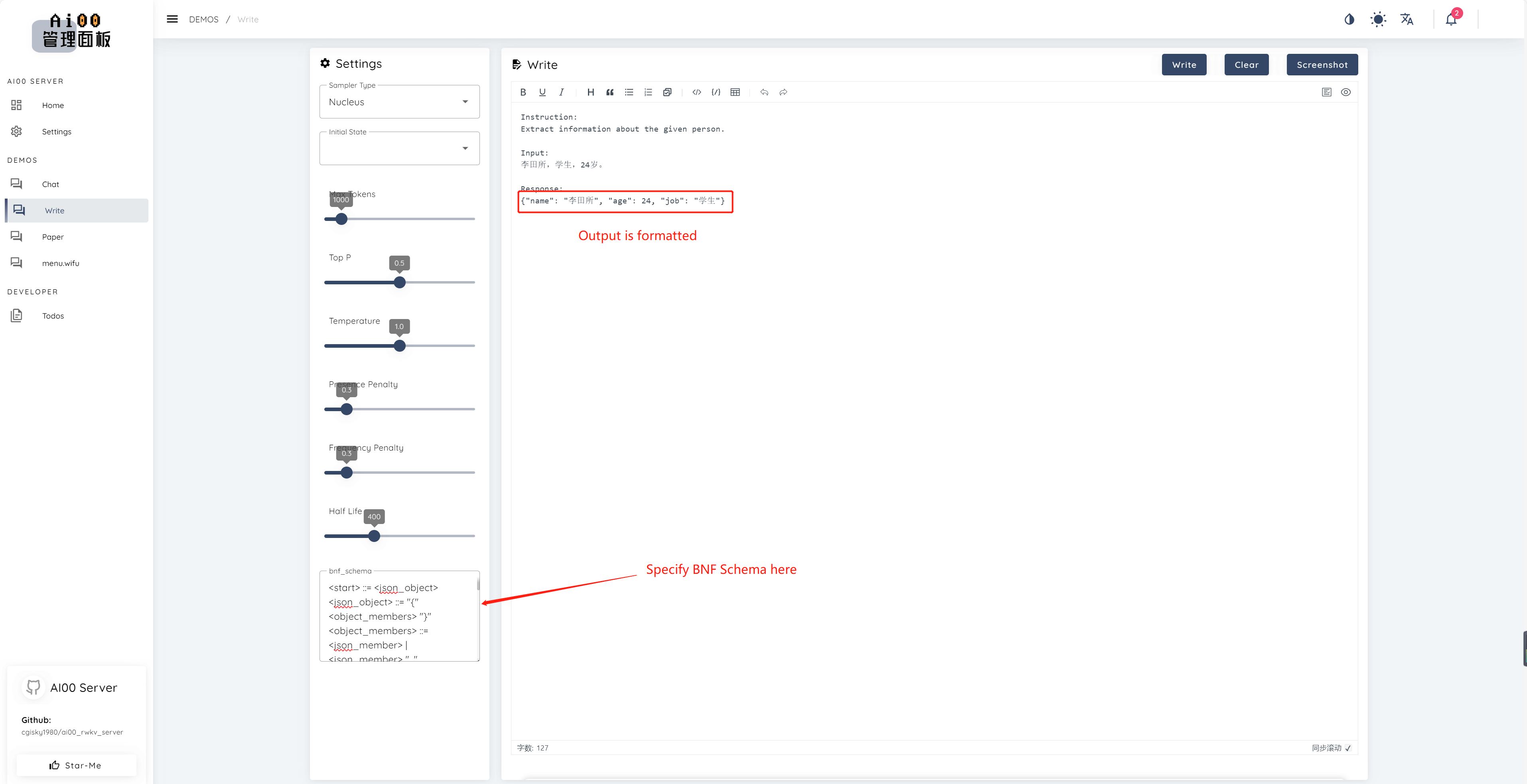
print ( ai00 . continuation ( "i like" ))ตั้งแต่ V0.5 AI00 มีคุณสมบัติที่เป็นเอกลักษณ์ที่เรียกว่าการสุ่มตัวอย่าง BNF BNF บังคับให้โมเดลส่งออกในรูปแบบที่ระบุ (เช่น JSON หรือ Markdown ด้วยฟิลด์ที่ระบุ) โดยการ จำกัด โทเค็นถัดไปที่เป็นไปได้ที่โมเดลสามารถเลือกได้
นี่คือตัวอย่าง BNF สำหรับ JSON ที่มีฟิลด์ "ชื่อ", "อายุ" และ "งาน":
<start> ::= <json_object>
<json_object> ::= "{" <object_members> "}"
<object_members> ::= <json_member> | <json_member> ", " <object_members>
<json_member> ::= <json_key> ": " <json_value>
<json_key> ::= '"' "name" '"' | '"' "age" '"' | '"' "job" '"'
<json_value> ::= <json_string> | <json_number>
<json_string>::='"'<content>'"'
<content>::=<except!([escaped_literals])>|<except!([escaped_literals])><content>|'\"'<content>|'\"'
<escaped_literals>::='t'|'n'|'r'|'"'
<json_number> ::= <positive_digit><digits>|'0'
<digits>::=<digit>|<digit><digits>
<digit>::='0'|<positive_digit>
<positive_digit>::="1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"
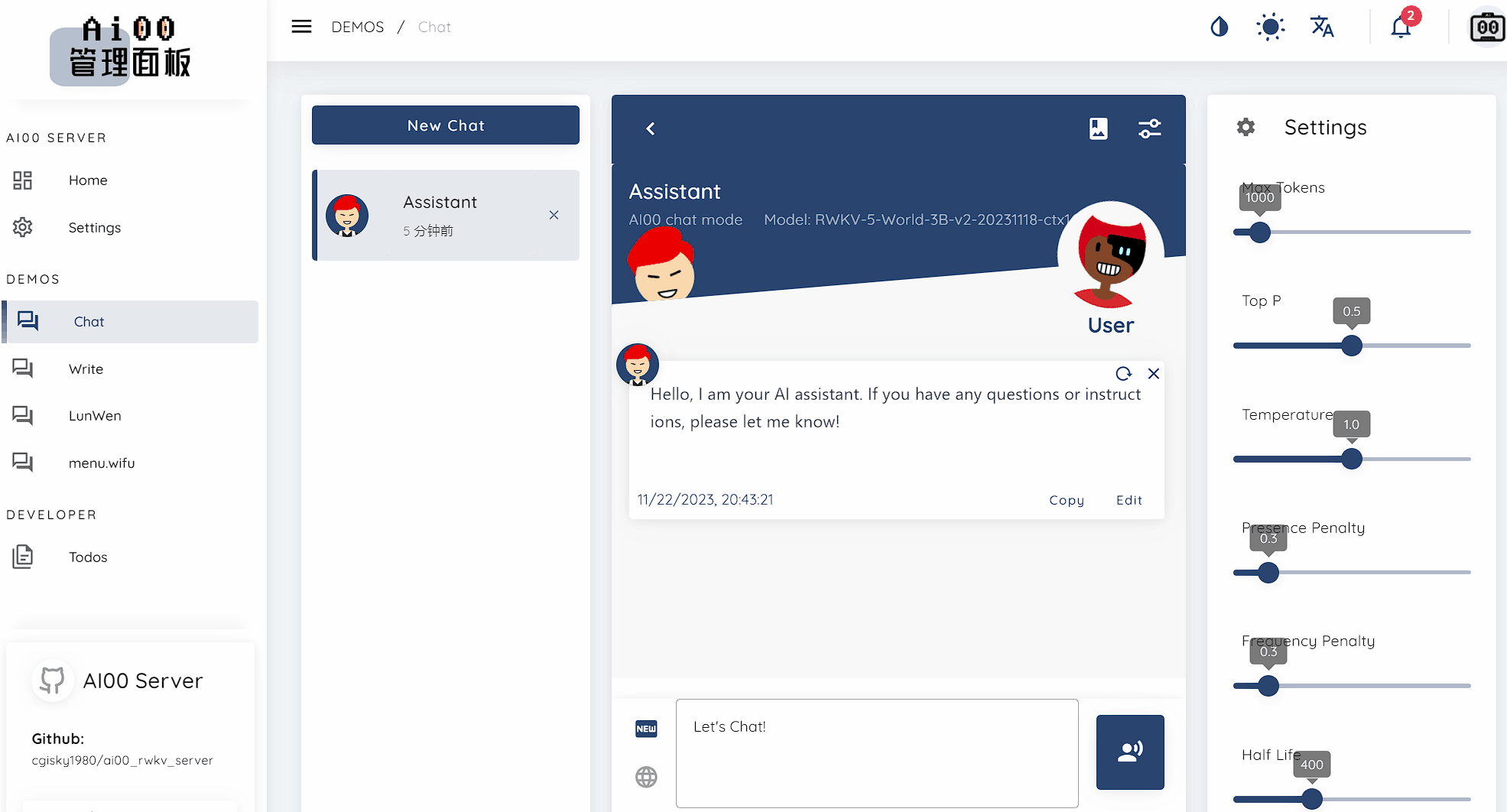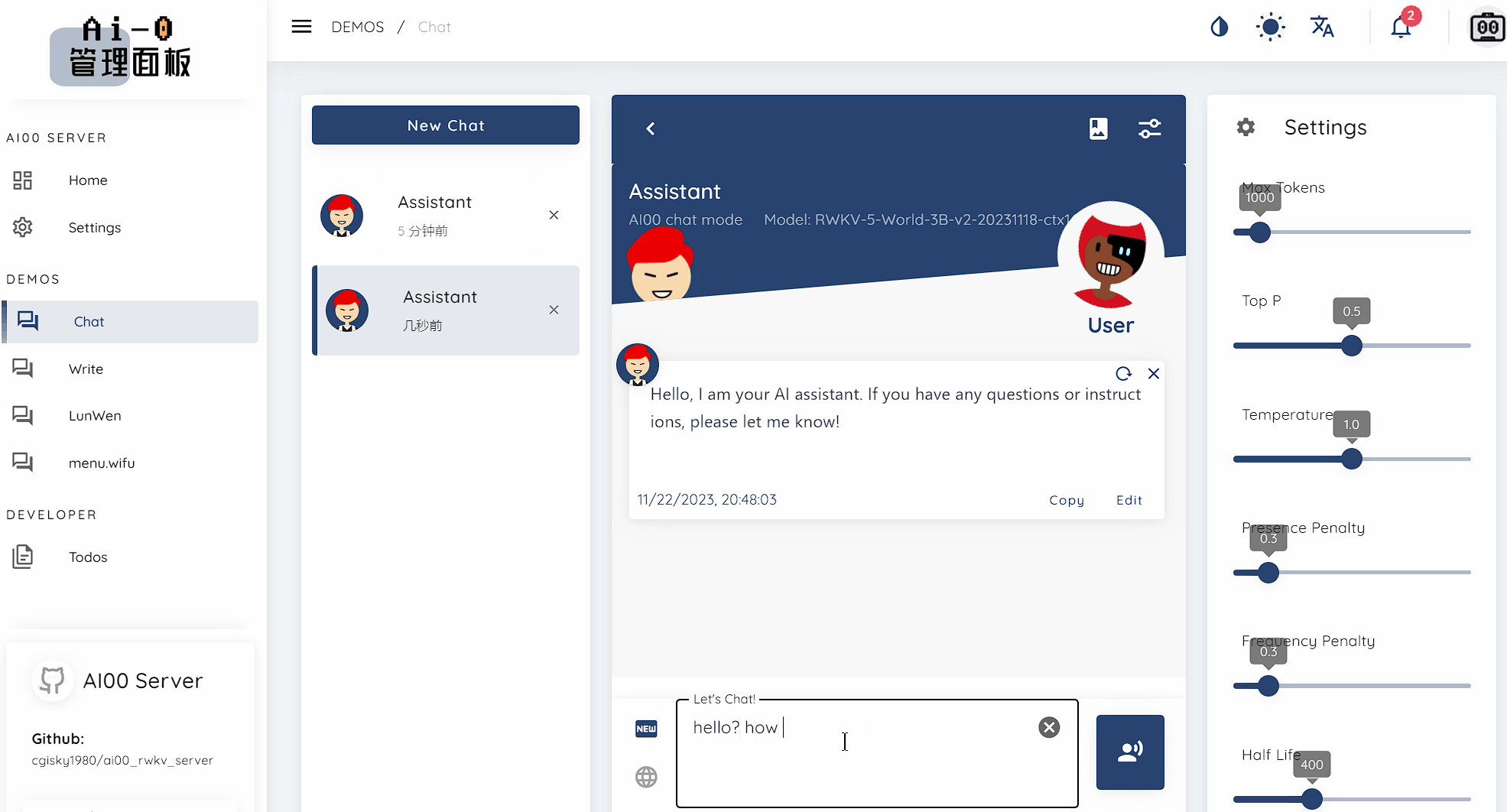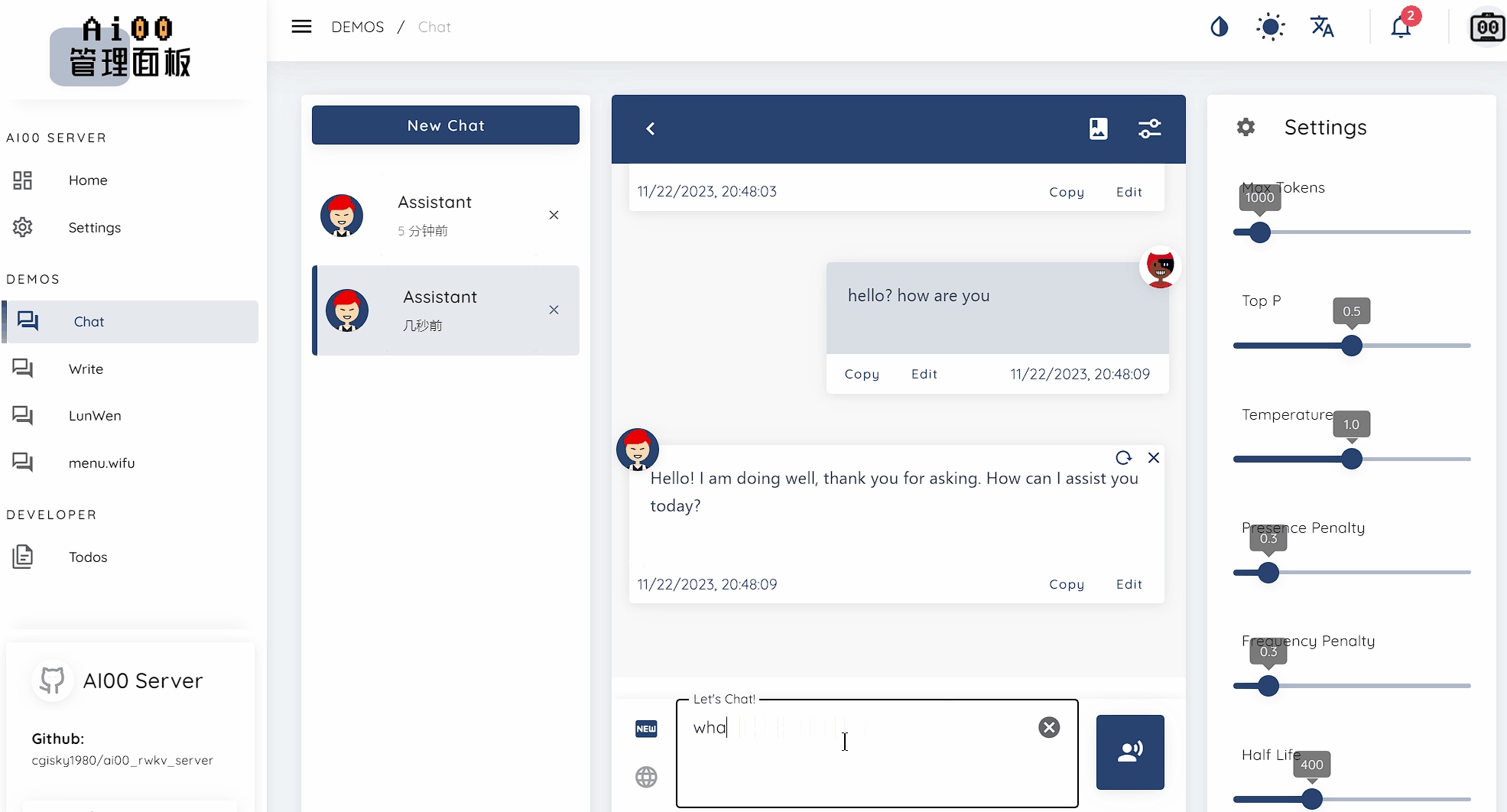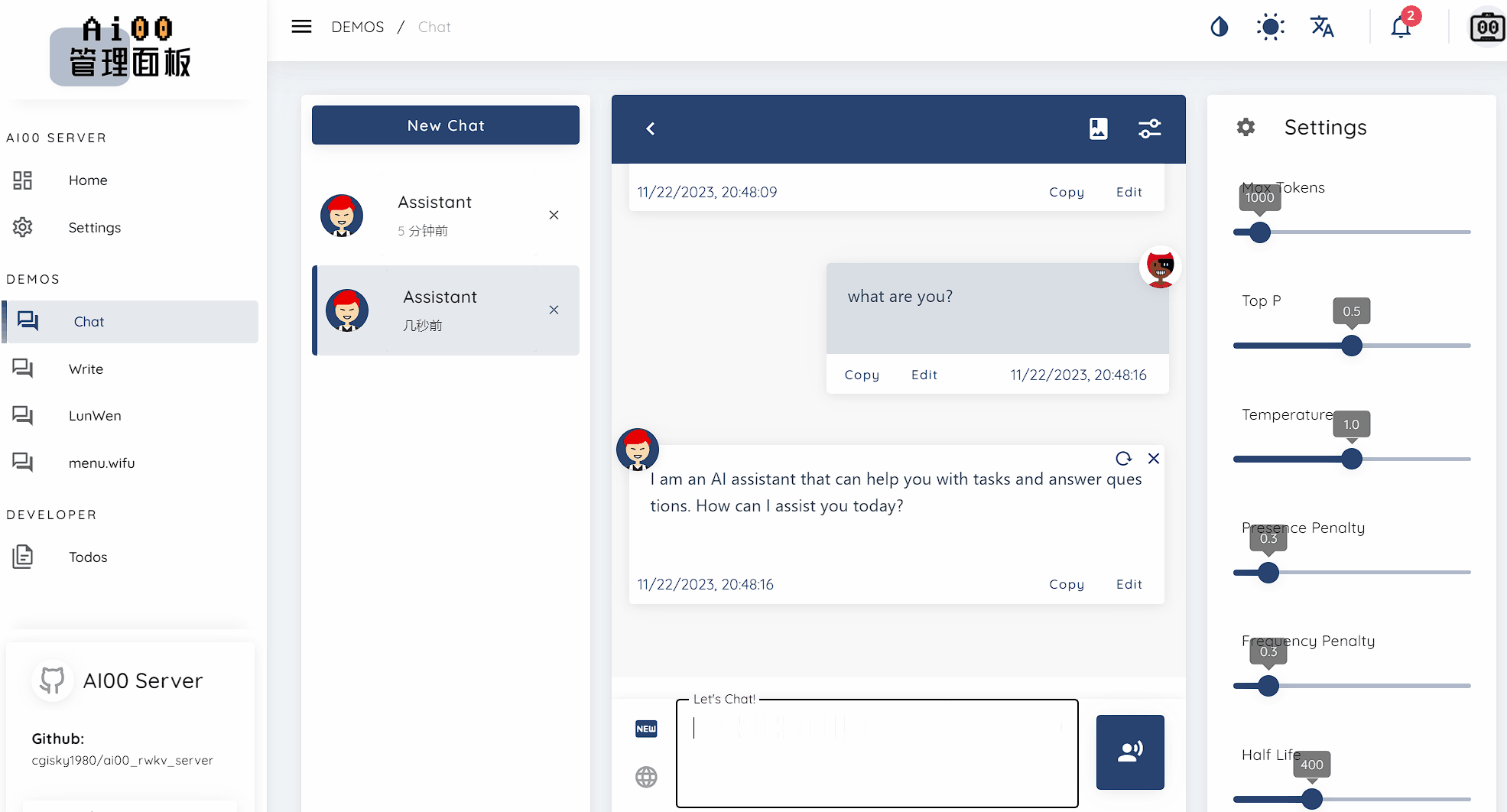
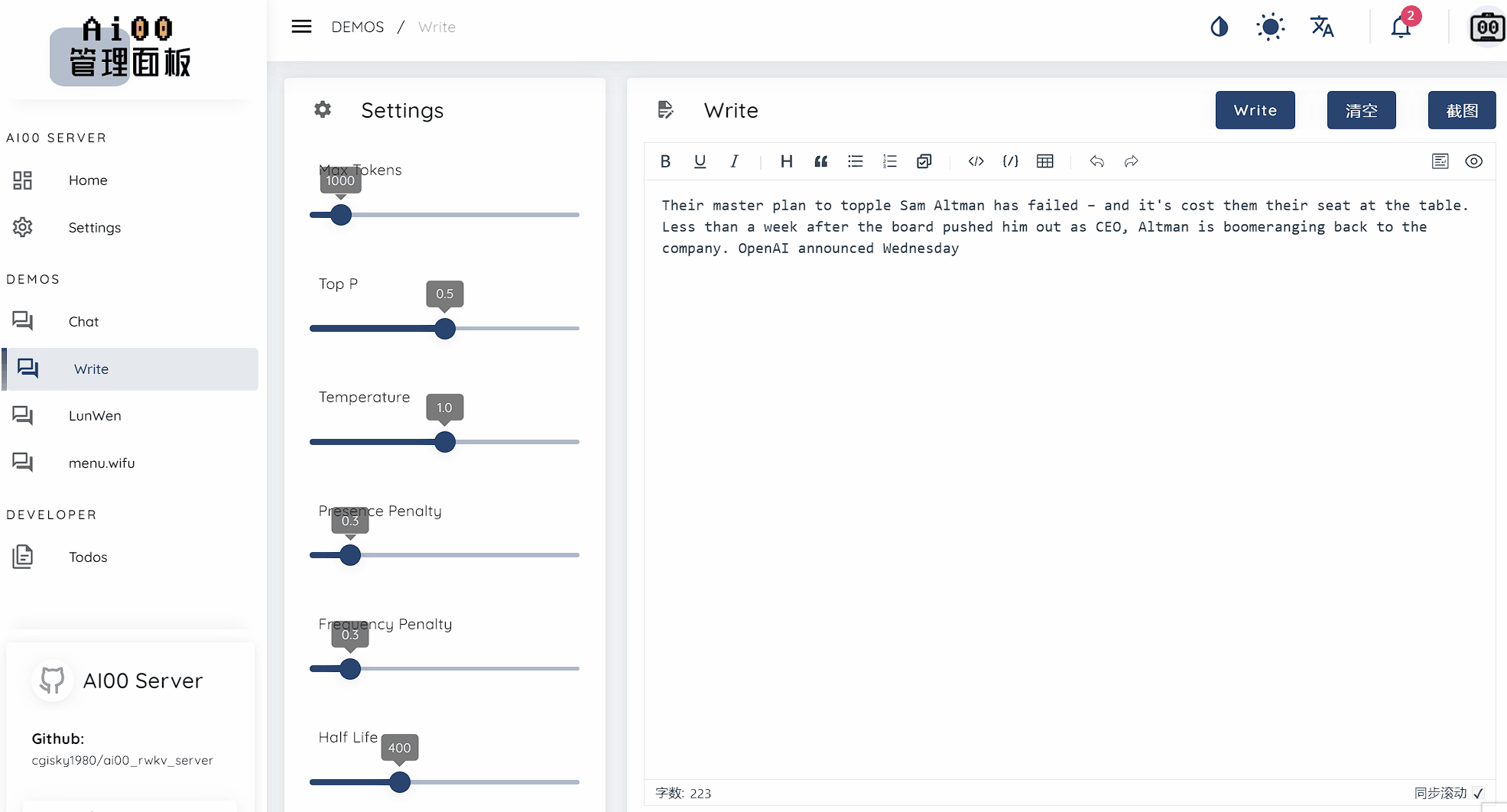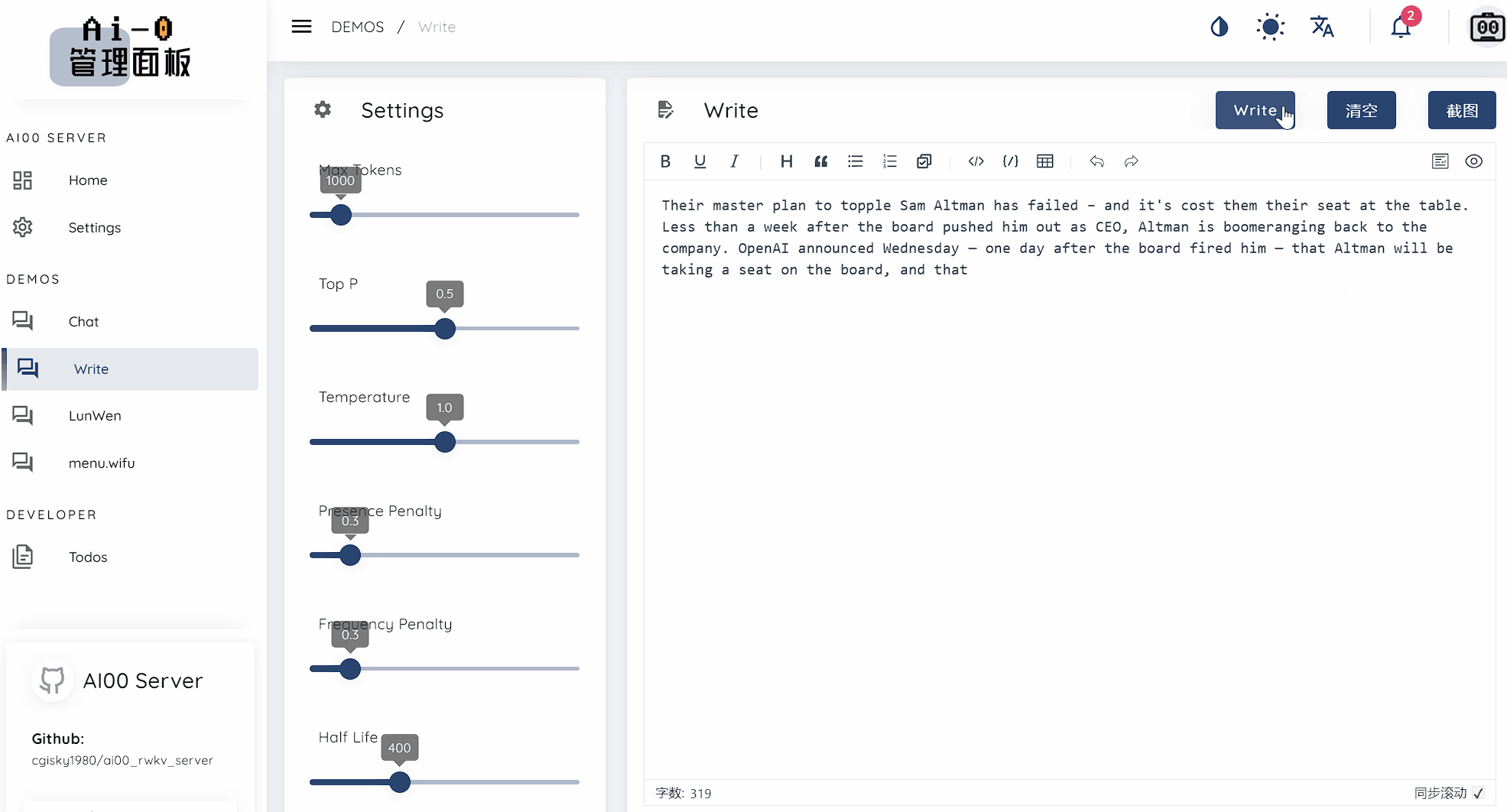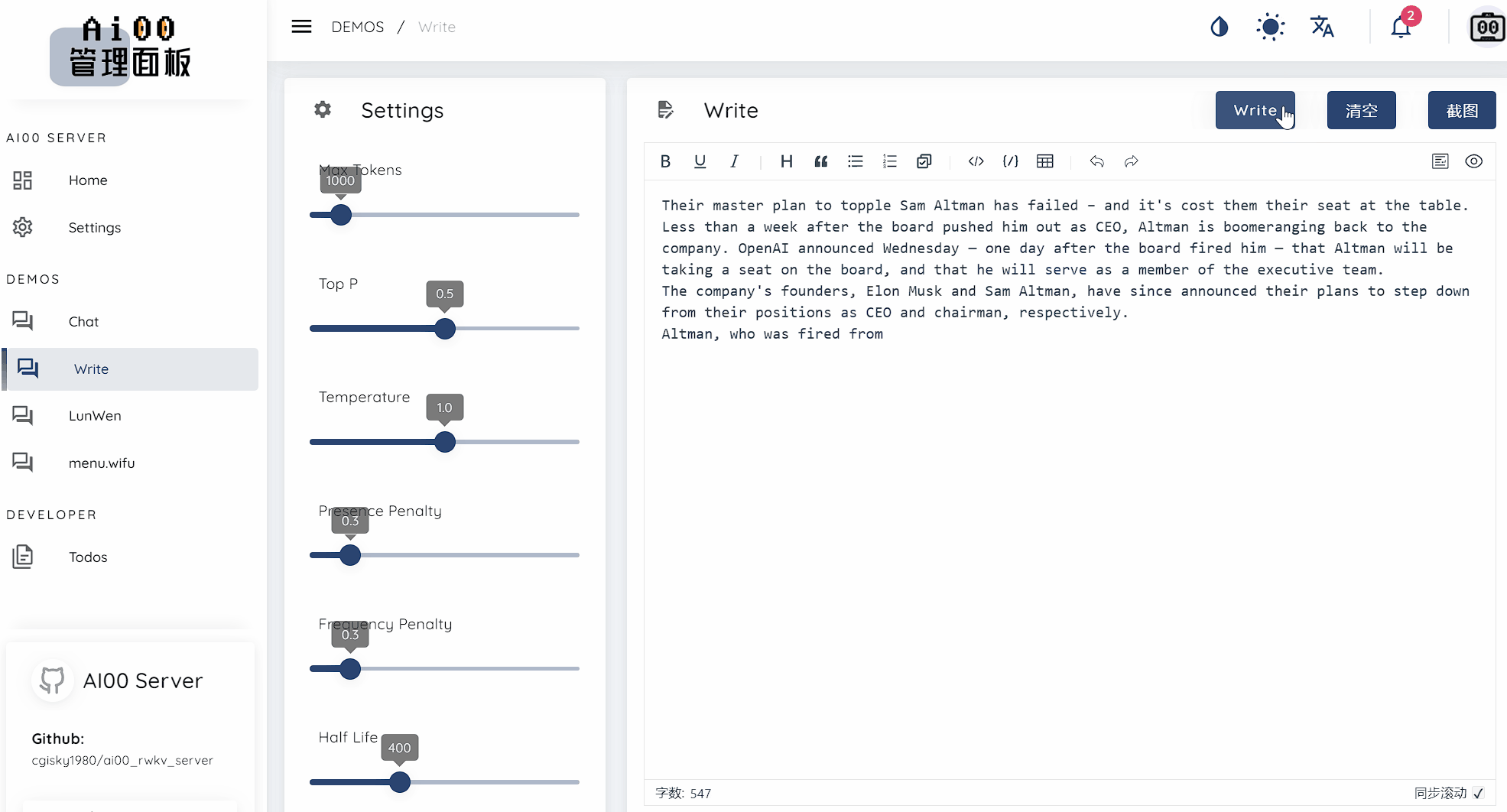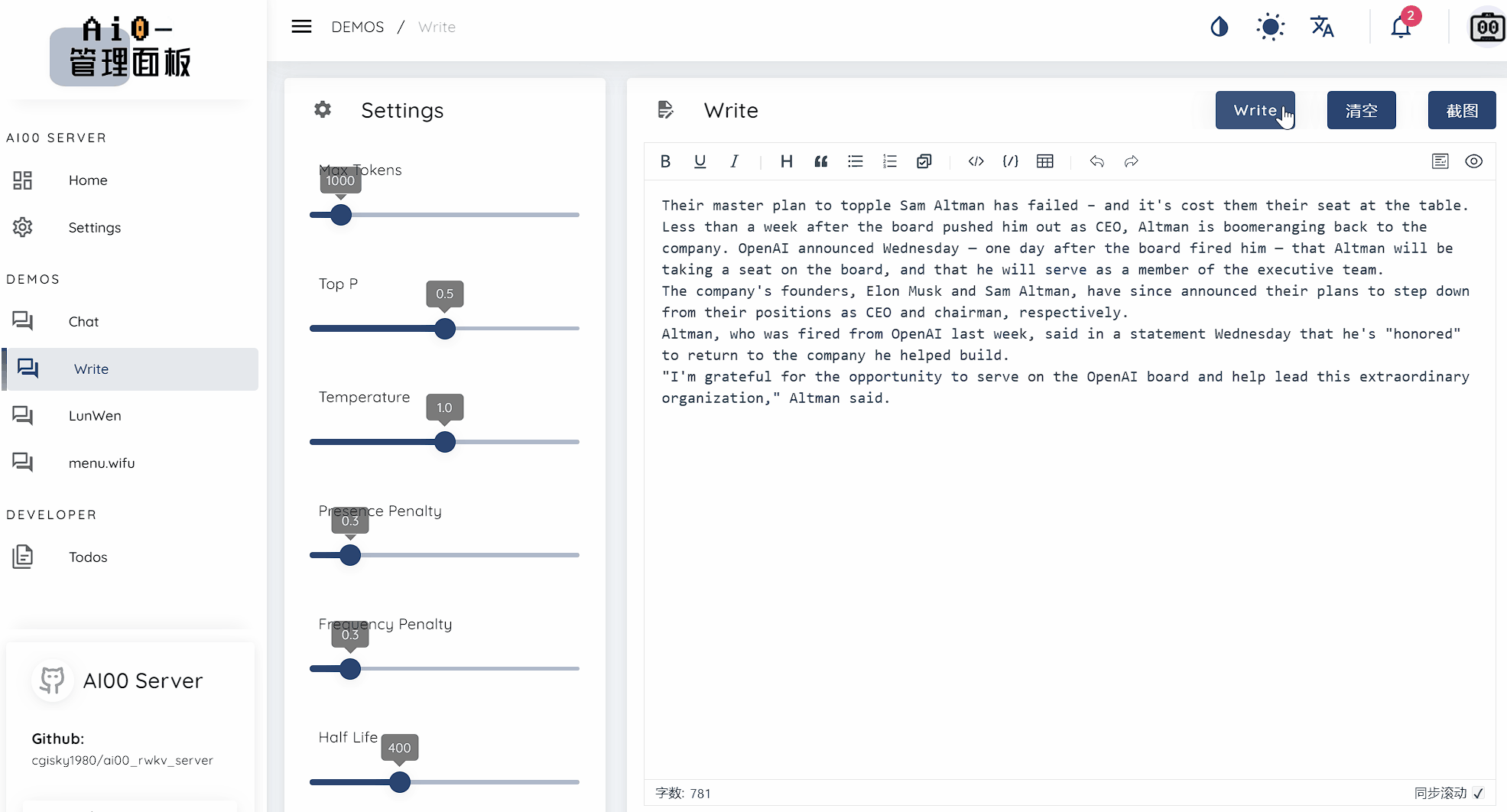
text_completions และ chat_completions batch serve int8 NF4 LoRA LoRA เรามักจะมองหาคนที่สนใจช่วยเราปรับปรุงโครงการ หากคุณสนใจสิ่งต่อไปนี้โปรดเข้าร่วมกับเรา!
ไม่ว่าระดับความสามารถของคุณเรายินดีต้อนรับคุณเข้าร่วมกับเรา คุณสามารถเข้าร่วมกับเราได้ในรูปแบบต่อไปนี้:
เราแทบรอไม่ไหวที่จะทำงานร่วมกับคุณเพื่อทำให้โครงการนี้ดีขึ้น! เราหวังว่าโครงการจะเป็นประโยชน์กับคุณ!
ขอขอบคุณบุคคลที่ยอดเยี่ยมเหล่านี้ที่มีความฉลาดและโดดเด่นสำหรับการสนับสนุนและการอุทิศตนอย่างไม่เห็นแก่ตัวต่อโครงการ!
顾真牛 - - ?? | 研究社交 - - - - | josc146 - - - | L15Y - - | Cahya Wirawan - | yuunnn_w | Longzou ? |
Luoqiqi |


