ai00_server
v0.5.9

AI00 RWKV Server é um servidor API de inferência para o modelo de linguagem RWKV com base no mecanismo de inferência web-rwkv .
Ele suporta a inferência paralela e simultânea Vulkan e pode ser executada em todas as GPUs que suportam Vulkan . Não há necessidade de cartões nvidia !!! Cartões AMD e até gráficos integrados podem ser acelerados !!!
Não há necessidade de pytorch volumoso, CUDA e outros ambientes de tempo de execução, é compacto e pronto para usar fora da caixa!
Compatível com a interface API ChatGPT do OpenAI.
100% de código aberto e utilizável comercial, sob a licença do MIT.
Se você está procurando um servidor API LLM rápido, eficiente e fácil de usar, AI00 RWKV Server é a sua melhor escolha. Pode ser usado para várias tarefas, incluindo chatbots, geração de texto, tradução e perguntas e respostas.
Junte -se à comunidade AI00 RWKV Server agora e experimente o charme da IA!
Grupo QQ para Comunicação: 30920262
RWKV , ele tem alto desempenho e precisãoVulkan , você pode desfrutar de aceleração da GPU sem a necessidade de CUDA ! Suporta cartões AMD, gráficos integrados e todas as GPUs que suportam Vulkanpytorch volumoso, CUDA e outros ambientes de tempo de execução, é compacto e pronto para usar fora da caixa!Faça o download diretamente da versão mais recente do lançamento
Depois de baixar o modelo, coloque o modelo nos assets/models/ caminho, por exemplo, assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Opcionalmente, modifique assets/configs/Config.toml para configurações de modelo, como caminho do modelo, camadas de quantização, etc.
Execute na linha de comando
$ ./ai00_rwkv_server Abra o navegador e visite o webui em http: // localhost: 65530 (https: // localhost: 65530 Se tls estiver ativado)
Instale a ferrugem
Clone este repositório
$ git clone https://github.com/cgisky1980/ai00_rwkv_server.git
$ cd ai00_rwkv_server Depois de baixar o modelo, coloque o modelo nos assets/models/ caminho, por exemplo, assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Compilar
$ cargo build --releaseApós a compilação, execute
$ cargo run --release Abra o navegador e visite o webui em http: // localhost: 65530 (https: // localhost: 65530 Se tls estiver ativado)
Ele apenas suporta modelos SafeTensors com a extensão .st agora. Os modelos salvos com a extensão .pth usando a tocha precisam ser convertidos antes do uso.
Baixe o modelo .pth
(Recomendado) Execute o script python convert2ai00.py ou convert_safetensors.py :
$ python ./convert2ai00.py --input /path/to/model.pth --output /path/to/model.st Requisitos: Python, com torch e safetensors instalados.
Se você não deseja instalar o Python, na versão, poderá encontrar um converter executável chamado. Correr
$ ./converter --input /path/to/model.pth --output /path/to/model.st$ cargo run --release --package converter -- --input /path/to/model.pth --output /path/to/model.st.st nos assets/models/ caminho e modifique o caminho do modelo em assets/configs/Config.toml --config : Configurar Caminho do arquivo (Padrão: assets/configs/Config.toml )--ip : o endereço IP que o servidor está vinculado a--port : Porta em execução O serviço API começa na porta 65530 e o formato de entrada e saída de dados segue a especificação da API do OpenAI. Observe que algumas APIs, como chat e completions têm campos opcionais adicionais para funcionalidades avançadas. Visite http: // localhost: 65530/api-docs para esquema de API.
/api/oai/v1/models/api/oai/models/api/oai/v1/chat/completions/api/oai/chat/completions/api/oai/v1/completions/api/oai/completions/api/oai/v1/embeddings/api/oai/embeddingsA seguir, é apresentado um exemplo fora da caixa de invocações da API AI00 em Python:
import openai
class Ai00 :
def __init__ ( self , model = "model" , port = 65530 , api_key = "JUSTSECRET_KEY" ) :
openai . api_base = f"http://127.0.0.1: { port } /api/oai"
openai . api_key = api_key
self . ctx = []
self . params = {
"system_name" : "System" ,
"user_name" : "User" ,
"assistant_name" : "Assistant" ,
"model" : model ,
"max_tokens" : 4096 ,
"top_p" : 0.6 ,
"temperature" : 1 ,
"presence_penalty" : 0.3 ,
"frequency_penalty" : 0.3 ,
"half_life" : 400 ,
"stop" : [ ' x00 ' , ' n n ' ]
}
def set_params ( self , ** kwargs ):
self . params . update ( kwargs )
def clear_ctx ( self ):
self . ctx = []
def get_ctx ( self ):
return self . ctx
def continuation ( self , message ):
response = openai . Completion . create (
model = self . params [ 'model' ],
prompt = message ,
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = response . choices [ 0 ]. text
return result
def append_ctx ( self , role , content ):
self . ctx . append ({
"role" : role ,
"content" : content
})
def send_message ( self , message , role = "user" ):
self . ctx . append ({
"role" : role ,
"content" : message
})
result = openai . ChatCompletion . create (
model = self . params [ 'model' ],
messages = self . ctx ,
names = {
"system" : self . params [ 'system_name' ],
"user" : self . params [ 'user_name' ],
"assistant" : self . params [ 'assistant_name' ]
},
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = result . choices [ 0 ]. message [ 'content' ]
self . ctx . append ({
"role" : "assistant" ,
"content" : result
})
return result
ai00 = Ai00 ()
ai00 . set_params (
max_tokens = 4096 ,
top_p = 0.55 ,
temperature = 2 ,
presence_penalty = 0.3 ,
frequency_penalty = 0.8 ,
half_life = 400 ,
stop = [ ' x00 ' , ' n n ' ]
)
print ( ai00 . send_message ( "how are you?" ))
print ( ai00 . send_message ( "me too!" ))
print ( ai00 . get_ctx ())
ai00 . clear_ctx ()
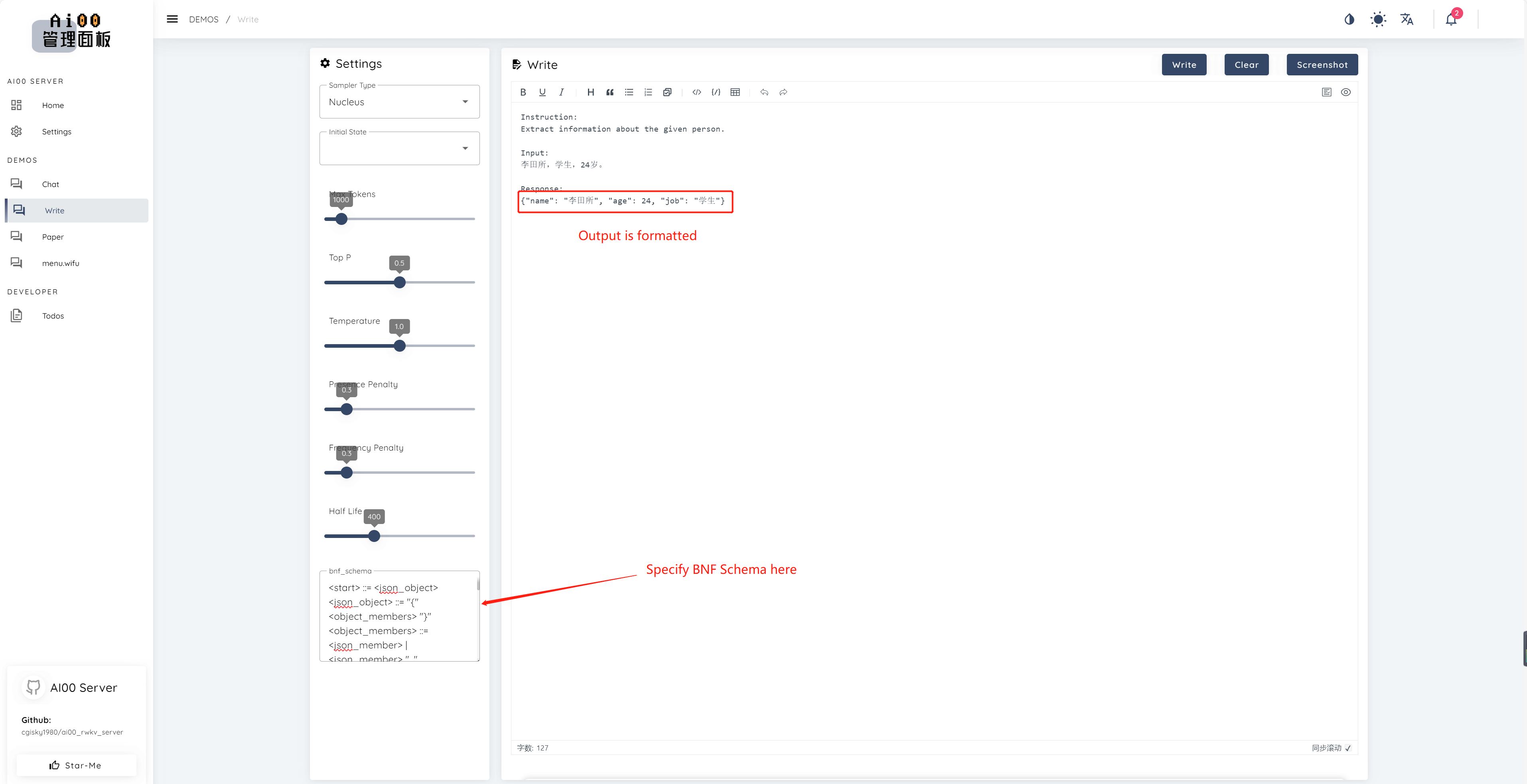
print ( ai00 . continuation ( "i like" ))Desde v0.5, o AI00 possui um recurso exclusivo chamado BNF Amostring. O BNF força o modelo a produzir em formatos especificados (por exemplo, JSON ou Markdown com campos especificados), limitando os possíveis tokens próximos que o modelo pode escolher.
Aqui está um exemplo BNF para JSON com campos "Nome", "Age" e "Job":
<start> ::= <json_object>
<json_object> ::= "{" <object_members> "}"
<object_members> ::= <json_member> | <json_member> ", " <object_members>
<json_member> ::= <json_key> ": " <json_value>
<json_key> ::= '"' "name" '"' | '"' "age" '"' | '"' "job" '"'
<json_value> ::= <json_string> | <json_number>
<json_string>::='"'<content>'"'
<content>::=<except!([escaped_literals])>|<except!([escaped_literals])><content>|'\"'<content>|'\"'
<escaped_literals>::='t'|'n'|'r'|'"'
<json_number> ::= <positive_digit><digits>|'0'
<digits>::=<digit>|<digit><digits>
<digit>::='0'|<positive_digit>
<positive_digit>::="1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"
text_completions e chat_completions batch serve int8 NF4 LoRA LoRA Estamos sempre procurando pessoas interessadas em nos ajudar a melhorar o projeto. Se você estiver interessado em algum dos seguintes, junte -se a nós!
Não importa o seu nível de habilidade, recebemos você em se juntar a nós. Você pode se juntar a nós das seguintes maneiras:
Mal podemos esperar para trabalhar com você para melhorar este projeto! Esperamos que o projeto seja útil para você!
Obrigado a essas pessoas incríveis que são perspicazes e destacadas por seu apoio e dedicação altruísta ao projeto!
顾真牛 ? ? ? ? | 研究社交 ? ? ? ? | JOSC146 ? ? ? | L15Y ? ? | Cahya Wirawan ? | yuunnn_w | Longzou ? ️ |
Luoqiqi |


