ai00_server
v0.5.9

AI00 RWKV Server web-rwkv推論エンジンに基づいたRWKV言語モデルの推論APIサーバーです。
Vulkan平行と同時のバッチ推論をサポートし、 VulkanをサポートするすべてのGPUで実行できます。 nvidiaカードは必要ありません!!! AMDカードや統合されたグラフィックも加速できます!!!
かさばるpytorch 、 CUDA 、その他のランタイム環境は必要ありません。コンパクトで、すぐに使用できる準備ができています!
OpenaiのChatGPT APIインターフェイスと互換性があります。
MITライセンスの下で、100%オープンソースと商業的に使用可能。
高速で効率的で使いやすいLLM APIサーバーを探している場合は、 AI00 RWKV Serverが最良の選択です。チャットボット、テキスト生成、翻訳、Q&Aなど、さまざまなタスクに使用できます。
今すぐAI00 RWKV Serverコミュニティに参加して、AIの魅力を体験してください!
コミュニケーションのためのQQグループ:30920262
RWKVモデルに基づいて、パフォーマンスと精度が高いVulkan推論の加速をサポートし、 CUDAを必要とせずにGPU加速を楽しむことができます! AMDカード、統合グラフィックス、およびVulkanサポートするすべてのGPUをサポートしますpytorch 、 CUDA 、その他のランタイム環境は必要ありません。コンパクトで、すぐに使用できる準備ができています!リリースから最新バージョンを直接ダウンロードします
モデルをダウンロードした後、モデルをassets/models/パス、たとえばassets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.stに配置します。
オプションで、モデルパス、量子化レイヤーなどなどのモデル構成のassets/configs/Config.toml変更します。
コマンドラインで実行します
$ ./ai00_rwkv_serverブラウザを開いて、http:// localhost:65530(https:// localhost:65530でWebUIにアクセスしてください。TLS tls有効になっている場合)
さびを取り付けます
このリポジトリをクローンします
$ git clone https://github.com/cgisky1980/ai00_rwkv_server.git
$ cd ai00_rwkv_serverモデルをダウンロードした後、モデルをassets/models/パス、たとえばassets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.stに配置します。
コンパイル
$ cargo build --releaseコンピレーション後、実行します
$ cargo run --releaseブラウザを開いて、http:// localhost:65530(https:// localhost:65530でWebUIにアクセスしてください。TLS tls有効になっている場合)
Safetensorsモデルのみ.stサポートしています。トーチを使用して.pth拡張機能で保存されたモデルは、使用する前に変換する必要があります。
.pthモデルをダウンロードします
(推奨)Pythonスクリプトconvert2ai00.pyまたはconvert_safetensors.pyを実行します:
$ python ./convert2ai00.py --input /path/to/model.pth --output /path/to/model.st要件:Python、 torchとsafetensorsがインストールされています。
Pythonをインストールしたくない場合は、リリースでconverterという実行可能ファイルを見つけることができます。走る
$ ./converter --input /path/to/model.pth --output /path/to/model.st$ cargo run --release --package converter -- --input /path/to/model.pth --output /path/to/model.st.stモデルにassets/models/パスに配置し、 assets/configs/Config.tomlのモデルパスを変更します--config :ファイルパスを構成(デフォルト: assets/configs/Config.toml )--ip :サーバーがバインドされているIPアドレス--port :ランニングポート APIサービスはポート65530から始まり、データ入力と出力形式はOpenAI API仕様に従います。 chatやcompletionsな一部のAPIには、高度な機能のための追加のオプションフィールドがあることに注意してください。 APIスキーマについては、http:// localhost:65530/api-docsにアクセスしてください。
/api/oai/v1/models/api/oai/models/api/oai/v1/chat/completions/api/oai/chat/completions/api/oai/v1/completions/api/oai/completions/api/oai/v1/embeddings/api/oai/embeddings以下は、PythonでのAI00 API Invocationsのボックス外の例です。
import openai
class Ai00 :
def __init__ ( self , model = "model" , port = 65530 , api_key = "JUSTSECRET_KEY" ) :
openai . api_base = f"http://127.0.0.1: { port } /api/oai"
openai . api_key = api_key
self . ctx = []
self . params = {
"system_name" : "System" ,
"user_name" : "User" ,
"assistant_name" : "Assistant" ,
"model" : model ,
"max_tokens" : 4096 ,
"top_p" : 0.6 ,
"temperature" : 1 ,
"presence_penalty" : 0.3 ,
"frequency_penalty" : 0.3 ,
"half_life" : 400 ,
"stop" : [ ' x00 ' , ' n n ' ]
}
def set_params ( self , ** kwargs ):
self . params . update ( kwargs )
def clear_ctx ( self ):
self . ctx = []
def get_ctx ( self ):
return self . ctx
def continuation ( self , message ):
response = openai . Completion . create (
model = self . params [ 'model' ],
prompt = message ,
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = response . choices [ 0 ]. text
return result
def append_ctx ( self , role , content ):
self . ctx . append ({
"role" : role ,
"content" : content
})
def send_message ( self , message , role = "user" ):
self . ctx . append ({
"role" : role ,
"content" : message
})
result = openai . ChatCompletion . create (
model = self . params [ 'model' ],
messages = self . ctx ,
names = {
"system" : self . params [ 'system_name' ],
"user" : self . params [ 'user_name' ],
"assistant" : self . params [ 'assistant_name' ]
},
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = result . choices [ 0 ]. message [ 'content' ]
self . ctx . append ({
"role" : "assistant" ,
"content" : result
})
return result
ai00 = Ai00 ()
ai00 . set_params (
max_tokens = 4096 ,
top_p = 0.55 ,
temperature = 2 ,
presence_penalty = 0.3 ,
frequency_penalty = 0.8 ,
half_life = 400 ,
stop = [ ' x00 ' , ' n n ' ]
)
print ( ai00 . send_message ( "how are you?" ))
print ( ai00 . send_message ( "me too!" ))
print ( ai00 . get_ctx ())
ai00 . clear_ctx ()
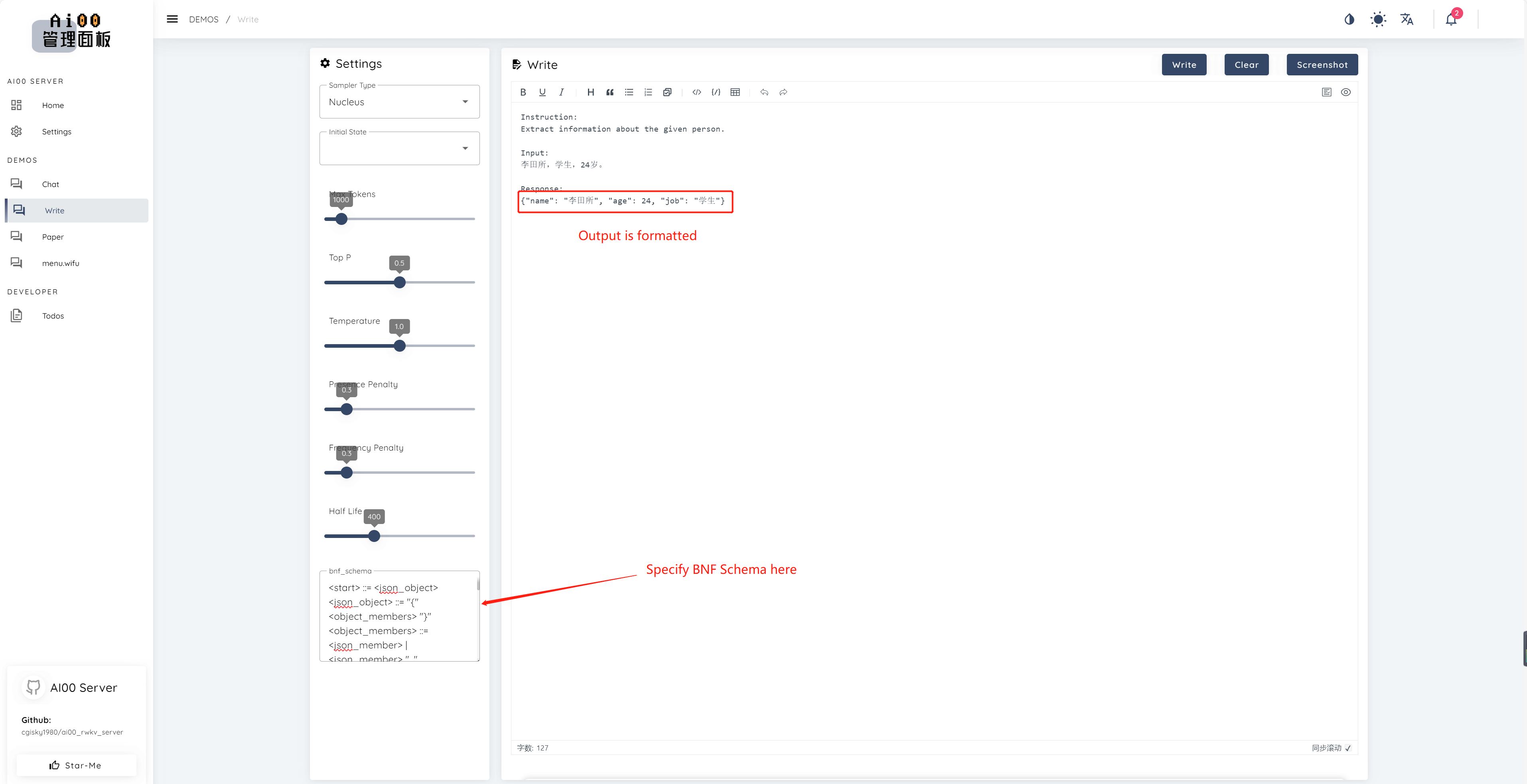
print ( ai00 . continuation ( "i like" ))V0.5以来、AI00にはBNFサンプリングと呼ばれる一意の機能があります。 BNFは、モデルが選択できるトークンを制限することにより、モデルを指定された形式(例えば、指定されたフィールドを使用したJSONまたはマークダウンなど)で出力するように強制します。
これは、フィールド「名前」、「年齢」、「ジョブ」を持つJSONのBNFの例です。
<start> ::= <json_object>
<json_object> ::= "{" <object_members> "}"
<object_members> ::= <json_member> | <json_member> ", " <object_members>
<json_member> ::= <json_key> ": " <json_value>
<json_key> ::= '"' "name" '"' | '"' "age" '"' | '"' "job" '"'
<json_value> ::= <json_string> | <json_number>
<json_string>::='"'<content>'"'
<content>::=<except!([escaped_literals])>|<except!([escaped_literals])><content>|'\"'<content>|'\"'
<escaped_literals>::='t'|'n'|'r'|'"'
<json_number> ::= <positive_digit><digits>|'0'
<digits>::=<digit>|<digit><digits>
<digit>::='0'|<positive_digit>
<positive_digit>::="1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"
text_completionsとchat_completionsのサポートbatch serveを介した並列推論int8量子化のサポートNF4量子化のサポートLoRAモデルのサポートLoRAモデルのホットローディングと切り替え私たちは常に、プロジェクトの改善を支援することに興味がある人を探しています。次のいずれかに興味がある場合は、ご参加ください!
あなたのスキルレベルに関係なく、私たちはあなたに参加することを歓迎します。次の方法で参加できます。
このプロジェクトを改善するためにあなたと協力するのが待ちきれません!プロジェクトがあなたに役立つことを願っています!
プロジェクトへのサポートと無私の献身に洞察力に富んで傑出したこれらの素晴らしい個人に感謝します!
顾真牛 ? ? ?? | 研究社交 ? ? ? ? | JOSC146 ? ? ? | L15Y ? ? | Cahya Wirawan ? | yuunn_w | ロングツー ?§ |
luoqiqi |


