ai00_server
v0.5.9

AI00 RWKV Server -это сервер API вывода для модели языка RWKV на основе механизма вывода web-rwkv .
Он поддерживает параллельный и одновременный пакетный вывод Vulkan и может работать на всех графических процессорах, которые поддерживают Vulkan . Нет необходимости в картах nvidia !!! Карты AMD и даже интегрированная графика могут быть ускорены !!!
Нет необходимости в громоздких средах pytorch , CUDA и других среде выполнения, он компактен и готов к использованию из коробки!
Совместим с интерфейсом API Openai.
100% с открытым исходным кодом и коммерчески использование, под лицензией MIT.
Если вы ищете быстрый, эффективный и простой в использовании сервер API LLM, то AI00 RWKV Server -ваш лучший выбор. Его можно использовать для различных задач, включая чат -боты, генерацию текста, перевод и вопросы и ответы.
Присоединяйтесь к сообществу AI00 RWKV Server сейчас и испытайте очарование ИИ!
QQ Group для связи: 30920262
RWKV , она имеет высокую производительность и точностьVulkan , вы можете насладиться ускорением графического процессора без необходимости в CUDA ! Поддерживает карты AMD, интегрированную графику и все графические процессоры, которые поддерживают Vulkanpytorch , CUDA и других среде выполнения, он компактен и готов к использованию из коробки!Прямо скачать последнюю версию из релиза
После загрузки модели поместите модель в assets/models/ Path, например, assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Необязательно изменить assets/configs/Config.toml для конфигураций модели, таких как путь модели, квантование и т. Д.
Запустить в командной строке
$ ./ai00_rwkv_server Откройте браузер и посетите Webui по адресу http: // localhost: 65530 (https: // localhost: 65530, если включен tls )
Установить ржавчину
Клонировать это хранилище
$ git clone https://github.com/cgisky1980/ai00_rwkv_server.git
$ cd ai00_rwkv_server После загрузки модели поместите модель в assets/models/ Path, например, assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Компиляция
$ cargo build --releaseПосле сборника беги
$ cargo run --release Откройте браузер и посетите Webui по адресу http: // localhost: 65530 (https: // localhost: 65530, если включен tls )
Он поддерживает только модели Safetensors с расширением .st . Модели, сохраненные с расширением .pth с использованием факела, необходимо преобразовать перед использованием.
Скачать модель .pth
(Рекомендуется) Запустите сценарий Python convert2ai00.py или convert_safetensors.py :
$ python ./convert2ai00.py --input /path/to/model.pth --output /path/to/model.st Требования: Python, с установленными torch и safetensors .
Если вы не хотите устанавливать Python, в релизе вы можете найти исполняемый файл с именем converter . Бегать
$ ./converter --input /path/to/model.pth --output /path/to/model.st$ cargo run --release --package converter -- --input /path/to/model.pth --output /path/to/model.stassets/configs/Config.toml как указанные выше шаги, поместите модель в .st assets/models/ --config : настройка пути файла (по умолчанию: assets/configs/Config.toml )--ip : IP-адрес, который связан сервером--port : управляющий порт Служба API начинается с порта 65530, а формат ввода и вывода данных следуют спецификации API OpenAI. Обратите внимание, что некоторые API, такие как chat и completions имеют дополнительные дополнительные поля для расширенных функций. Посетите http: // localhost: 65530/api-docs для схемы API.
/api/oai/v1/models/api/oai/models/api/oai/v1/chat/completions/api/oai/chat/completions/api/oai/v1/completions/api/oai/completions/api/oai/v1/embeddings/api/oai/embeddingsНиже приведен пример вызовов API API AI00 в Python:
import openai
class Ai00 :
def __init__ ( self , model = "model" , port = 65530 , api_key = "JUSTSECRET_KEY" ) :
openai . api_base = f"http://127.0.0.1: { port } /api/oai"
openai . api_key = api_key
self . ctx = []
self . params = {
"system_name" : "System" ,
"user_name" : "User" ,
"assistant_name" : "Assistant" ,
"model" : model ,
"max_tokens" : 4096 ,
"top_p" : 0.6 ,
"temperature" : 1 ,
"presence_penalty" : 0.3 ,
"frequency_penalty" : 0.3 ,
"half_life" : 400 ,
"stop" : [ ' x00 ' , ' n n ' ]
}
def set_params ( self , ** kwargs ):
self . params . update ( kwargs )
def clear_ctx ( self ):
self . ctx = []
def get_ctx ( self ):
return self . ctx
def continuation ( self , message ):
response = openai . Completion . create (
model = self . params [ 'model' ],
prompt = message ,
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = response . choices [ 0 ]. text
return result
def append_ctx ( self , role , content ):
self . ctx . append ({
"role" : role ,
"content" : content
})
def send_message ( self , message , role = "user" ):
self . ctx . append ({
"role" : role ,
"content" : message
})
result = openai . ChatCompletion . create (
model = self . params [ 'model' ],
messages = self . ctx ,
names = {
"system" : self . params [ 'system_name' ],
"user" : self . params [ 'user_name' ],
"assistant" : self . params [ 'assistant_name' ]
},
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = result . choices [ 0 ]. message [ 'content' ]
self . ctx . append ({
"role" : "assistant" ,
"content" : result
})
return result
ai00 = Ai00 ()
ai00 . set_params (
max_tokens = 4096 ,
top_p = 0.55 ,
temperature = 2 ,
presence_penalty = 0.3 ,
frequency_penalty = 0.8 ,
half_life = 400 ,
stop = [ ' x00 ' , ' n n ' ]
)
print ( ai00 . send_message ( "how are you?" ))
print ( ai00 . send_message ( "me too!" ))
print ( ai00 . get_ctx ())
ai00 . clear_ctx ()
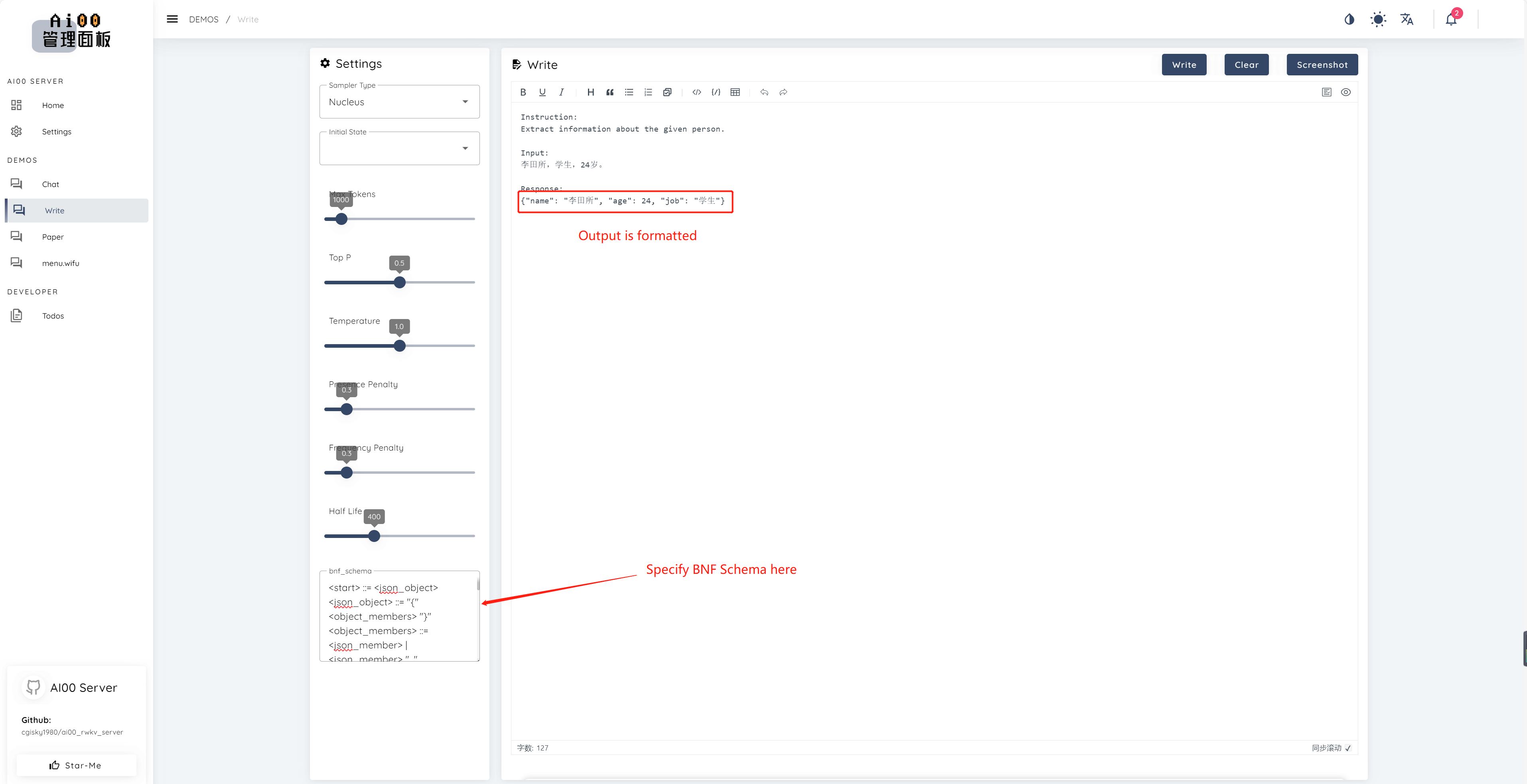
print ( ai00 . continuation ( "i like" ))Начиная с v0.5, AI00 имеет уникальную функцию под названием BNF Sampling. BNF вынуждает модель выходить в указанных форматах (например, JSON или Markdown с указанными полями), ограничивая возможные рядом с токенами, из которых модель может выбрать.
Вот пример BNF для JSON с полями «Имя», «Возраст» и «Иов»:
<start> ::= <json_object>
<json_object> ::= "{" <object_members> "}"
<object_members> ::= <json_member> | <json_member> ", " <object_members>
<json_member> ::= <json_key> ": " <json_value>
<json_key> ::= '"' "name" '"' | '"' "age" '"' | '"' "job" '"'
<json_value> ::= <json_string> | <json_number>
<json_string>::='"'<content>'"'
<content>::=<except!([escaped_literals])>|<except!([escaped_literals])><content>|'\"'<content>|'\"'
<escaped_literals>::='t'|'n'|'r'|'"'
<json_number> ::= <positive_digit><digits>|'0'
<digits>::=<digit>|<digit><digits>
<digit>::='0'|<positive_digit>
<positive_digit>::="1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"
text_completions и chat_completions batch serve int8 NF4 LoRA LoRA Мы всегда ищем людей, заинтересованных в том, чтобы помочь нам улучшить проект. Если вы заинтересованы в каком -либо из следующего, присоединяйтесь к нам!
Независимо от вашего уровня квалификации, мы приветствуем вас присоединиться к нам. Вы можете присоединиться к нам следующим образом:
Мы не можем дождаться, чтобы поработать с вами, чтобы сделать этот проект лучше! Мы надеемся, что проект вам полезен!
Спасибо этим удивительным людям, которые проницательны и выдающиеся за свою поддержку и самоотверженную преданность проекту!
顾真牛 ? ? ? ? | 研究社交 ? ? ? ? | JOSC146 ? ? ? | L15y ? ? | Cahya Wirawan ? | yuunnn_w | Лонгзу ? ️ |
luoqiqi |


