ai00_server
v0.5.9

AI00 RWKV Server est un serveur API d'inférence pour le modèle de langue RWKV basé sur le moteur d'inférence web-rwkv .
Il prend en charge l'inférence Vulkan parallèle et simultanée et peut fonctionner sur tous les GPU qui prennent en charge Vulkan . Pas besoin de cartes nvidia !!! Les cartes AMD et même les graphiques intégrés peuvent être accélérés !!!
Pas besoin de pytorch volumineux, CUDA et d'autres environnements d'exécution, il est compact et prêt à l'emploi!
Compatible avec l'interface API ChatGPT d'OpenAI.
100% open source et commercialement utilisable, en vertu de la licence du MIT.
Si vous recherchez un serveur API LLM rapide, efficace et facile à utiliser, AI00 RWKV Server est votre meilleur choix. Il peut être utilisé pour diverses tâches, y compris les chatbots, la génération de texte, la traduction et les questions et réponses.
Rejoignez la communauté AI00 RWKV Server maintenant et expérimentez le charme de l'IA!
Groupe QQ pour la communication: 30920262
RWKV , il a des performances et une précision élevéesVulkan , vous pouvez profiter de l'accélération du GPU sans avoir besoin de CUDA ! Prend en charge les cartes AMD, les graphiques intégrés et tous les GPU qui prennent en charge Vulkanpytorch volumineux, CUDA et d'autres environnements d'exécution, il est compact et prêt à l'emploi!Téléchargez directement la dernière version à partir de la version
Après avoir téléchargé le modèle, placez le modèle dans les assets/models/ chemin, par exemple, assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Modifier éventuellement assets/configs/Config.toml pour les configurations du modèle comme le chemin du modèle, les couches de quantification, etc.
Exécuter dans la ligne de commande
$ ./ai00_rwkv_server Ouvrez le navigateur et visitez le webui sur http: // localhost: 65530 (https: // localhost: 65530 si tls est activé)
Installer la rouille
Cloner ce référentiel
$ git clone https://github.com/cgisky1980/ai00_rwkv_server.git
$ cd ai00_rwkv_server Après avoir téléchargé le modèle, placez le modèle dans les assets/models/ chemin, par exemple, assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Compiler
$ cargo build --releaseAprès la compilation, courez
$ cargo run --release Ouvrez le navigateur et visitez le webui sur http: // localhost: 65530 (https: // localhost: 65530 si tls est activé)
Il ne prend en charge que les modèles SafeTtenseurs avec l'extension .st maintenant. Les modèles enregistrés avec l'extension .pth à l'aide de la torche doivent être convertis avant utilisation.
Télécharger le modèle .pth
(Recommandé) Exécutez le script python convert2ai00.py ou convert_safetensors.py :
$ python ./convert2ai00.py --input /path/to/model.pth --output /path/to/model.st Exigences: Python, avec torch et safetensors installés.
Si vous ne souhaitez pas installer Python, dans la version, vous pouvez trouver un exécutable appelé converter . Courir
$ ./converter --input /path/to/model.pth --output /path/to/model.st$ cargo run --release --package converter -- --input /path/to/model.pth --output /path/to/model.st.st dans les assets/models/ chemin et modifiez le chemin du modèle dans assets/configs/Config.toml --config : configurer le chemin du fichier (par défaut: assets/configs/Config.toml )--ip : l'adresse IP à laquelle le serveur est lié--port : Port en cours d'exécution Le service API démarre au port 65530 et le format d'entrée et de sortie de données suit la spécification de l'API OpenAI. Notez que certaines API comme chat et completions ont des champs facultatifs supplémentaires pour les fonctionnalités avancées. Visitez http: // localhost: 65530 / api-docs pour le schéma API.
/api/oai/v1/models/api/oai/models/api/oai/v1/chat/completions/api/oai/chat/completions/api/oai/v1/completions/api/oai/completions/api/oai/v1/embeddings/api/oai/embeddingsCe qui suit est un exemple hors de la boîte des invocations de l'API AI00 dans Python:
import openai
class Ai00 :
def __init__ ( self , model = "model" , port = 65530 , api_key = "JUSTSECRET_KEY" ) :
openai . api_base = f"http://127.0.0.1: { port } /api/oai"
openai . api_key = api_key
self . ctx = []
self . params = {
"system_name" : "System" ,
"user_name" : "User" ,
"assistant_name" : "Assistant" ,
"model" : model ,
"max_tokens" : 4096 ,
"top_p" : 0.6 ,
"temperature" : 1 ,
"presence_penalty" : 0.3 ,
"frequency_penalty" : 0.3 ,
"half_life" : 400 ,
"stop" : [ ' x00 ' , ' n n ' ]
}
def set_params ( self , ** kwargs ):
self . params . update ( kwargs )
def clear_ctx ( self ):
self . ctx = []
def get_ctx ( self ):
return self . ctx
def continuation ( self , message ):
response = openai . Completion . create (
model = self . params [ 'model' ],
prompt = message ,
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = response . choices [ 0 ]. text
return result
def append_ctx ( self , role , content ):
self . ctx . append ({
"role" : role ,
"content" : content
})
def send_message ( self , message , role = "user" ):
self . ctx . append ({
"role" : role ,
"content" : message
})
result = openai . ChatCompletion . create (
model = self . params [ 'model' ],
messages = self . ctx ,
names = {
"system" : self . params [ 'system_name' ],
"user" : self . params [ 'user_name' ],
"assistant" : self . params [ 'assistant_name' ]
},
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = result . choices [ 0 ]. message [ 'content' ]
self . ctx . append ({
"role" : "assistant" ,
"content" : result
})
return result
ai00 = Ai00 ()
ai00 . set_params (
max_tokens = 4096 ,
top_p = 0.55 ,
temperature = 2 ,
presence_penalty = 0.3 ,
frequency_penalty = 0.8 ,
half_life = 400 ,
stop = [ ' x00 ' , ' n n ' ]
)
print ( ai00 . send_message ( "how are you?" ))
print ( ai00 . send_message ( "me too!" ))
print ( ai00 . get_ctx ())
ai00 . clear_ctx ()
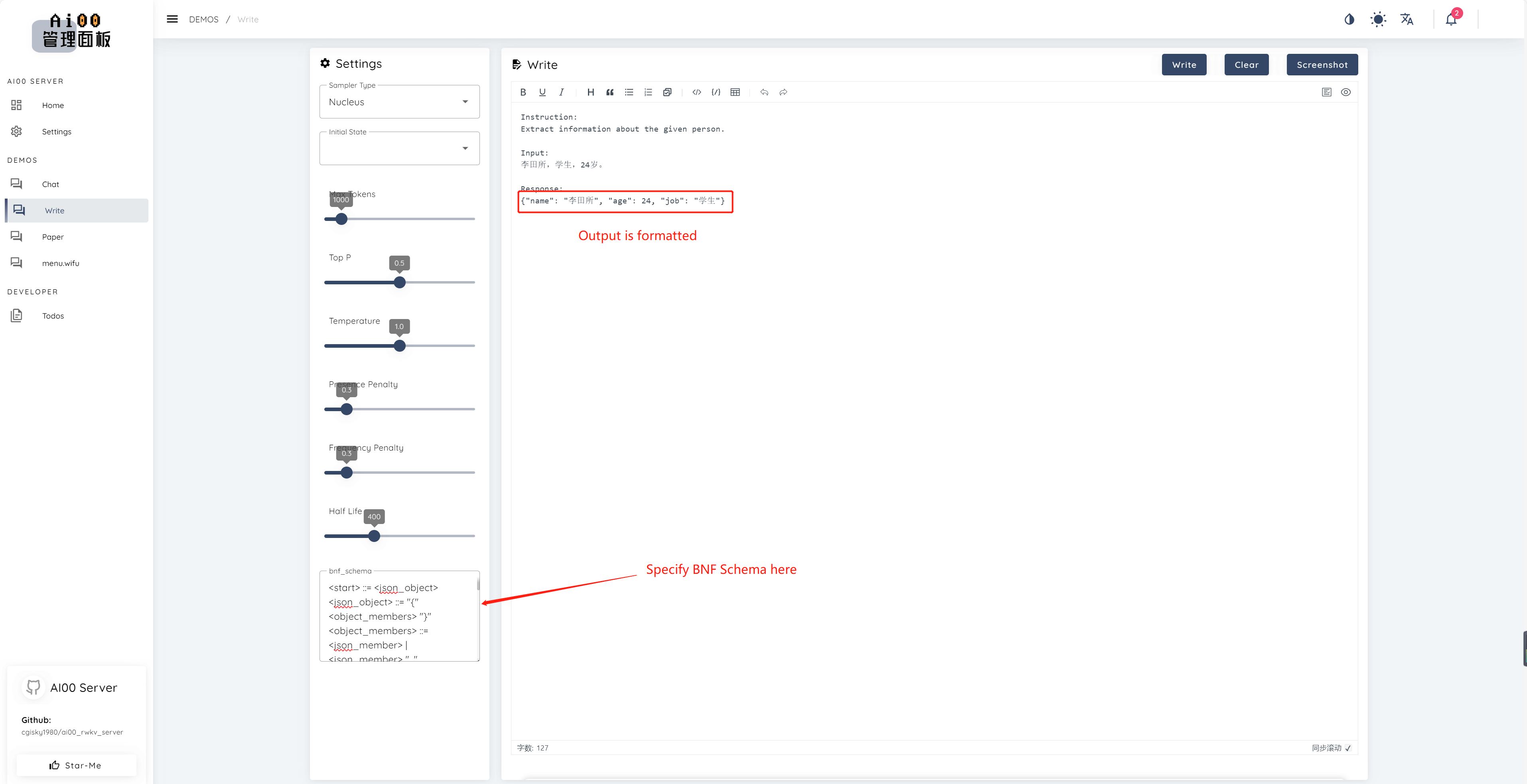
print ( ai00 . continuation ( "i like" ))Depuis V0.5, AI00 a une fonctionnalité unique appelée BNF Sampling. BNF force le modèle à sortir dans des formats spécifiés (par exemple, JSON ou Markdown avec des champs spécifiés) en limitant les jetons suivants possibles parmi lesquels le modèle peut choisir.
Voici un exemple BNF pour JSON avec des champs "nom", "âge" et "travail":
<start> ::= <json_object>
<json_object> ::= "{" <object_members> "}"
<object_members> ::= <json_member> | <json_member> ", " <object_members>
<json_member> ::= <json_key> ": " <json_value>
<json_key> ::= '"' "name" '"' | '"' "age" '"' | '"' "job" '"'
<json_value> ::= <json_string> | <json_number>
<json_string>::='"'<content>'"'
<content>::=<except!([escaped_literals])>|<except!([escaped_literals])><content>|'\"'<content>|'\"'
<escaped_literals>::='t'|'n'|'r'|'"'
<json_number> ::= <positive_digit><digits>|'0'
<digits>::=<digit>|<digit><digits>
<digit>::='0'|<positive_digit>
<positive_digit>::="1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"
text_completions et chat_completions batch serve int8 NF4 LoRA LoRA Nous recherchons toujours des personnes intéressées à nous aider à améliorer le projet. Si vous êtes intéressé par l'un des éléments suivants, veuillez vous joindre à nous!
Peu importe votre niveau de compétence, nous vous invitons à vous joindre à nous. Vous pouvez vous joindre à nous de la manière suivante:
Nous avons hâte de travailler avec vous pour améliorer ce projet! Nous espérons que le projet vous sera utile!
Merci à ces personnes formidables qui sont perspicaces et exceptionnelles pour leur soutien et leur dévouement altruiste au projet!
顾真牛 ? ? ? ? | 研究社交 ? ? ? ? | JOSC146 ? ? ? | L15y ? ? | Cahya Wirawan ? | yuunnn_w | Longzou ? ️ |
luoqiqi |


