ai00_server
v0.5.9

AI00 RWKV Server ist ein Inferenz-API-Server für das RWKV Sprachmodell basierend auf der web-rwkv Inferenz-Engine.
Es unterstützt Vulkan parallel und gleichzeitig, stapelte Schlussfolgerung und kann auf allen GPUs laufen, die Vulkan unterstützen. Keine Notwendigkeit für Nvidia -Karten !!! AMD -Karten und sogar integrierte Grafiken können beschleunigt werden !!!
Sie sind keine sperrigen pytorch , CUDA und anderen Laufzeitumgebungen erforderlich, es ist kompakt und bereit, aus der Schachtel zu verwenden!
Kompatibel mit OpenAs Chatgpt -API -Schnittstelle.
100% Open Source und kommerziell verwendbar, unter der MIT -Lizenz.
Wenn Sie nach einem schnellen, effizienten und benutzerfreundlichen LLM-API-Server suchen, ist AI00 RWKV Server Ihre beste Wahl. Es kann für verschiedene Aufgaben verwendet werden, einschließlich Chatbots, Textgenerierung, Übersetzung und Q & A.
Treten Sie jetzt der AI00 RWKV Server Community bei und erleben Sie den Charme von AI!
QQ -Gruppe für Kommunikation: 30920262
RWKV -Modell hat es eine hohe Leistung und GenauigkeitVulkan -Inferenz, Sie können eine GPU -Beschleunigung genießen, ohne dass CUDA erforderlich ist! Unterstützt AMD -Karten, integrierte Grafiken und alle GPUs, die Vulkan unterstützenpytorch , CUDA und anderen Laufzeitumgebungen erforderlich, es ist kompakt und bereit, aus der Schachtel zu verwenden!Laden Sie die neueste Version direkt von der Veröffentlichung herunter
Nach dem Herunterladen des Modells das Modell in die assets/models/ Pfad platzieren, z assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Optional ändern Sie assets/configs/Config.toml für Modellkonfigurationen wie Modellpfad, Quantisierungsebenen usw.
In der Befehlszeile ausführen
$ ./ai00_rwkv_server Öffnen Sie den Browser und besuchen Sie das Webui unter http: // localhost: 65530 (https: // localhost: 65530 Wenn tls aktiviert ist)
Rost einbauen
Klonen Sie dieses Repository
$ git clone https://github.com/cgisky1980/ai00_rwkv_server.git
$ cd ai00_rwkv_server Nach dem Herunterladen des Modells das Modell in die assets/models/ Pfad platzieren, z assets/models/RWKV-x060-World-3B-v2-20240228-ctx4096.st
Kompilieren
$ cargo build --releaseNach der Zusammenstellung laufen
$ cargo run --release Öffnen Sie den Browser und besuchen Sie das Webui unter http: // localhost: 65530 (https: // localhost: 65530 Wenn tls aktiviert ist)
Es unterstützt nur Safetensor -Modelle mit der .st -Erweiterung jetzt. Modelle, die mit der .pth -Erweiterung mit Torch gespeichert sind, müssen vor der Verwendung konvertiert werden.
Laden Sie das .pth -Modell herunter
(Empfohlen) Führen Sie das Python -Skript convert2ai00.py oder convert_safetensors.py : PY:
$ python ./convert2ai00.py --input /path/to/model.pth --output /path/to/model.st Anforderungen: Python mit installierter torch und safetensors .
Wenn Sie Python nicht installieren möchten, können Sie in der Version eine ausführbare Datei namens converter finden. Laufen
$ ./converter --input /path/to/model.pth --output /path/to/model.st$ cargo run --release --package converter -- --input /path/to/model.pth --output /path/to/model.st.st -Modell in die assets/models/ Pfad und ändern Sie den Modellpfad in assets/configs/Config.toml --config : Dateipfad konfigurieren (Standard: assets/configs/Config.toml )--ip : Die IP-Adresse, an die der Server gebunden ist--port : Port ausführen Der API -Dienst startet in Port 65530, und das Dateneingangs- und Ausgangsformat folgt der OpenAI -API -Spezifikation. Beachten Sie, dass einige APIs wie chat und completions zusätzliche optionale Felder für erweiterte Funktionen haben. Besuchen Sie http: // localhost: 65530/api-docs für API-Schema.
/api/oai/v1/models/api/oai/models/api/oai/v1/chat/completions/api/oai/chat/completions/api/oai/v1/completions/api/oai/completions/api/oai/v1/embeddings/api/oai/embeddingsDas Folgende ist ein Beispiel außerhalb des Boxs für AI00-API-Aufrufe in Python:
import openai
class Ai00 :
def __init__ ( self , model = "model" , port = 65530 , api_key = "JUSTSECRET_KEY" ) :
openai . api_base = f"http://127.0.0.1: { port } /api/oai"
openai . api_key = api_key
self . ctx = []
self . params = {
"system_name" : "System" ,
"user_name" : "User" ,
"assistant_name" : "Assistant" ,
"model" : model ,
"max_tokens" : 4096 ,
"top_p" : 0.6 ,
"temperature" : 1 ,
"presence_penalty" : 0.3 ,
"frequency_penalty" : 0.3 ,
"half_life" : 400 ,
"stop" : [ ' x00 ' , ' n n ' ]
}
def set_params ( self , ** kwargs ):
self . params . update ( kwargs )
def clear_ctx ( self ):
self . ctx = []
def get_ctx ( self ):
return self . ctx
def continuation ( self , message ):
response = openai . Completion . create (
model = self . params [ 'model' ],
prompt = message ,
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = response . choices [ 0 ]. text
return result
def append_ctx ( self , role , content ):
self . ctx . append ({
"role" : role ,
"content" : content
})
def send_message ( self , message , role = "user" ):
self . ctx . append ({
"role" : role ,
"content" : message
})
result = openai . ChatCompletion . create (
model = self . params [ 'model' ],
messages = self . ctx ,
names = {
"system" : self . params [ 'system_name' ],
"user" : self . params [ 'user_name' ],
"assistant" : self . params [ 'assistant_name' ]
},
max_tokens = self . params [ 'max_tokens' ],
half_life = self . params [ 'half_life' ],
top_p = self . params [ 'top_p' ],
temperature = self . params [ 'temperature' ],
presence_penalty = self . params [ 'presence_penalty' ],
frequency_penalty = self . params [ 'frequency_penalty' ],
stop = self . params [ 'stop' ]
)
result = result . choices [ 0 ]. message [ 'content' ]
self . ctx . append ({
"role" : "assistant" ,
"content" : result
})
return result
ai00 = Ai00 ()
ai00 . set_params (
max_tokens = 4096 ,
top_p = 0.55 ,
temperature = 2 ,
presence_penalty = 0.3 ,
frequency_penalty = 0.8 ,
half_life = 400 ,
stop = [ ' x00 ' , ' n n ' ]
)
print ( ai00 . send_message ( "how are you?" ))
print ( ai00 . send_message ( "me too!" ))
print ( ai00 . get_ctx ())
ai00 . clear_ctx ()
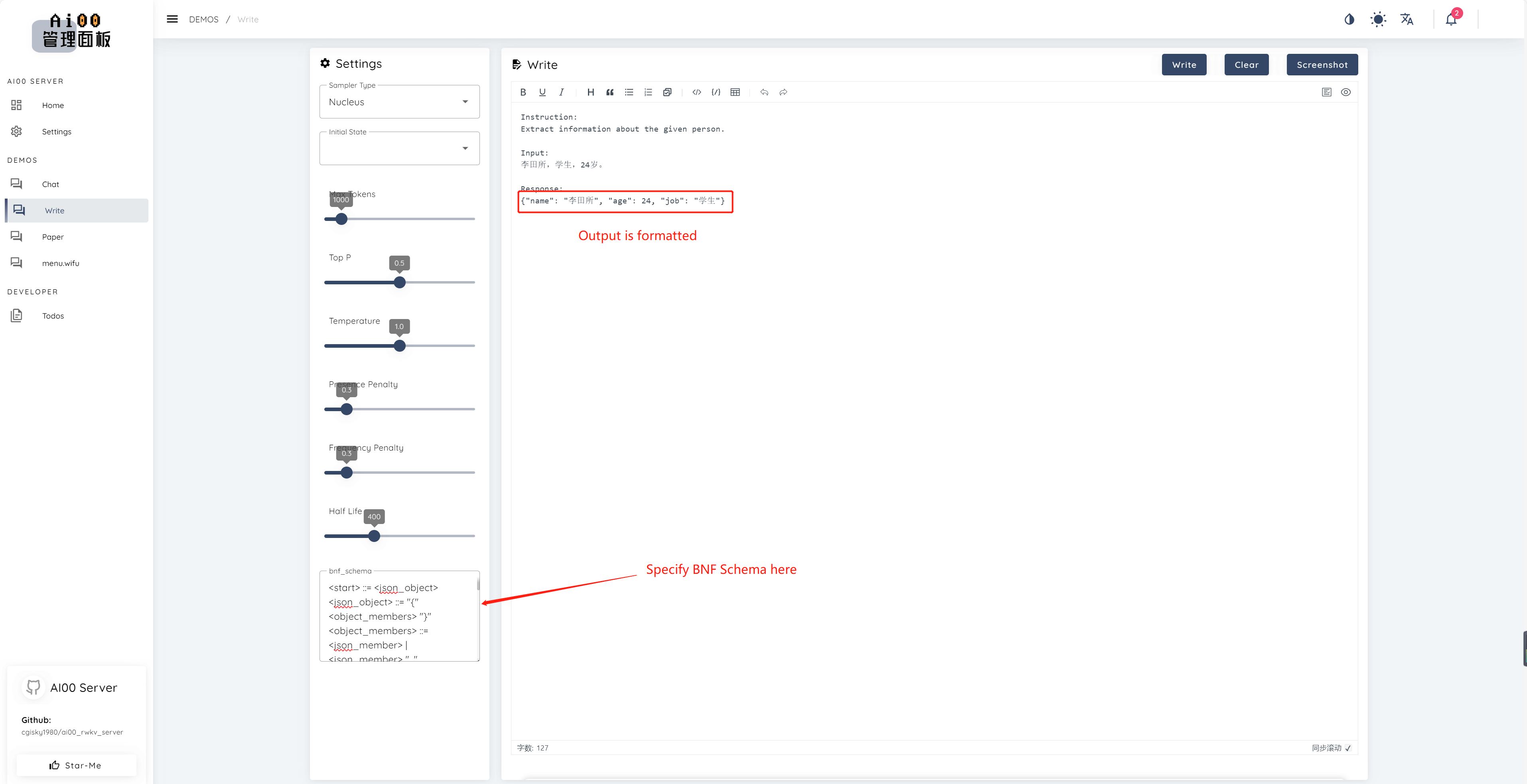
print ( ai00 . continuation ( "i like" ))Seit V0.5 verfügt AI00 über eine einzigartige Funktion namens BNF -Abtastung. BNF zwingt das Modell, in bestimmten Formaten (z. B. JSON oder Markdown mit bestimmten Feldern) auszugeben, indem er die möglichen Next -Stuken, aus denen das Modell auswählen kann, begrenzt.
Hier ist ein Beispiel BNF für JSON mit Feldern "Name", "Alter" und "Job":
<start> ::= <json_object>
<json_object> ::= "{" <object_members> "}"
<object_members> ::= <json_member> | <json_member> ", " <object_members>
<json_member> ::= <json_key> ": " <json_value>
<json_key> ::= '"' "name" '"' | '"' "age" '"' | '"' "job" '"'
<json_value> ::= <json_string> | <json_number>
<json_string>::='"'<content>'"'
<content>::=<except!([escaped_literals])>|<except!([escaped_literals])><content>|'\"'<content>|'\"'
<escaped_literals>::='t'|'n'|'r'|'"'
<json_number> ::= <positive_digit><digits>|'0'
<digits>::=<digit>|<digit><digits>
<digit>::='0'|<positive_digit>
<positive_digit>::="1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"
text_completions und chat_completions batch serve int8 -Quantisierung NF4 -Quantisierung LoRA -Modell LoRA -Modells Wir sind immer auf der Suche nach Menschen, die uns helfen möchten, das Projekt zu verbessern. Wenn Sie an einem der folgenden interessiert sind, besuchen Sie uns bitte!
Unabhängig von Ihrem Qualifikationsniveau begrüßen wir Sie, um sich uns anzuschließen. Sie können sich uns auf folgende Weise anschließen:
Wir können es kaum erwarten, mit Ihnen zusammenzuarbeiten, um dieses Projekt besser zu machen! Wir hoffen, das Projekt ist für Sie hilfreich!
Vielen Dank an diese großartigen Personen, die für ihre Unterstützung und ihr selbstloses Engagement für das Projekt aufschlussreich und hervorragend sind!
顾真牛 ? ? ? ? | 研究社交 ? ? ? ? | JOSC146 ? ? ? | l15y ? ? | Cahya Wirawan ? | yuunnn_w | Longzou ? Euen |
luoqiqi |


