The editor of Downcodes learned that research teams from Shanghai Jiao Tong University and Harvard University have recently launched a new model fine-tuning method called LoRA-Dash. This method can still achieve the same fine-tuning effect as the existing LoRA method even though the number of parameters is reduced by 8 to 16 times, bringing breakthrough progress to fine-tuning tasks with limited computing resources. The core of LoRA-Dash lies in the strict definition and utilization of "Task Specific Directions" (TSD). Through the two stages of "pre-launch" and "sprint", TSD is efficiently identified and utilized for model optimization. This will undoubtedly greatly improve the efficiency of model fine-tuning and provide strong support for related research.
Recently, a research team from Shanghai Jiao Tong University and Harvard University launched a new model fine-tuning method-LoRA-Dash. This new method claims to be more efficient than the existing LoRA method, especially in fine-tuning for specific tasks. It can achieve the same effect while reducing the number of parameters by 8 to 16 times. This is undoubtedly a major breakthrough for fine-tuning tasks that require large amounts of computing resources.
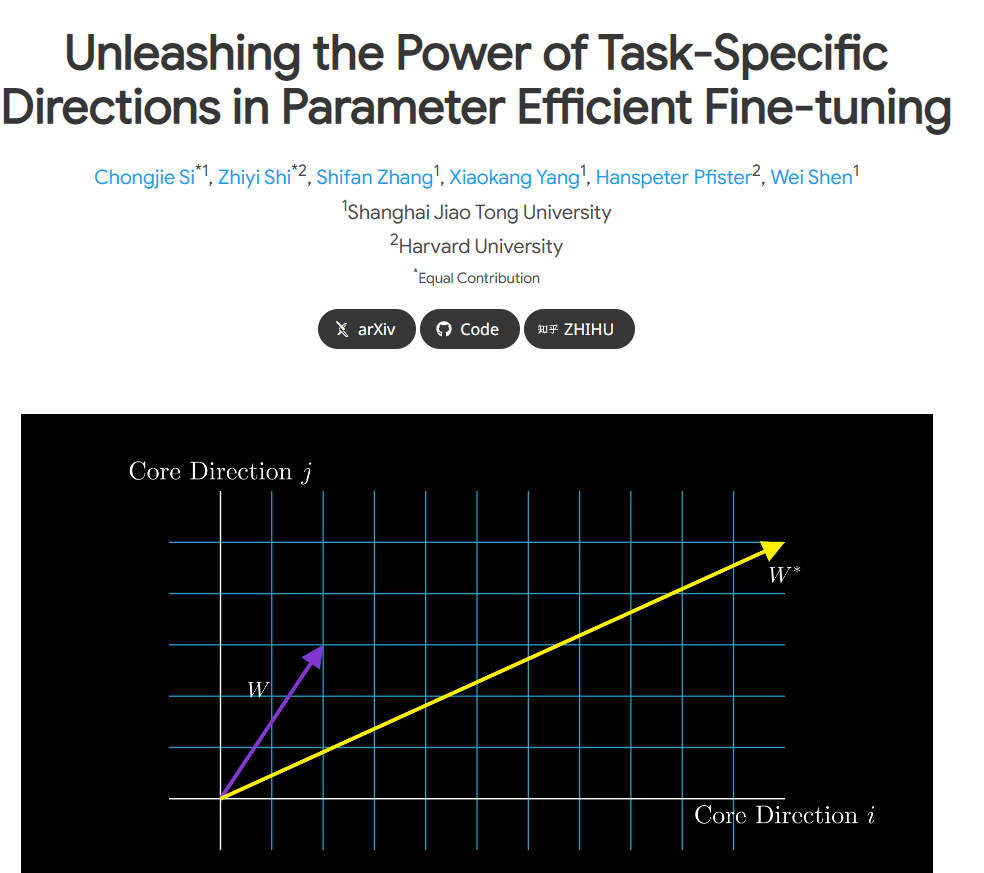
In the context of the rapid development of large-scale language models, there is an increasing need to fine-tune specific tasks. However, fine-tuning often consumes a lot of computing resources. In order to solve this problem, the research team introduced the parameter efficient fine-tuning (PEFT) strategy, and LoRA is a typical example. Through experiments, it was found that LoRA mainly achieves fine-tuning effects by capturing some features that have been learned in pre-training and amplifying them.
However, the original LoRA paper has some ambiguities in the definition of "task-specific direction" (TSD). The research team conducted an in-depth analysis, rigorously defined TSD for the first time and clarified its nature. TSD represents the core direction of significant changes in model parameters during fine-tuning.

To unleash the potential of TSD in practical applications, researchers proposed LoRA-Dash, a method that consists of two key stages. The first stage is the "pre-start stage", when the specific direction of the task needs to be identified; the second stage is the "sprint stage", where the previously identified directions are used to optimize and adjust the model to better adapt to the specific task.
Experiments show that LoRA-Dash surpasses the performance of LoRA on multiple tasks, such as achieving significant performance improvements in tasks such as common sense reasoning, natural language understanding, and agent-driven generation. This result shows the effectiveness of TSD in downstream tasks and fully unleashes the potential of efficient fine-tuning.
At present, relevant research papers have been made public and the code has been open source. The research team hopes to provide support to more researchers and developers so that everyone can be more efficient in the process of fine-tuning the model.
Project entrance: https://chongjiesi.site/project/2024-lora-dash.html
** Highlights: **
**LoRA-Dash method launched:** A new model fine-tuning method, LoRA-Dash, came into being. Compared with LoRA, it is more efficient and requires significantly less computing power.
** Clarify task-specific direction:** The research team strictly defined "task-specific direction" (TSD) and clarified its importance in the fine-tuning process.
** Notable experimental results: ** Experiments show that LoRA-Dash outperforms LoRA in common sense reasoning, natural language understanding and other tasks, demonstrating the huge potential of efficient fine-tuning.
The emergence of LoRA-Dash has brought new hope to the field of model fine-tuning. Its high efficiency and precise grasp of specific task directions are expected to promote the development of AI model training in a more efficient and lower-cost direction. We look forward to LoRA-Dash being able to demonstrate its superior performance in more practical applications in the future and contribute to the advancement of artificial intelligence technology.