L'éditeur de Downcodes a appris que des équipes de recherche de l'Université Jiao Tong de Shanghai et de l'Université Harvard ont récemment lancé une nouvelle méthode de réglage fin du modèle appelée LoRA-Dash. Cette méthode peut toujours produire le même effet de réglage fin que la méthode LoRA existante, même si le nombre de paramètres est réduit de 8 à 16 fois, apportant ainsi des progrès révolutionnaires dans le réglage fin des tâches avec des ressources informatiques limitées. Le cœur de LoRA-Dash réside dans la définition et l'utilisation strictes des « instructions spécifiques aux tâches » (TSD). À travers les deux étapes de « pré-lancement » et de « sprint », les TSD sont identifiées et utilisées efficacement pour l'optimisation du modèle. Cela améliorera sans aucun doute considérablement l’efficacité du réglage fin du modèle et fournira un soutien solide aux recherches connexes.
Récemment, une équipe de recherche de l'Université Jiao Tong de Shanghai et de l'Université Harvard a lancé une nouvelle méthode de réglage fin du modèle : LoRA-Dash. Cette nouvelle méthode prétend être plus efficace que la méthode LoRA existante, notamment pour le réglage fin de tâches spécifiques. Elle peut obtenir le même effet tout en réduisant le nombre de paramètres de 8 à 16 fois. Il s’agit sans aucun doute d’une avancée majeure pour la mise au point de tâches nécessitant de grandes quantités de ressources informatiques.
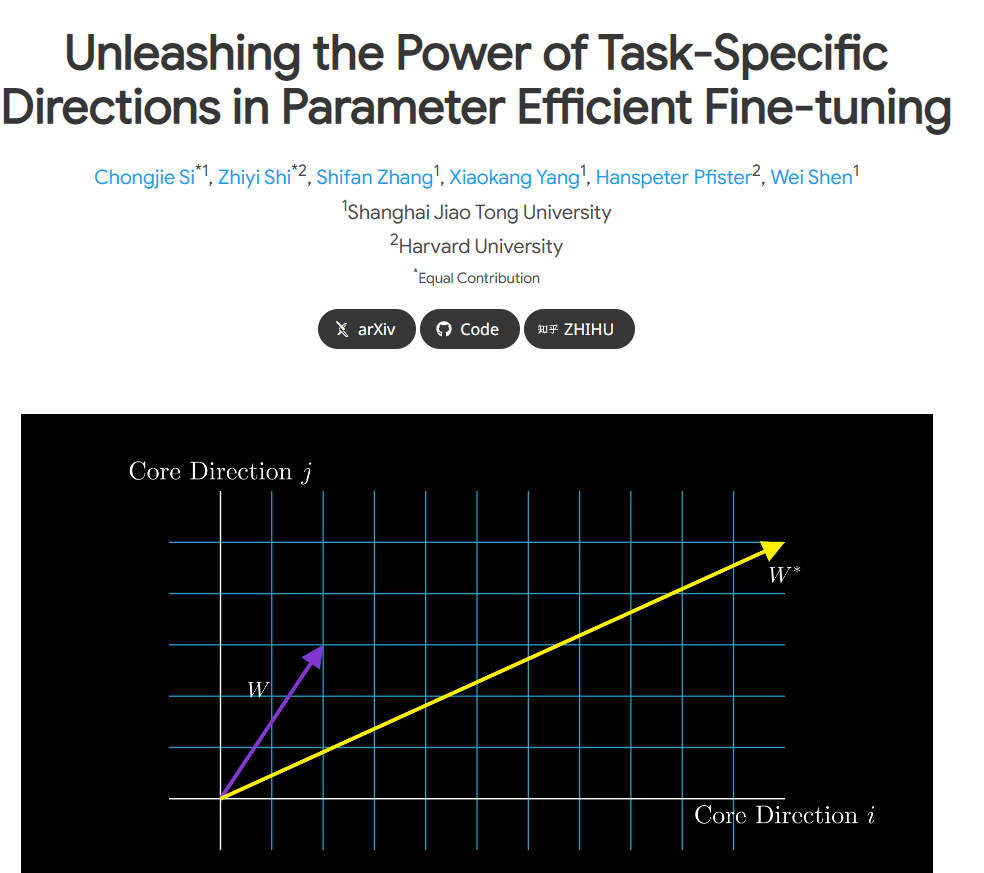
Dans le contexte du développement rapide de modèles de langage à grande échelle, il devient de plus en plus nécessaire d’affiner des tâches spécifiques. Cependant, le réglage fin consomme souvent beaucoup de ressources informatiques. Afin de résoudre ce problème, l’équipe de recherche a introduit la stratégie de réglage fin efficace des paramètres (PEFT), et LoRA en est un exemple typique. Grâce à des expériences, il a été constaté que LoRA obtient principalement des effets de réglage fin en capturant certaines fonctionnalités apprises lors de la pré-formation et en les amplifiant.
Cependant, le document original de LoRA présente certaines ambiguïtés dans la définition de la « direction spécifique à une tâche » (TSD). L’équipe de recherche a mené une analyse approfondie, a défini rigoureusement le TSD pour la première fois et a clarifié sa nature. TSD représente la direction centrale des changements significatifs dans les paramètres du modèle lors du réglage fin.

Pour libérer le potentiel du TSD dans des applications pratiques, les chercheurs ont proposé LoRA-Dash, une méthode composée de deux étapes clés. La première étape est la « étape de pré-démarrage », lorsque la direction spécifique de la tâche doit être identifiée ; la deuxième étape est la « étape de sprint », où les directions précédemment identifiées sont utilisées pour optimiser et ajuster le modèle afin de mieux s'adapter. à la tâche spécifique.
Les expériences montrent que LoRA-Dash surpasse les performances de LoRA sur plusieurs tâches, par exemple en obtenant des améliorations significatives des performances dans des tâches telles que le raisonnement de bon sens, la compréhension du langage naturel et la génération pilotée par des agents. Ce résultat montre l’efficacité du TSD dans les tâches en aval et libère pleinement le potentiel d’un réglage fin efficace.
À l'heure actuelle, des documents de recherche pertinents ont été rendus publics et le code est open source. L'équipe de recherche espère soutenir davantage de chercheurs et de développeurs afin que chacun puisse être plus efficace dans le processus d'ajustement du modèle.
Entrée du projet : https://chongjiesi.site/project/2024-lora-dash.html
** Points forts: **
**Méthode LoRA-Dash lancée :** Une nouvelle méthode de réglage fin du modèle, LoRA-Dash, a vu le jour. Par rapport à LoRA, elle est plus efficace et nécessite beaucoup moins de puissance de calcul.
** Clarifier l'orientation spécifique à la tâche :** L'équipe de recherche a strictement défini la « direction spécifique à la tâche » (TSD) et a clarifié son importance dans le processus de réglage fin.
** Résultats expérimentaux notables : ** Les expériences montrent que LoRA-Dash surpasse LoRA en matière de raisonnement de bon sens, de compréhension du langage naturel et d'autres tâches, démontrant l'énorme potentiel d'un réglage fin efficace.
L'émergence de LoRA-Dash a apporté un nouvel espoir dans le domaine du réglage fin des modèles. Sa grande efficacité et sa compréhension précise d'orientations de tâches spécifiques devraient promouvoir le développement de la formation de modèles d'IA dans une direction plus efficace et moins coûteuse. Nous attendons avec impatience que LoRA-Dash puisse démontrer ses performances supérieures dans des applications plus pratiques à l'avenir et contribuer à l'avancement de la technologie de l'intelligence artificielle.