O editor do Downcodes aprendeu que equipes de pesquisa da Universidade Jiao Tong de Xangai e da Universidade de Harvard lançaram recentemente um novo método de ajuste fino de modelo chamado LoRA-Dash. Este método ainda pode alcançar o mesmo efeito de ajuste fino que o método LoRA existente, mesmo que o número de parâmetros seja reduzido de 8 a 16 vezes, trazendo um progresso inovador para tarefas de ajuste fino com recursos computacionais limitados. O núcleo do LoRA-Dash reside na definição e utilização rigorosas de "Direções Específicas de Tarefas" (TSD). Através dos dois estágios de "pré-lançamento" e "sprint", o TSD é identificado e utilizado de forma eficiente para otimização do modelo. Isto irá, sem dúvida, melhorar muito a eficiência do ajuste fino do modelo e fornecer um forte apoio à investigação relacionada.
Recentemente, uma equipe de pesquisa da Universidade Jiao Tong de Xangai e da Universidade de Harvard lançou um novo modelo de método de ajuste fino - LoRA-Dash. Este novo método afirma ser mais eficiente do que o método LoRA existente, especialmente no ajuste fino para tarefas específicas. Ele pode alcançar o mesmo efeito enquanto reduz o número de parâmetros em 8 a 16 vezes. Este é, sem dúvida, um grande avanço para tarefas de ajuste fino que requerem grandes quantidades de recursos computacionais.
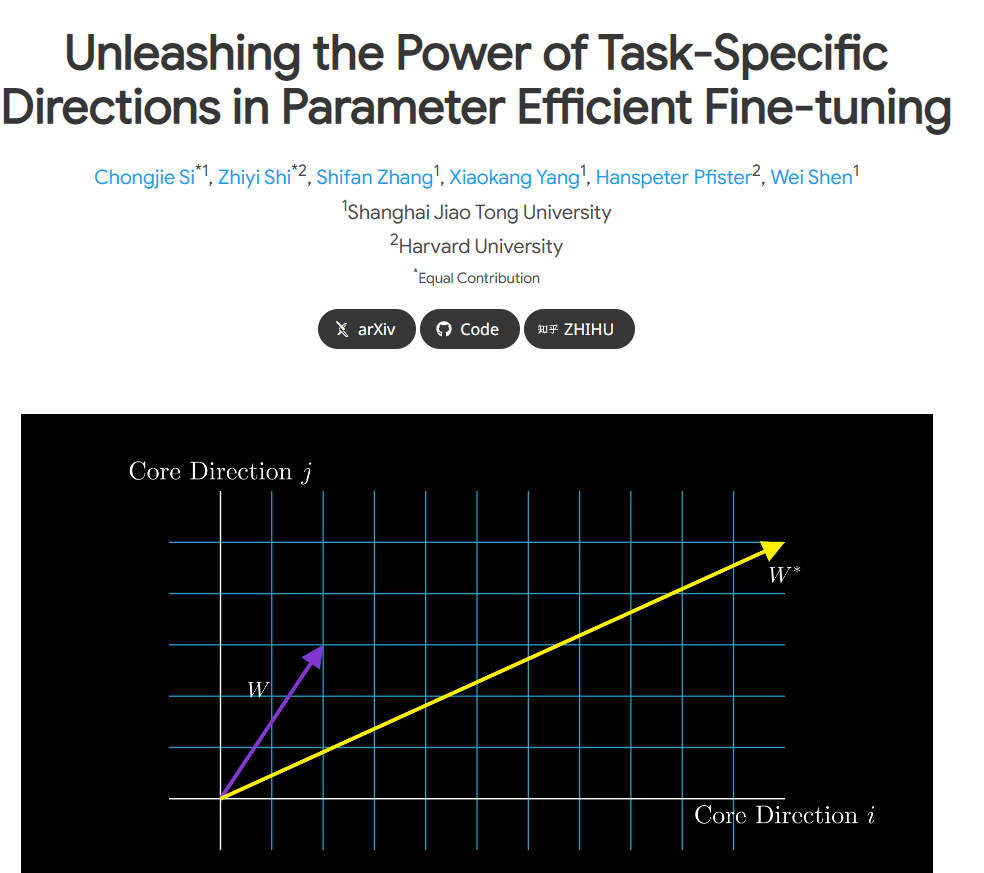
No contexto do rápido desenvolvimento de modelos de linguagem em larga escala, há uma necessidade crescente de aperfeiçoar tarefas específicas. No entanto, o ajuste fino geralmente consome muitos recursos computacionais. Para resolver este problema, a equipe de pesquisa introduziu a estratégia de ajuste fino eficiente de parâmetros (PEFT), e LoRA é um exemplo típico. Através de experimentos, descobriu-se que o LoRA alcança principalmente efeitos de ajuste fino, capturando alguns recursos que foram aprendidos no pré-treinamento e amplificando-os.
No entanto, o artigo original da LoRA apresenta algumas ambigüidades na definição de “direção específica da tarefa” (TSD). A equipa de investigação realizou uma análise aprofundada, definiu rigorosamente o TSD pela primeira vez e clarificou a sua natureza. O TSD representa a direção central de mudanças significativas nos parâmetros do modelo durante o ajuste fino.

Para liberar o potencial do TSD em aplicações práticas, os pesquisadores propuseram o LoRA-Dash, um método que consiste em duas etapas principais. A primeira etapa é a “etapa pré-início”, quando é necessário identificar a direção específica da tarefa; a segunda etapa é a “etapa sprint”, onde as direções previamente identificadas são utilizadas para otimizar e ajustar o modelo para melhor adaptação; para a tarefa específica.
Experimentos mostram que LoRA-Dash supera o desempenho do LoRA em múltiplas tarefas, como alcançar melhorias significativas de desempenho em tarefas como raciocínio de bom senso, compreensão de linguagem natural e geração orientada por agente. Este resultado mostra a eficácia do TSD em tarefas posteriores e libera totalmente o potencial de um ajuste fino eficiente.
Atualmente, artigos de pesquisa relevantes foram divulgados e o código é de código aberto. A equipe de pesquisa espera fornecer suporte a mais pesquisadores e desenvolvedores para que todos possam ser mais eficientes no processo de ajuste fino do modelo.
Entrada do projeto: https://chongjiesi.site/project/2024-lora-dash.html
** Destaques: **
**Método LoRA-Dash lançado:** Um novo modelo de método de ajuste fino, LoRA-Dash, surgiu em comparação com LoRA, é mais eficiente e requer significativamente menos poder de computação.
** Esclarecer a direção específica da tarefa:** A equipe de pesquisa definiu estritamente a "direção específica da tarefa" (TSD) e esclareceu sua importância no processo de ajuste fino.
** Resultados experimentais notáveis: ** Experimentos mostram que LoRA-Dash supera LoRA em raciocínio de bom senso, compreensão de linguagem natural e outras tarefas, demonstrando o enorme potencial de ajuste fino eficiente.
O surgimento do LoRA-Dash trouxe uma nova esperança ao campo do ajuste fino de modelos. Espera-se que sua alta eficiência e compreensão precisa de direções de tarefas específicas promovam o desenvolvimento do treinamento de modelos de IA em uma direção mais eficiente e de menor custo. Esperamos que o LoRA-Dash possa demonstrar seu desempenho superior em aplicações mais práticas no futuro e contribuir para o avanço da tecnologia de inteligência artificial.