علم محرر Downcodes أن فرق البحث من جامعة شنغهاي جياو تونغ وجامعة هارفارد أطلقت مؤخرًا طريقة جديدة لضبط النموذج تسمى LoRA-Dash. لا يزال بإمكان هذه الطريقة تحقيق نفس تأثير الضبط الدقيق مثل طريقة LoRA الحالية على الرغم من تقليل عدد المعلمات بمقدار 8 إلى 16 مرة، مما يحقق تقدمًا كبيرًا في مهام الضبط الدقيق بموارد حوسبة محدودة. يكمن جوهر LoRA-Dash في التعريف الصارم واستخدام "التوجيهات المحددة للمهمة" (TSD) من خلال مرحلتي "الإطلاق المسبق" و"السباق السريع"، ويتم تحديد TSD بكفاءة واستخدامها لتحسين النموذج. سيؤدي هذا بلا شك إلى تحسين كفاءة الضبط الدقيق للنموذج بشكل كبير وتوفير دعم قوي للأبحاث ذات الصلة.
في الآونة الأخيرة، أطلق فريق بحث من جامعة شنغهاي جياو تونغ وجامعة هارفارد نموذجًا جديدًا لطريقة الضبط الدقيق -LoRA-Dash. تدعي هذه الطريقة الجديدة أنها أكثر كفاءة من طريقة LoRA الحالية، خاصة في الضبط الدقيق لمهام محددة، ويمكنها تحقيق نفس التأثير مع تقليل عدد المعلمات بمقدار 8 إلى 16 مرة. يعد هذا بلا شك إنجازًا كبيرًا في تحسين المهام التي تتطلب كميات كبيرة من موارد الحوسبة.
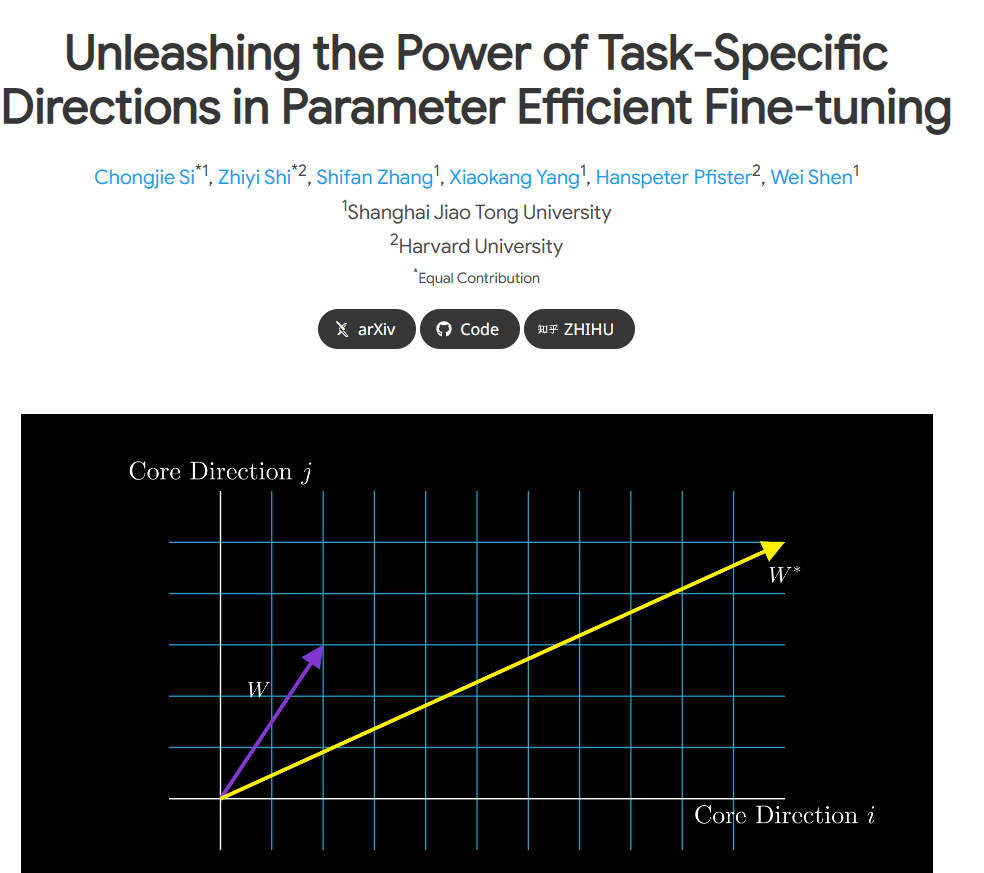
في سياق التطور السريع لنماذج اللغة واسعة النطاق، هناك حاجة متزايدة لضبط مهام محددة. ومع ذلك، غالبًا ما يستهلك الضبط الدقيق الكثير من موارد الحوسبة. من أجل حل هذه المشكلة، قدم فريق البحث استراتيجية الضبط الدقيق بكفاءة المعلمة (PEFT)، ويعتبر LoRA مثالًا نموذجيًا. من خلال التجارب، وجد أن LoRA تحقق بشكل أساسي تأثيرات الضبط الدقيق من خلال التقاط بعض الميزات التي تم تعلمها في التدريب المسبق وتضخيمها.
ومع ذلك، فإن ورقة LoRA الأصلية بها بعض الغموض في تعريف "الاتجاه الخاص بالمهمة" (TSD). أجرى فريق البحث تحليلًا متعمقًا وحدد TSD بدقة لأول مرة وأوضح طبيعته. يمثل TSD الاتجاه الأساسي للتغيرات المهمة في معلمات النموذج أثناء الضبط الدقيق.

لإطلاق العنان لإمكانات TSD في التطبيقات العملية، اقترح الباحثون LoRA-Dash، وهي طريقة تتكون من مرحلتين رئيسيتين. المرحلة الأولى هي "مرحلة ما قبل البدء"، عندما يلزم تحديد الاتجاه المحدد للمهمة، والمرحلة الثانية هي "مرحلة الركض"، حيث يتم استخدام الاتجاهات المحددة مسبقًا لتحسين النموذج وضبطه للتكيف بشكل أفضل إلى المهمة المحددة.
تظهر التجارب أن LoRA-Dash يتفوق على أداء LoRA في مهام متعددة، مثل تحقيق تحسينات كبيرة في الأداء في مهام مثل التفكير المنطقي وفهم اللغة الطبيعية والتوليد القائم على الوكيل. تُظهر هذه النتيجة فعالية TSD في المهام النهائية وتطلق العنان بالكامل لإمكانات الضبط الدقيق الفعال.
في الوقت الحاضر، تم نشر الأوراق البحثية ذات الصلة، وأصبح الكود مفتوح المصدر. ويأمل فريق البحث في تقديم الدعم لمزيد من الباحثين والمطورين حتى يتمكن الجميع من أن يكونوا أكثر كفاءة في عملية ضبط النموذج.
مدخل المشروع: https://chongjiesi.site/project/2024-lora-dash.html
** أبرز النقاط: **
**تم إطلاق طريقة LoRA-Dash:** ظهرت إلى حيز الوجود طريقة جديدة للضبط الدقيق للنموذج، LoRA-Dash، مقارنة بـ LoRA، وهي أكثر كفاءة وتتطلب طاقة حاسوبية أقل بكثير.
** توضيح الاتجاه الخاص بالمهمة: ** حدد فريق البحث بدقة "الاتجاه الخاص بالمهمة" (TSD) وأوضح أهميته في عملية الضبط الدقيق.
** نتائج تجريبية ملحوظة: ** تظهر التجارب أن LoRA-Dash يتفوق على LoRA في التفكير المنطقي وفهم اللغة الطبيعية والمهام الأخرى، مما يدل على الإمكانات الهائلة للضبط الدقيق الفعال.
جلب ظهور LoRA-Dash أملًا جديدًا في مجال الضبط الدقيق للنموذج، ومن المتوقع أن تؤدي كفاءته العالية وفهمه الدقيق لاتجاهات المهام المحددة إلى تعزيز تطوير التدريب على نماذج الذكاء الاصطناعي في اتجاه أكثر كفاءة وأقل تكلفة. ونحن نتطلع إلى أن تتمكن LoRA-Dash من إظهار أدائها المتفوق في المزيد من التطبيقات العملية في المستقبل والمساهمة في تقدم تكنولوجيا الذكاء الاصطناعي.