PromptRank
1.0.0
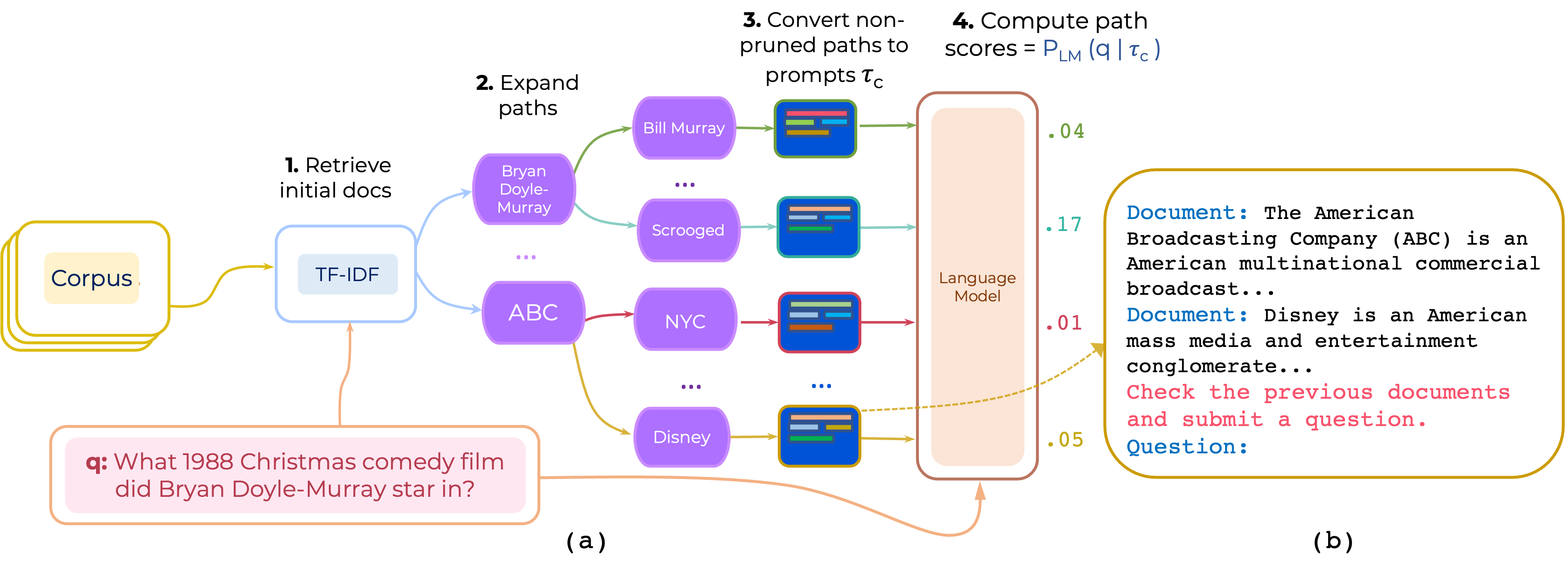
เราเสนอวิธีการสำหรับการจัดอันดับเอกสารหลายเส้นทางของ Multi-Hop อีกครั้งและไม่กี่ครั้งสำหรับ QA แบบเปิดโดเมน Promptrank สร้างพรอมต์ที่ประกอบด้วย (i) คำสั่ง และ (ii) เส้นทาง และใช้ LLM เพื่อให้คะแนนเส้นทางเป็นความน่าจะเป็นในการสร้างคำถามที่ได้รับพรอมต์
ดาวน์โหลด TF-IDF Retriever และฐานข้อมูลสำหรับ hotpotqa ที่จัดทำโดย pathretriever จากลิงค์นี้และวางเนื้อหาใน path-retriever/models
pip install -r requirements.txt
ข้อมูลที่ประมวลผล HotPotQA และ 2Wikimqa สามารถดาวน์โหลดได้จาก [Google Drive] ข้อมูลจะถูกประมวลผลล่วงหน้าโดยการดึงบทความ TF-IDF 200 ข้อบนเพื่อการอนุมาน (https://drive.google.com/file/d/1mi7xadhwlhlw6fmow3ljqmpipsmlnp67/view?usp=share_link) จากนั้นคลายซิปข้อมูลและวางเนื้อหาไว้ใน data/
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--instruction_template_file instruction-templates/top_instructions.txt
--ensemble_prompts
สิ่งนี้ใช้คำแนะนำ 10 อันดับแรกที่พบผ่าน hotpotqa ซึ่งอยู่ใน instruction-templates/top_instructions.txt :
Document : < P > Review previous documents and ask some question . Question
Document : < P > Review the previous documents and answer question . Question :
Document : < P > Read the previous documents and write the following question . Question :
Document : < P > Search previous documents and ask the question . Question :
To analyze the documents and ask question . Document : < P > Question :
Document : < P > To read the previous documents and write a question . Question :
Document : < P > Read previous documents and write your exam question . Question :
Document : < P > Read the previous documents and ask this question . Question :
Read two documents and answer a question . Document : < P > Question :
Identify all documents and ask question . Document : < P > Question : python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
--n_ensemble_demos 3
หมายเหตุ: รหัสรองรับการเรียนการสอนหรือการสาธิตวงดนตรี - ไม่ใช่ทั้งสองอย่าง
เราใช้ส่วนประกอบมากมายจาก Pathretriever ขอบคุณ Akari Asai และคนอื่น ๆ ที่ให้รหัสและรุ่นของพวกเขา
หากคุณใช้รหัสนี้โปรดพิจารณาอ้างถึงบทความของเรา:
@article{promptrank,
title={Few-shot Reranking for Multi-hop QA via Language Model Prompting},
author={Khalifa, Muhammad and Logeswaran, Lajanugen and Lee, Moontae and Lee, Honglak and Wang, Lu},
journal={arXiv preprint arXiv:2205.12650},
year={2023}
}


