PromptRank
1.0.0
Propomos uma abordagem para a renúncia zero e com poucas fotos de caminhos de documentos de vários saltos para o controle de qualidade de domínio aberto. O PROMPTRANK constrói um aviso que consiste em (i) uma instrução e (ii) o caminho e usa um LLM para marcar caminhos como probabilidade de gerar a pergunta, dado o prompt.
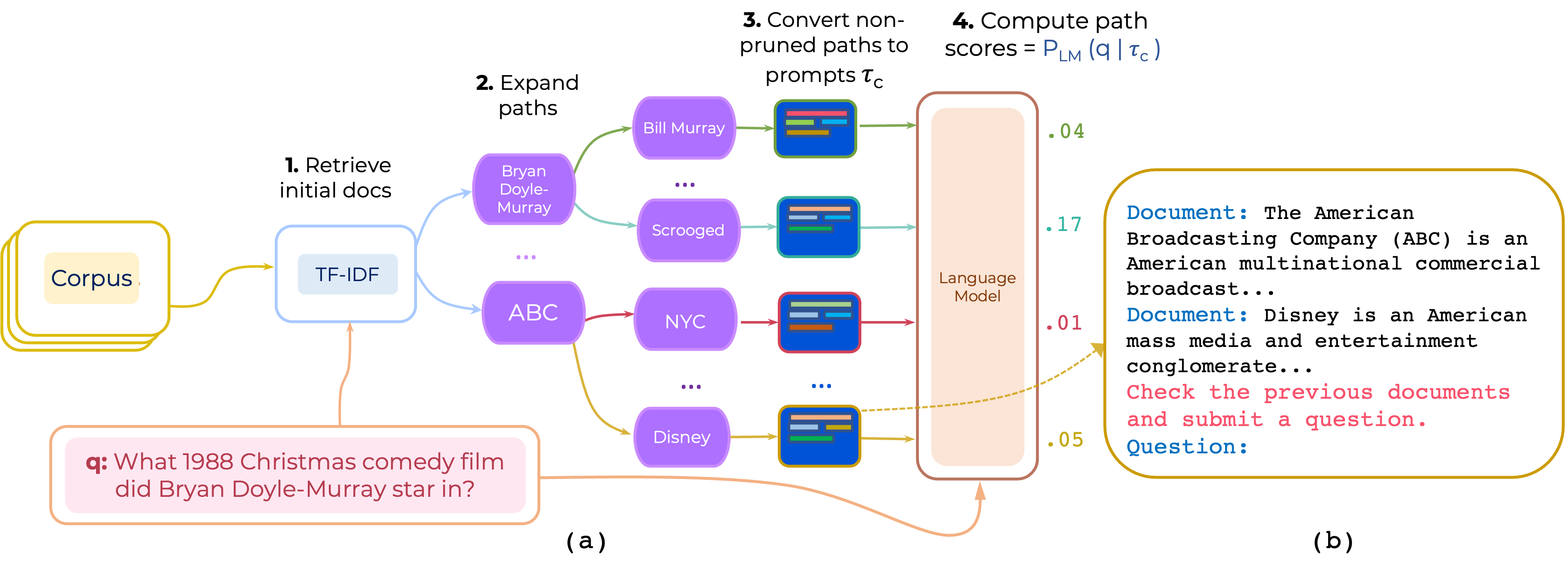
Baixe o TF-IDF Retriever e o banco de dados para HotpotQA fornecido pela Pathretriever a partir deste link e coloque seu conteúdo no path-retriever/models
pip install -r requirements.txt
Os dados processados do HotpotQA e 2WikIMQA podem ser baixados do [Google Drive] Os dados são pré-processados, recuperando 200 artigos principais TF-IDF para semear a inferência. (https://drive.google.com/file/d/1mi7xadhwlhlw6fmow3ljqmpipsmlnp67/view?usp=share_link). Em seguida, descompacte os dados e coloque o conteúdo em data/
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--instruction_template_file instruction-templates/top_instructions.txt
--ensemble_prompts
Isso usa as 10 principais instruções encontradas sobre o HotpotQA que estão em instruction-templates/top_instructions.txt :
Document : < P > Review previous documents and ask some question . Question
Document : < P > Review the previous documents and answer question . Question :
Document : < P > Read the previous documents and write the following question . Question :
Document : < P > Search previous documents and ask the question . Question :
To analyze the documents and ask question . Document : < P > Question :
Document : < P > To read the previous documents and write a question . Question :
Document : < P > Read previous documents and write your exam question . Question :
Document : < P > Read the previous documents and ask this question . Question :
Read two documents and answer a question . Document : < P > Question :
Identify all documents and ask question . Document : < P > Question : python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
--n_ensemble_demos 3
NOTA: O código suporta um conjunto de instruções ou um conjunto de demonstrações - não ambos.
Usamos muitos componentes do Pathretriever. Então, obrigado a Akari Aseai e a outros por fornecer seu código e modelos.
Se você usar este código, considere citar nosso artigo:
@article{promptrank,
title={Few-shot Reranking for Multi-hop QA via Language Model Prompting},
author={Khalifa, Muhammad and Logeswaran, Lajanugen and Lee, Moontae and Lee, Honglak and Wang, Lu},
journal={arXiv preprint arXiv:2205.12650},
year={2023}
}


