PromptRank
1.0.0
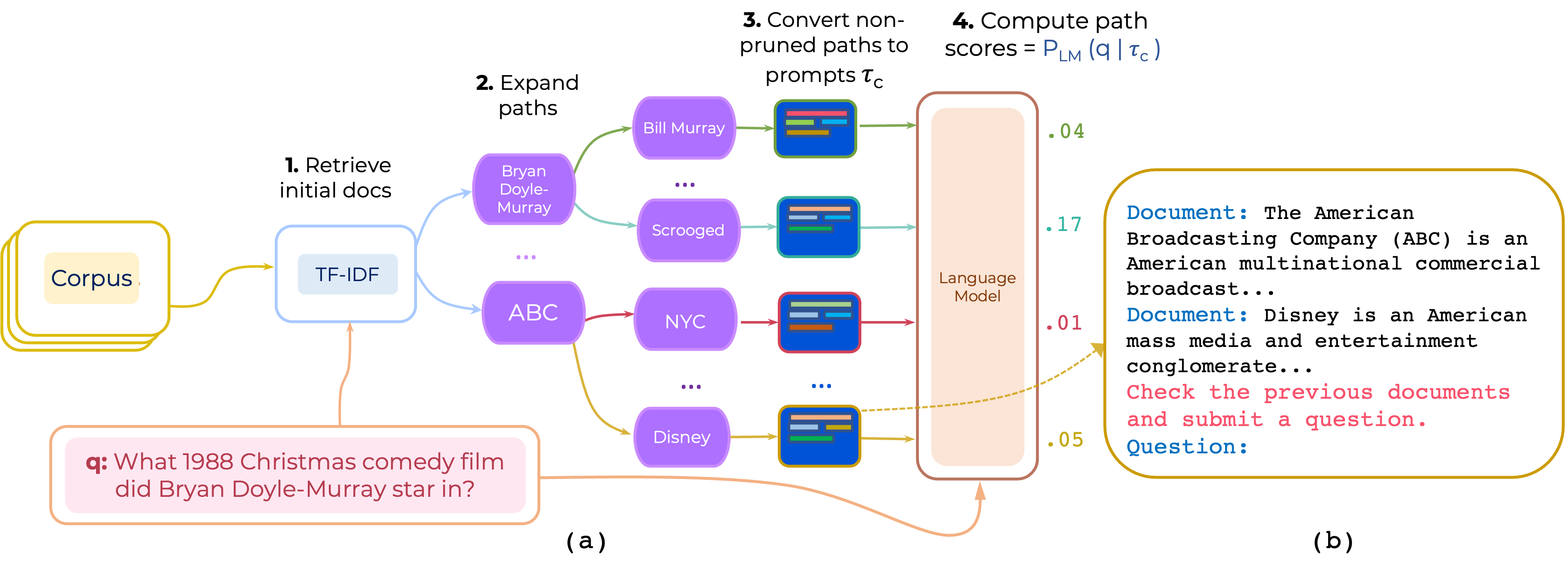
Nous proposons une approche pour la relance à zéro et à quelques coups des chemins de document multi-HOP pour le QA à domaine ouvert. PromPtrank construit une invite qui consiste en (i) une instruction et (ii) le chemin et utilise un LLM pour marquer des chemins comme probabilité de générer la question étant donné l'invite.
Téléchargez le TF-IDF Retriever et la base de données pour Hotpotqa fournie par PathRetriever à partir de ce lien et placer son contenu dans path-retriever/models
pip install -r requirements.txt
Les données traitées HotpotQA et 2WikIMQA peuvent être téléchargées à partir de [Google Drive] Les données sont prétraitées en récupérant 200 meilleurs articles TF-IDF pour assembler l'inférence. (https://drive.google.com/file/d/1mi7xadhwlhlw6fmow3ljqmpipsmlnp67/view?usp=share_link). Ensuite, décompressez les données et placez le contenu dans data/
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--instruction_template_file instruction-templates/top_instructions.txt
--ensemble_prompts
Cela utilise les 10 meilleures instructions trouvées sur hotpotqa qui sont en instruction-templates/top_instructions.txt :
Document : < P > Review previous documents and ask some question . Question
Document : < P > Review the previous documents and answer question . Question :
Document : < P > Read the previous documents and write the following question . Question :
Document : < P > Search previous documents and ask the question . Question :
To analyze the documents and ask question . Document : < P > Question :
Document : < P > To read the previous documents and write a question . Question :
Document : < P > Read previous documents and write your exam question . Question :
Document : < P > Read the previous documents and ask this question . Question :
Read two documents and answer a question . Document : < P > Question :
Identify all documents and ask question . Document : < P > Question : python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
--n_ensemble_demos 3
Remarque: Le code prend en charge l'ensemble d'instructions ou l'ensemble de démonstration - pas les deux.
Nous utilisons de nombreux composants de PathRetriever. Merci donc à Akari Asai et à d'autres pour avoir fourni leur code et leurs modèles.
Si vous utilisez ce code, veuillez envisager de citer notre papier:
@article{promptrank,
title={Few-shot Reranking for Multi-hop QA via Language Model Prompting},
author={Khalifa, Muhammad and Logeswaran, Lajanugen and Lee, Moontae and Lee, Honglak and Wang, Lu},
journal={arXiv preprint arXiv:2205.12650},
year={2023}
}


