PromptRank
1.0.0
Wir schlagen einen Ansatz für die Wiederholung von Multi-Hop-Dokumentpfaden für die Open-Domain-QA vor. PromPtrank konstruiert eine Eingabeaufforderung, die aus (i) einer Anweisung und (ii) dem Pfad besteht und ein LLM verwendet, um Pfade als Wahrscheinlichkeit zu bewerten, die Frage angesichts der Eingabeaufforderung zu erstellen.
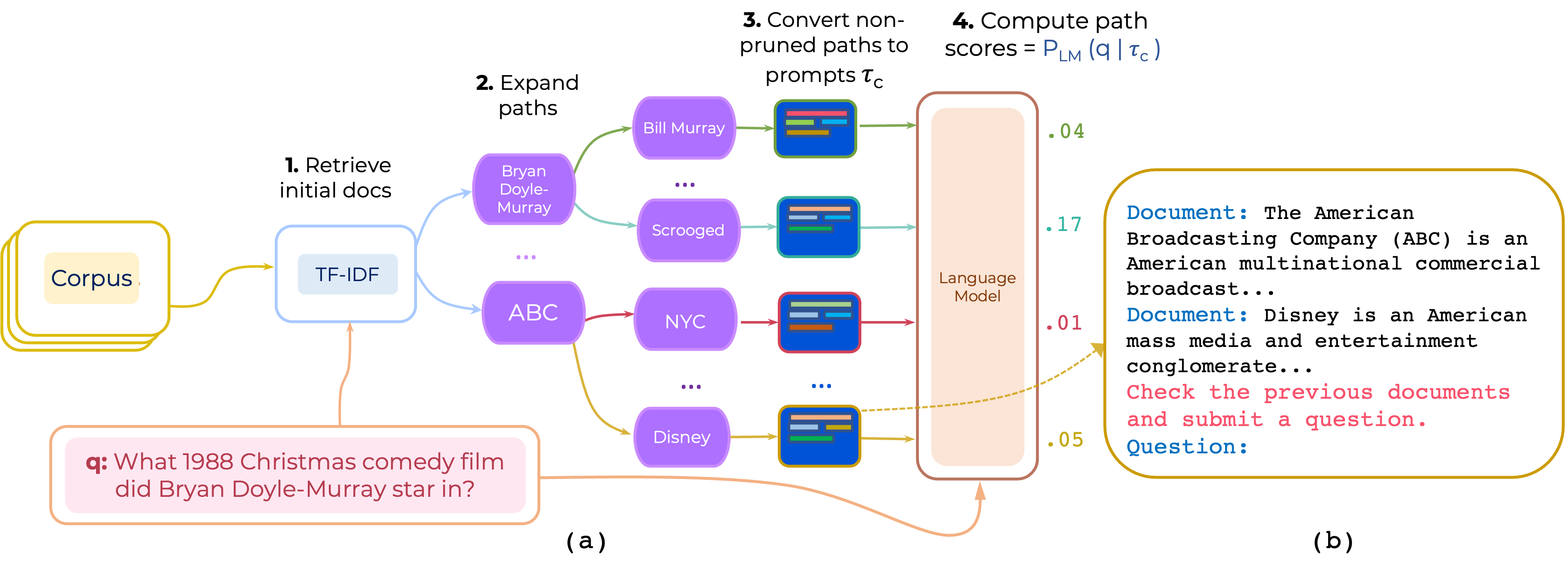
Laden Sie den von PathRetriever bereitgestellten TF-IDF Retriever und Datenbank für path-retriever/models von diesem Link herunter und platzieren
pip install -r requirements.txt
Die verarbeiteten Daten von Hotpotqa und 2Wikimqa können von [Google Drive] heruntergeladen werden. (https://drive.google.com/file/d/1mi7xadhwlHlw6fmow3ljqmpipsMlnp67/view?usp=share_Link). Entpacken Sie dann die Daten und platzieren Sie den Inhalt in data/
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--instruction_template_file instruction-templates/top_instructions.txt
--ensemble_prompts
Damit werden die Top 10 Anweisungen über HotpotQA verwendet, die sich in instruction-templates/top_instructions.txt :
Document : < P > Review previous documents and ask some question . Question
Document : < P > Review the previous documents and answer question . Question :
Document : < P > Read the previous documents and write the following question . Question :
Document : < P > Search previous documents and ask the question . Question :
To analyze the documents and ask question . Document : < P > Question :
Document : < P > To read the previous documents and write a question . Question :
Document : < P > Read previous documents and write your exam question . Question :
Document : < P > Read the previous documents and ask this question . Question :
Read two documents and answer a question . Document : < P > Question :
Identify all documents and ask question . Document : < P > Question : python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
--n_ensemble_demos 3
HINWEIS: Der Code unterstützt entweder Anleitungssemblassen oder Demonstrationsersembling - nicht beides.
Wir verwenden viele Komponenten von PathRetriever. Vielen Dank an Akari Asai und andere für die Bereitstellung ihrer Code und Modelle.
Wenn Sie diesen Code verwenden, erwägen Sie bitte unser Papier zitieren:
@article{promptrank,
title={Few-shot Reranking for Multi-hop QA via Language Model Prompting},
author={Khalifa, Muhammad and Logeswaran, Lajanugen and Lee, Moontae and Lee, Honglak and Wang, Lu},
journal={arXiv preprint arXiv:2205.12650},
year={2023}
}


