PromptRank
1.0.0
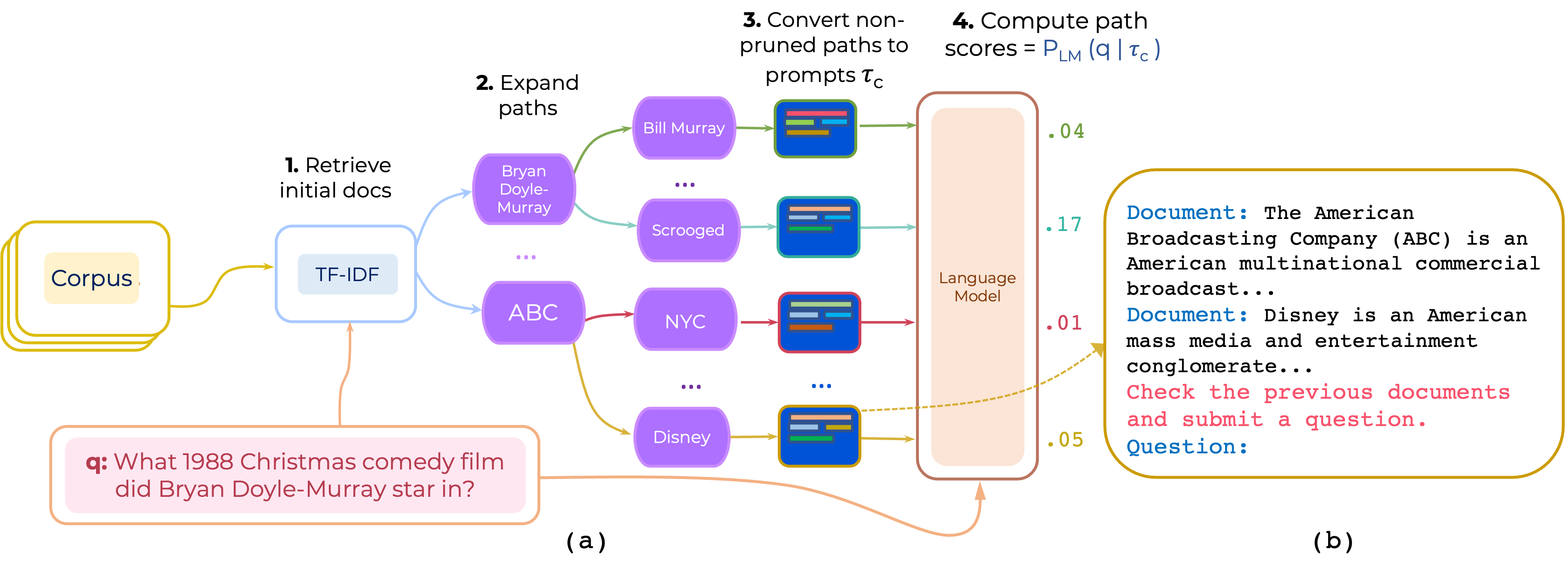
Proponemos un enfoque para el reanimiento de cero y pocos disparos de rutas de documentos de salto múltiple para QA de dominio abierto. Promptrank construye un mensaje que consiste en (i) una instrucción y (ii) la ruta y usa una LLM para obtener rutas como probabilidad de generar la pregunta dada el aviso.
Descargue el TF-IDF Retriever y la base de datos para HotPotqa proporcionado por PathRetriever desde este enlace y coloque su contenido en path-retriever/models
pip install -r requirements.txt
Los datos procesados de HotPotqa y 2Wikimqa se pueden descargar de [Google Drive] Los datos se preprocesan recuperando 200 artículos TF-IDF principales para sembrar una inferencia. (https://drive.google.com/file/d/1mi7xadhwlhlw6fmow3ljqmpipsmlnp67/view?usp=share_link). Luego descomprima los datos y coloque el contenido en data/
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--instruction_template_file instruction-templates/top_instructions.txt
--ensemble_prompts
Esto utiliza las 10 instrucciones principales que se encuentran sobre hotpotqa que están en instruction-templates/top_instructions.txt :
Document : < P > Review previous documents and ask some question . Question
Document : < P > Review the previous documents and answer question . Question :
Document : < P > Read the previous documents and write the following question . Question :
Document : < P > Search previous documents and ask the question . Question :
To analyze the documents and ask question . Document : < P > Question :
Document : < P > To read the previous documents and write a question . Question :
Document : < P > Read previous documents and write your exam question . Question :
Document : < P > Read the previous documents and ask this question . Question :
Read two documents and answer a question . Document : < P > Question :
Identify all documents and ask question . Document : < P > Question : python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
--n_ensemble_demos 3
Nota: El código admite un conjunto de instrucciones o en conjunto de demostración, no ambos.
Usamos muchos componentes de PathRetriever. Así que gracias a Akari Asai y otros por proporcionar su código y modelos.
Si usa este código, considere citar nuestro documento:
@article{promptrank,
title={Few-shot Reranking for Multi-hop QA via Language Model Prompting},
author={Khalifa, Muhammad and Logeswaran, Lajanugen and Lee, Moontae and Lee, Honglak and Wang, Lu},
journal={arXiv preprint arXiv:2205.12650},
year={2023}
}


