PromptRank
1.0.0
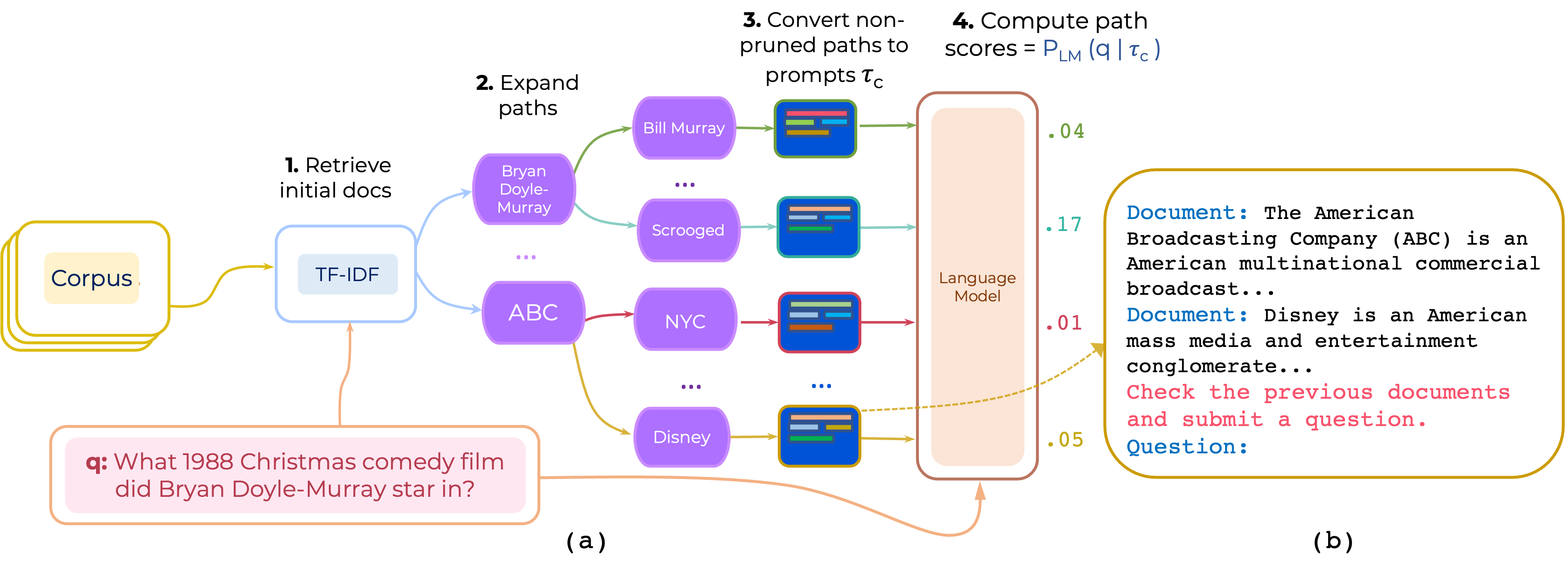
Open-Domain QA에 대한 멀티 홉 문서 경로의 제로 및 소수의 재 순위에 대한 접근법을 제안합니다. PrompTrank는 (i) 명령 및 (ii) 경로 로 구성된 프롬프트를 구성하고 LLM을 사용하여 프롬프트가 주어진 질문을 생성 할 확률로 경로를 점수를줍니다.
이 링크에서 PathRetriever가 제공 한 HotpotQa의 TF-IDF 리트리버 및 데이터베이스를 다운로드하고 컨텐츠를 path-retriever/models 에 배치하십시오.
pip install -r requirements.txt
Hotpotqa 및 2wikimqa 처리 된 데이터는 [Google Drive]에서 다운로드 할 수 있습니다. 200 대 TF-IDF 기사를 검색하여 추론을 시드로 검색하여 데이터가 전처리됩니다. (https://drive.google.com/file/d/1mi7xadhwlhlw6fmow3ljqmpipsmlnp67/view?usp=share_link). 그런 다음 데이터를 압축하고 컨텐츠를 data/
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--instruction_template_file instruction-templates/top_instructions.txt
--ensemble_prompts
이것은 instruction-templates/top_instructions.txt 에있는 Hotpotqa를 통해 발견 된 상위 10 가지 지침을 사용합니다.
Document : < P > Review previous documents and ask some question . Question
Document : < P > Review the previous documents and answer question . Question :
Document : < P > Read the previous documents and write the following question . Question :
Document : < P > Search previous documents and ask the question . Question :
To analyze the documents and ask question . Document : < P > Question :
Document : < P > To read the previous documents and write a question . Question :
Document : < P > Read previous documents and write your exam question . Question :
Document : < P > Read the previous documents and ask this question . Question :
Read two documents and answer a question . Document : < P > Question :
Identify all documents and ask question . Document : < P > Question : python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
--n_ensemble_demos 3
참고 : 이 코드는 교육 앙상블 또는 데모 앙상블을 지원합니다.
우리는 Pathretriever의 많은 구성 요소를 사용합니다. 따라서 코드와 모델을 제공해 주신 Akari Asai와 다른 사람들에게 감사드립니다.
이 코드를 사용하는 경우 본 논문을 인용하는 것을 고려하십시오.
@article{promptrank,
title={Few-shot Reranking for Multi-hop QA via Language Model Prompting},
author={Khalifa, Muhammad and Logeswaran, Lajanugen and Lee, Moontae and Lee, Honglak and Wang, Lu},
journal={arXiv preprint arXiv:2205.12650},
year={2023}
}


