PromptRank
1.0.0
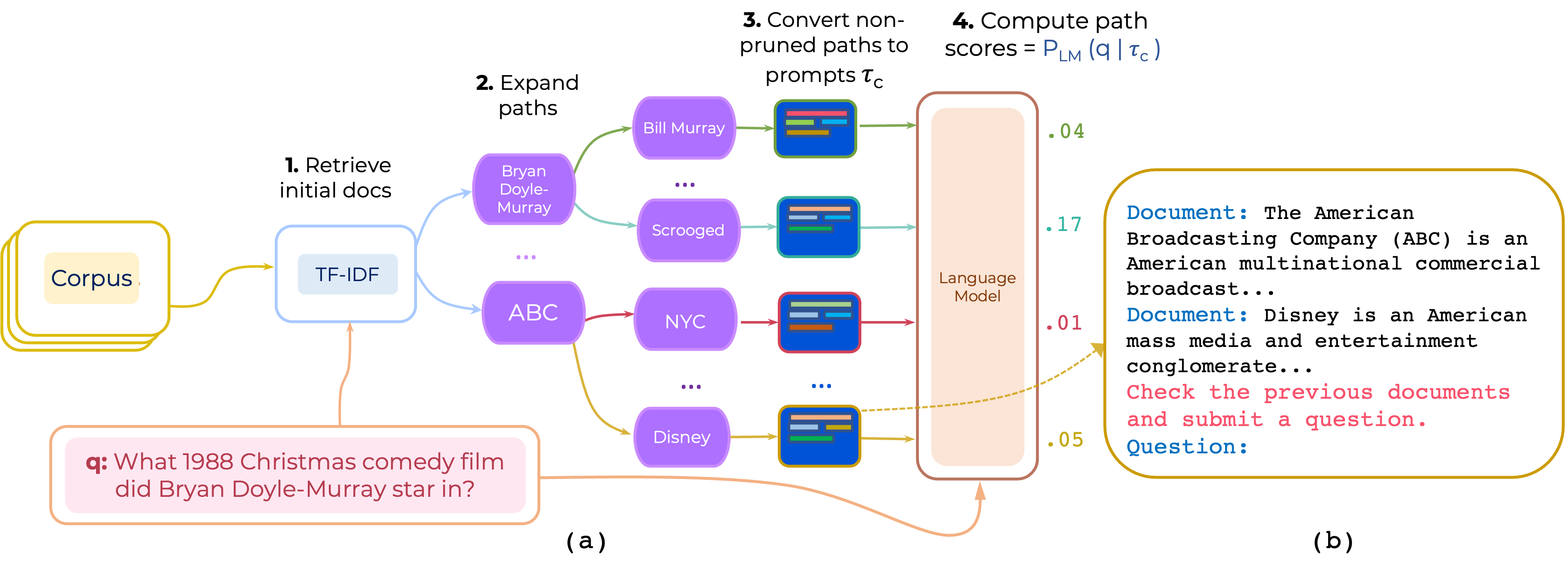
Мы предлагаем подход для повторного ранжирования многоугольных путей документов для QA с открытым доменом. PRESTTRANK строит подсказку, которая состоит из (i) инструкции и (ii) пути и использует LLM для оценки пути как вероятность генерирования вопроса, учитывая подсказку.
Загрузите TF-IDF Retriever и базу данных для HotPotqa, предоставленного Pathretriver по этой ссылке, и поместите его содержимое в path-retriever/models
pip install -r requirements.txt
Обработанные данные HotPotqa и 2wikimqa могут быть загружены из [Google Drive] Данные предварительно обработаны путем извлечения 200 лучших статей TF-IDF для вывода вывода. (https://drive.google.com/file/d/1mi7xadhwlhlw6fmow3ljqmpipsmlnp67/view?usp=share_link). Затем расстегните разарки данных и поместите его в data/
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--instruction_template_file instruction-templates/top_instructions.txt
--ensemble_prompts
Это использует 10 лучших инструкций, найденных по Hotpotqa, которые находятся в instruction-templates/top_instructions.txt :
Document : < P > Review previous documents and ask some question . Question
Document : < P > Review the previous documents and answer question . Question :
Document : < P > Read the previous documents and write the following question . Question :
Document : < P > Search previous documents and ask the question . Question :
To analyze the documents and ask question . Document : < P > Question :
Document : < P > To read the previous documents and write a question . Question :
Document : < P > Read previous documents and write your exam question . Question :
Document : < P > Read the previous documents and ask this question . Question :
Read two documents and answer a question . Document : < P > Question :
Identify all documents and ask question . Document : < P > Question : python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
--n_ensemble_demos 3
ПРИМЕЧАНИЕ. Код поддерживает либо ансамбляцию инструкций, либо демонстрационное ансаммент - не оба.
Мы используем много компонентов от Pathretriver. Так что благодаря Акари Асаи и другим за предоставление их кода и моделей.
Если вы используете этот код, рассмотрите возможность ссылаться на нашу статью:
@article{promptrank,
title={Few-shot Reranking for Multi-hop QA via Language Model Prompting},
author={Khalifa, Muhammad and Logeswaran, Lajanugen and Lee, Moontae and Lee, Honglak and Wang, Lu},
journal={arXiv preprint arXiv:2205.12650},
year={2023}
}


