PromptRank
1.0.0
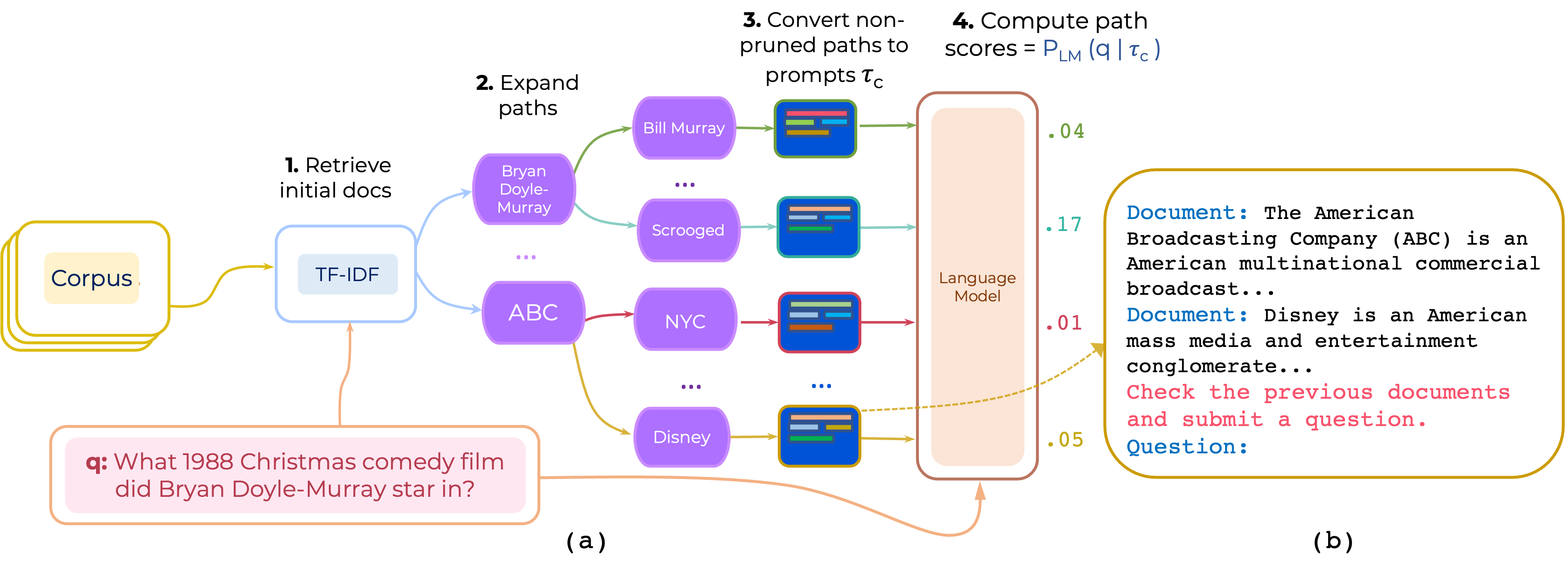
Kami mengusulkan pendekatan untuk peringkat ulang jalur dokumen multi-hop nol dan beberapa tembakan untuk QA domain terbuka. ProMPTrank membangun prompt yang terdiri dari (i) instruksi dan (ii) jalur dan menggunakan LLM untuk mencetak jalur sebagai probabilitas menghasilkan pertanyaan yang diberikan prompt.
Unduh TF-IDF Retriever dan database untuk hotpotqa yang disediakan oleh PathRetriever dari tautan ini dan tempatkan isinya di path-retriever/models
pip install -r requirements.txt
Data yang diproses HotpotQA dan 2wikimqa dapat diunduh dari [Google Drive] data ini diproses dengan mengambil 200 artikel TF-IDF teratas untuk menyemai inferensi. (https://drive.google.com/file/d/1mi7xadhwlhlw6fmow3ljqmpipsmlnp67/view?usp=share_link). Lalu unzip data dan tempatkan kontennya dalam data/
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--instruction_template_file instruction-templates/top_instructions.txt
--ensemble_prompts
Ini menggunakan 10 instruksi teratas yang ditemukan melalui hotpotqa yang ada di instruction-templates/top_instructions.txt :
Document : < P > Review previous documents and ask some question . Question
Document : < P > Review the previous documents and answer question . Question :
Document : < P > Read the previous documents and write the following question . Question :
Document : < P > Search previous documents and ask the question . Question :
To analyze the documents and ask question . Document : < P > Question :
Document : < P > To read the previous documents and write a question . Question :
Document : < P > Read previous documents and write your exam question . Question :
Document : < P > Read the previous documents and ask this question . Question :
Read two documents and answer a question . Document : < P > Question :
Identify all documents and ask question . Document : < P > Question : python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
python run.py
--model google/t5-base-lm-adapt
--eval_batch_size=50
--max_prompt_len 600
--max_doc_len 230
--tfidf_pool_size 100
--n_eval_examples 1000
--temperature 1.0
--eval_data data/hotpotqa/dev.json
--prompt_template 'Document: <P> Review previous documents and ask some question. Question:'
--demos_ids 0,1
--demos_file data/hotpotqa/in_context_demos.json
--n_ensemble_demos 3
CATATAN: Kode mendukung ensembling instruksi atau ensembling demonstrasi - bukan keduanya.
Kami menggunakan banyak komponen dari pathretriever. Jadi terima kasih kepada Akari Asai dan lainnya karena telah menyediakan kode dan model mereka.
Jika Anda menggunakan kode ini, pertimbangkan untuk mengutip makalah kami:
@article{promptrank,
title={Few-shot Reranking for Multi-hop QA via Language Model Prompting},
author={Khalifa, Muhammad and Logeswaran, Lajanugen and Lee, Moontae and Lee, Honglak and Wang, Lu},
journal={arXiv preprint arXiv:2205.12650},
year={2023}
}


