TaCL
1.0.0
ผู้เขียน : Yixuan SU, Fangyu Liu, Zaiqiao Meng, Tian Lan, Lei Shu, Ehsan Shareghi และ Nigel Collier
รหัสของบทความของเรา: tacl: การปรับปรุง Bert Pre-Training ด้วยการเรียนรู้แบบตัดกันที่รับรู้โทเค็น
[使用中文 tacl-bert 进行中文命名实体识别及中文分词教程]
แบบจำลองภาษาที่สวมหน้ากาก (MLMS) เช่น Bert และ Roberta ได้ปฏิวัติสาขาความเข้าใจภาษาธรรมชาติในช่วงไม่กี่ปีที่ผ่านมา อย่างไรก็ตาม MLM ที่ได้รับการฝึกอบรมมาก่อนมักจะส่งออกการกระจายตัวแบบแอนไอโซโทรปิกของการเป็นตัวแทนโทเค็นที่ใช้งานเซตย่อยแคบของพื้นที่การเป็นตัวแทนทั้งหมด การเป็นตัวแทนโทเค็นดังกล่าวไม่เหมาะโดยเฉพาะอย่างยิ่งสำหรับงานที่ต้องการความหมายเชิงความหมายที่เลือกปฏิบัติของโทเค็นที่แตกต่างกัน ในงานนี้เราเสนอ tacl ( t oken- a ware c ontrastive l ที่ได้รับ), วิธีการฝึกอบรมก่อนการฝึกอบรมอย่างต่อเนื่องนวนิยายที่กระตุ้นให้เบิร์ตเรียนรู้การกระจาย isotropic และการเลือกปฏิบัติของการเป็นตัวแทนโทเค็น TACL ไม่ได้รับการดูแลอย่างเต็มที่และไม่จำเป็นต้องมีข้อมูลเพิ่มเติม เราทดสอบวิธีการของเราอย่างกว้างขวางเกี่ยวกับมาตรฐานภาษาอังกฤษและภาษาจีนที่หลากหลาย ผลการวิจัยพบว่า TaCl นำการปรับปรุงที่สอดคล้องและโดดเด่นเหนือโมเดล Bert ดั้งเดิม นอกจากนี้เรายังทำการวิเคราะห์อย่างละเอียดเพื่อเปิดเผยข้อดีและการทำงานภายในของวิธีการของเรา
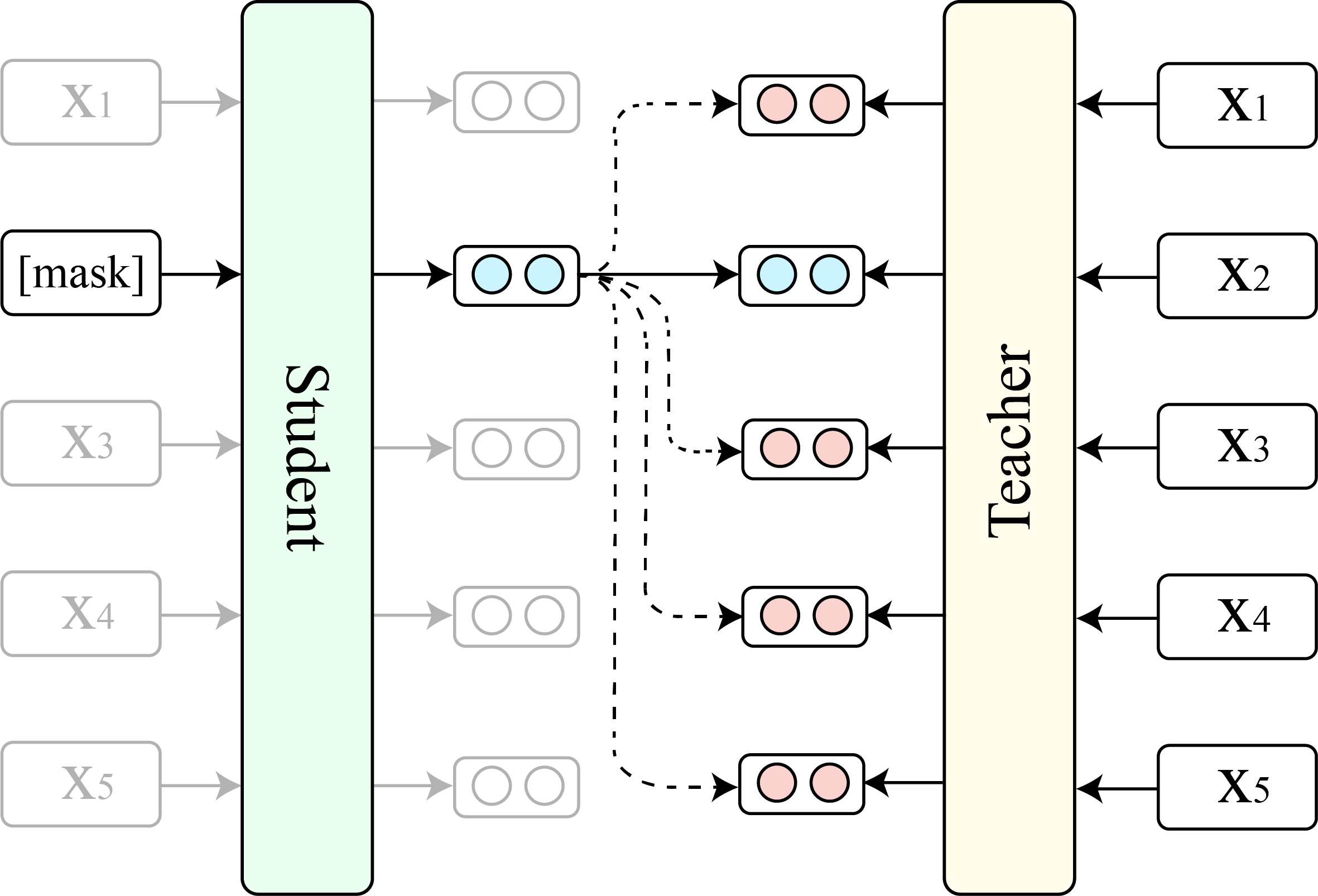
เราแสดงการเปรียบเทียบระหว่าง tacl (เวอร์ชันพื้นฐาน) และ Bert ดั้งเดิม (เวอร์ชันพื้นฐาน)
(1) ผลลัพธ์มาตรฐานภาษาอังกฤษเกี่ยวกับ ทีม (Rajpurkar et al., 2018) (ชุด Dev) และ Glue (Wang et al., 2019) คะแนนเฉลี่ย
| แบบอย่าง | ทีม 1.1 (EM/F1) | ทีม 2.0 (EM/F1) | กาวเฉลี่ย |
|---|---|---|---|
| เบิร์ต | 80.8/88.5 | 73.4/76.8 | 79.6 |
| แท็ก | 81.6/89.0 | 74.4/77.5 | 81.2 |
(2) ผลการวัดเกณฑ์มาตรฐานของจีน (ชุดทดสอบ F1) ในสี่งาน NER (MSRA, Ontonotes, Resume และ Weibo) และการแบ่งส่วนคำภาษาจีนสามครั้ง (CWS) (PKU, CityU และ AS)
| แบบอย่าง | MSRA | ontonotes | ประวัติย่อ | PKU | เมือง | เช่น | |
|---|---|---|---|---|---|---|---|
| เบิร์ต | 94.95 | 80.14 | 95.53 | 68.20 | 96.50 | 97.60 | 96.50 |
| แท็ก | 95.44 | 82.42 | 96.45 | 69.54 | 96.75 | 98.16 | 96.75 |
| ชื่อนางแบบ | ที่อยู่รุ่น |
|---|---|
| ภาษาอังกฤษ ( Cambridgeltl/tacl-bert-base-uncased ) | การเชื่อมโยง |
| ภาษาจีน ( Cambridgeltl/tacl-bert-base-chinese ) | การเชื่อมโยง |
import torch
# initialize model
from transformers import AutoModel , AutoTokenizer
model_name = 'cambridgeltl/tacl-bert-base-uncased'
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
# create input ids
text = '[CLS] clbert is awesome. [SEP]'
tokenized_token_list = tokenizer . tokenize ( text )
input_ids = torch . LongTensor ( tokenizer . convert_tokens_to_ids ( tokenized_token_list )). view ( 1 , - 1 )
# compute hidden states
representation = model ( input_ids ). last_hidden_state # [1, seqlen, embed_dim] python version : 3.8
pip3 install -r requirements.txtโปรดดูรายละเอียดที่ให้ไว้ในไดเรกทอรี./pretraining_data
โปรดดูรายละเอียดที่ให้ไว้ใน./ไดเรกทอรีการฝึกอบรม
โปรดดูรายละเอียดที่ให้ไว้ในไดเรกทอรี./english_benchmark
chmod +x ./download_benchmark_data.sh
./download_benchmark_data.sh โปรดดูรายละเอียดที่ให้ไว้ในไดเรกทอรี./chinese_benchmark
เราให้รหัสที่จำเป็นทั้งหมดเพื่อทำซ้ำผลลัพธ์ (ภาพด้านล่าง) ที่มีให้ในส่วนการวิเคราะห์ของเรา รหัสและคำแนะนำที่เกี่ยวข้องอยู่ใน./ไดเรกทอรีการวิเคราะห์ มีความสุข!
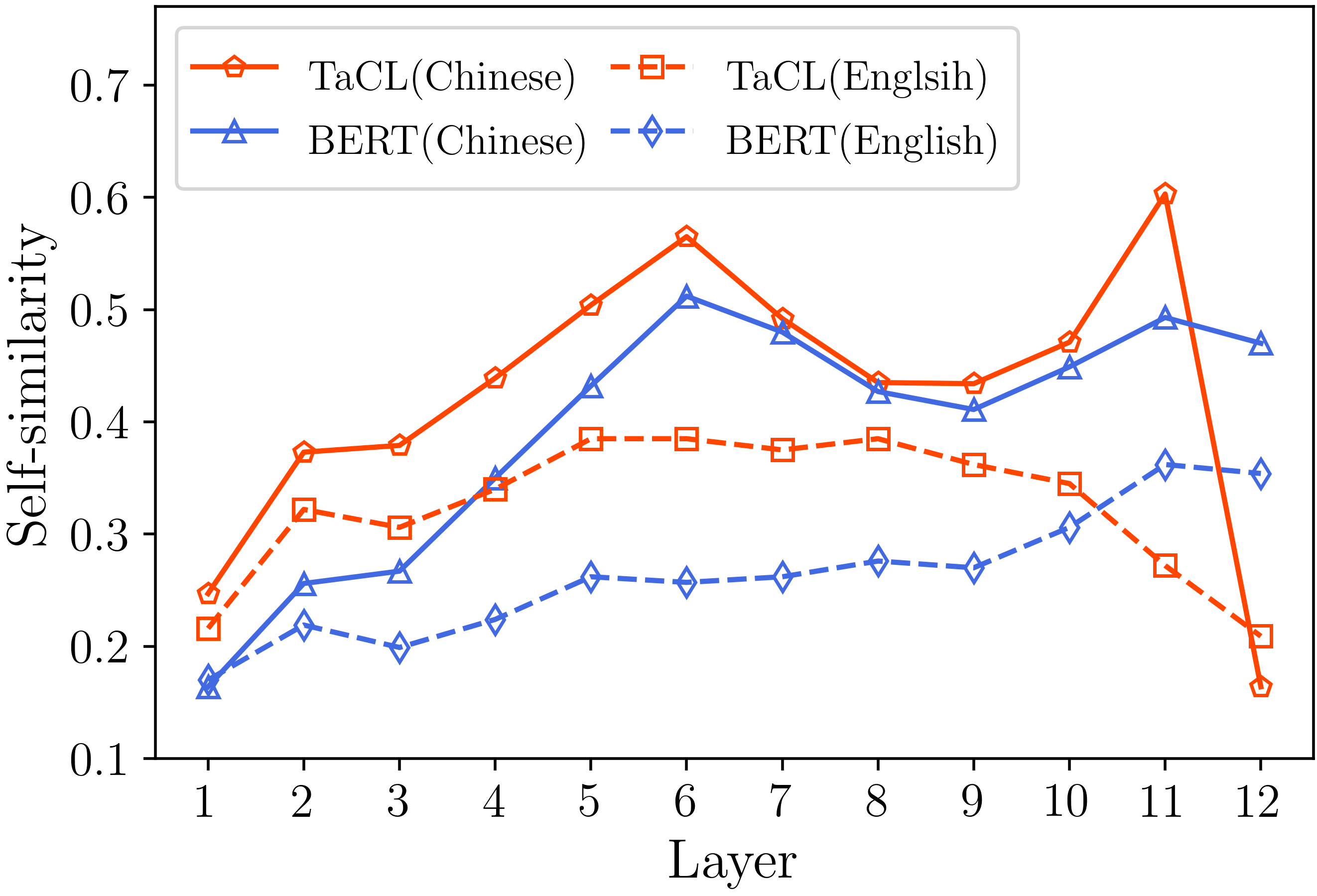
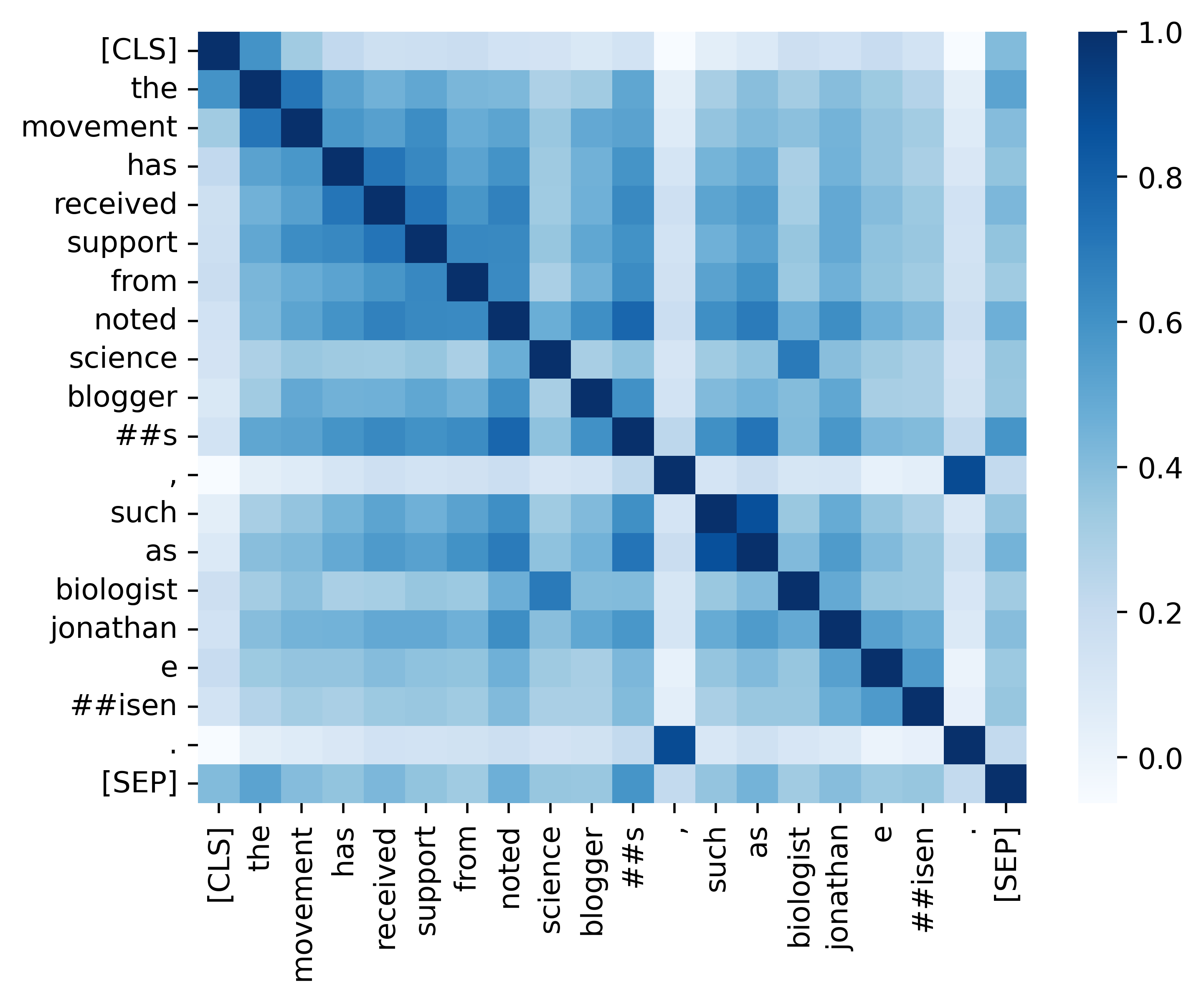
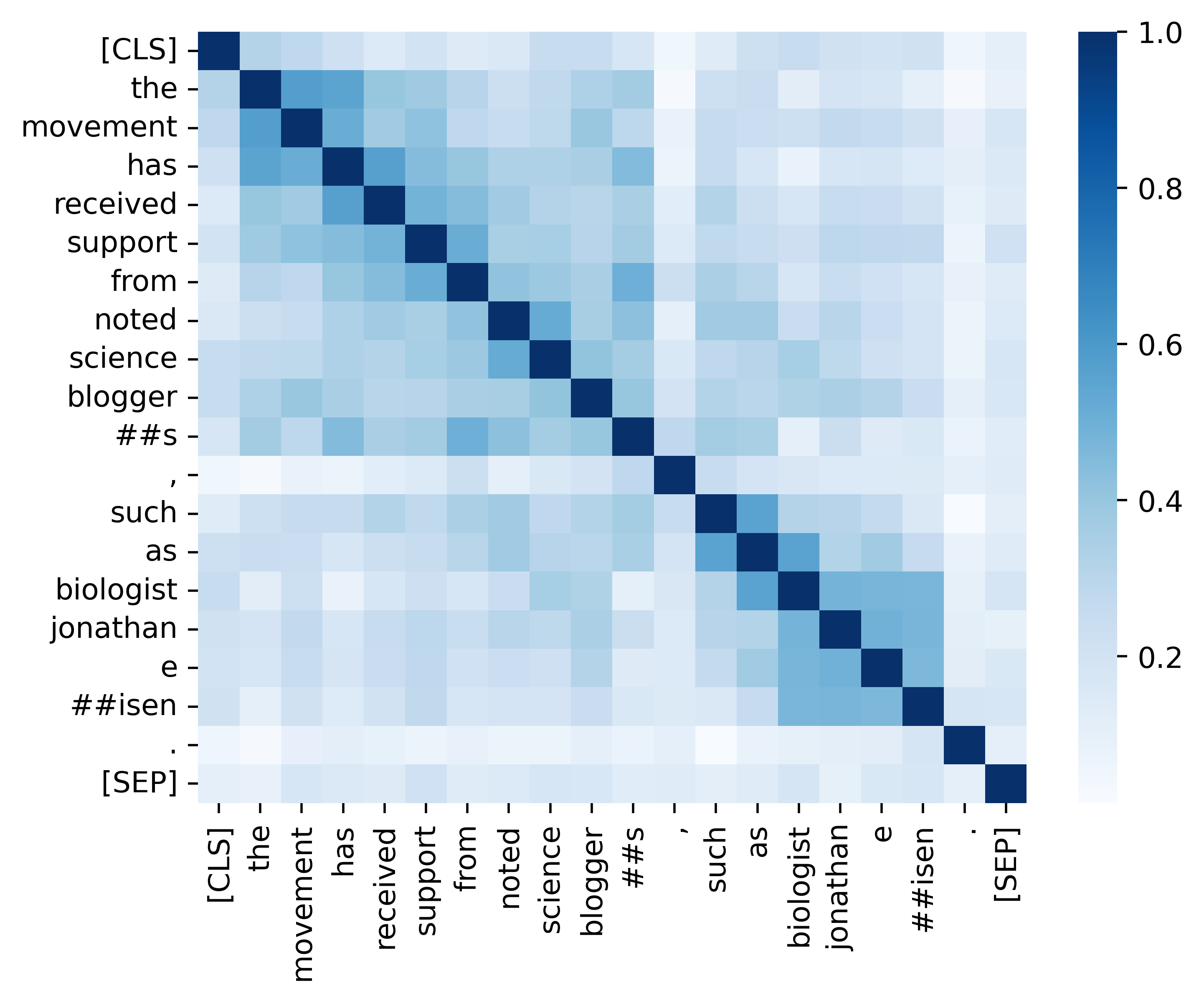
หากคุณพบว่ากระดาษและทรัพยากรของเรามีประโยชน์โปรดอ้างถึงกระดาษของเรา:
@article { DBLP:journals/corr/abs-2111-04198 ,
author = { Yixuan Su and
Fangyu Liu and
Zaiqiao Meng and
Tian Lan and
Lei Shu and
Ehsan Shareghi and
Nigel Collier } ,
title = { TaCL: Improving {BERT} Pre-training with Token-aware Contrastive Learning } ,
journal = { CoRR } ,
volume = { abs/2111.04198 } ,
year = { 2021 } ,
url = { https://arxiv.org/abs/2111.04198 } ,
eprinttype = { arXiv } ,
eprint = { 2111.04198 } ,
timestamp = { Wed, 10 Nov 2021 16:07:30 +0100 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2111-04198.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}หากคุณมีคำถามใด ๆ โปรดติดต่อฉันผ่าน ([email protected])


