TaCL
1.0.0
Autoren : Yixuan SU, Fangyu Liu, Zaiqiao Meng, Tian Lan, Lei Shu, Ehsan Shareghi und Nigel Collier
Code unseres Papiers: TaCl: Verbesserung von Bert vor dem Training mit tokenbewussten kontrastiven Lernen
[使用中文 TaCl-Bert 进行中文命名实体识别及中文分词教程]
Maskierte Sprachmodelle (MLMs) wie Bert und Roberta haben in den letzten Jahren das Gebiet des natürlichen Sprachverständnisses revolutioniert. Bestehende vorgebildete MLMs geben jedoch häufig eine anisotrope Verteilung von Token-Darstellungen aus, die eine schmale Teilmenge des gesamten Repräsentationsraums einnehmen. Solche Token -Darstellungen sind nicht ideal, insbesondere bei Aufgaben, die diskriminative semantische Bedeutungen verschiedener Token erfordern. In dieser Arbeit schlagen wir TaCl ( T oken- a Ware Contastive L Earning) vor, ein neuer kontinuierlicher Ansatz vor dem Training, der Bert dazu ermutigt, eine isotrope und diskriminative Verteilung von Token-Darstellungen zu lernen. TaCl ist voll und ganz unbeaufsichtigt und benötigt keine zusätzlichen Daten. Wir testen unseren Ansatz ausführlich auf einer Vielzahl von englischen und chinesischen Benchmarks. Die Ergebnisse zeigen, dass TaCl konsistente und bemerkenswerte Verbesserungen gegenüber dem ursprünglichen Bert -Modell mit sich bringt. Darüber hinaus führen wir eine detaillierte Analyse durch, um die Vorzüge und die inneren Arbeiten unseres Ansatzes aufzudecken.
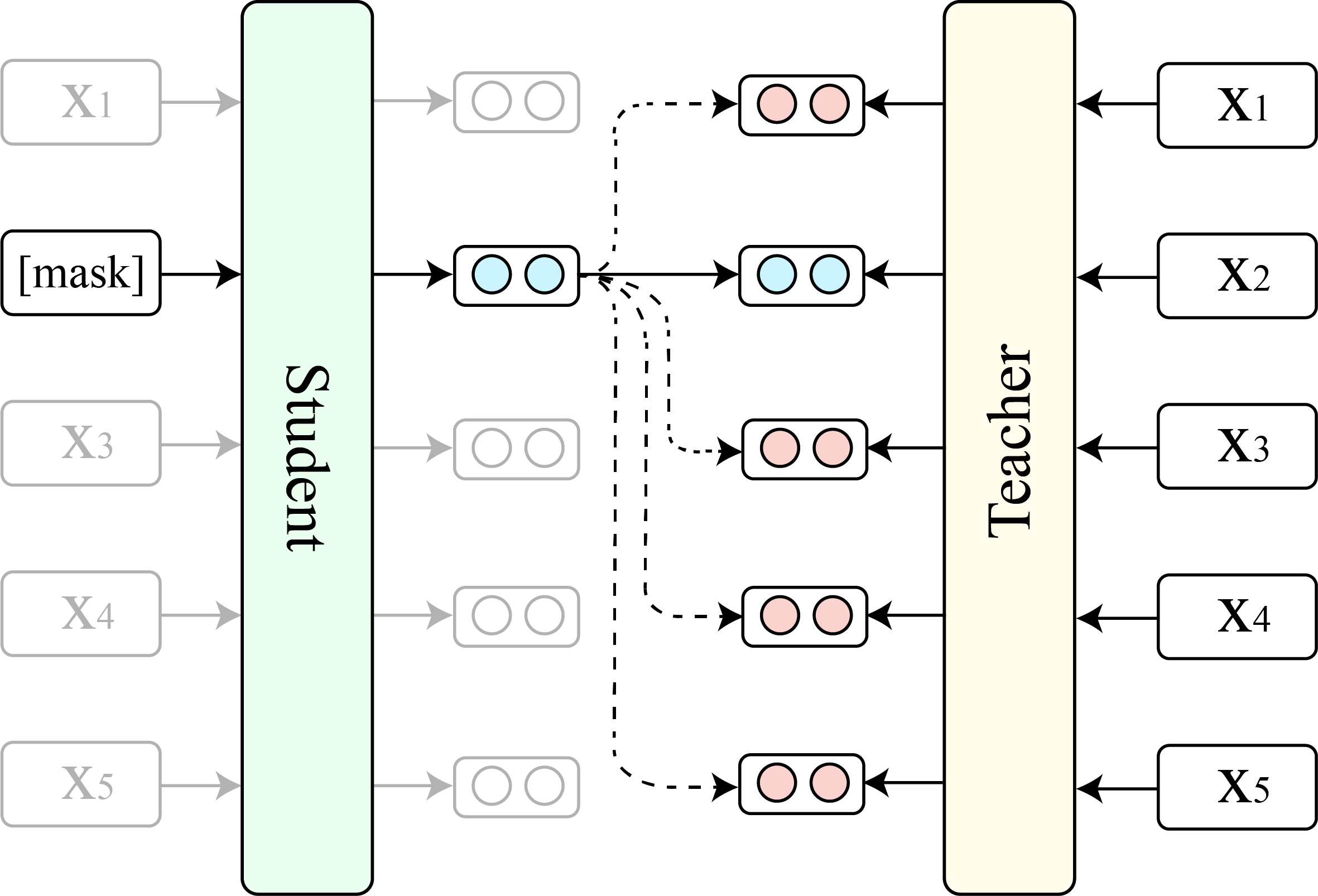
Wir zeigen den Vergleich zwischen TaCl (Basisversion) und der ursprünglichen Bert (Basisversion).
(1) Englische Benchmark -Ergebnisse zu Kader (Rajpurkar et al., 2018) (Dev -Set) und Kleber (Wang et al., 2019) Durchschnittlicher Punktzahl.
| Modell | Kader 1.1 (EM/F1) | Squad 2.0 (EM/F1) | Kleburchschnitt |
|---|---|---|---|
| Bert | 80.8/88.5 | 73.4/76.8 | 79,6 |
| TaCl | 81.6/89.0 | 74.4/77,5 | 81.2 |
(2) chinesische Benchmark -Ergebnisse (Testset F1) an vier NER -Aufgaben (MSRA, Ontonotes, Lebenslauf und Weibo) und drei chinesischen Wortsegmentierung (CWS) (PKU, Cityu und AS).
| Modell | MSRA | Ontonotes | Wieder aufnehmen | PKU | Cityu | ALS | |
|---|---|---|---|---|---|---|---|
| Bert | 94.95 | 80.14 | 95,53 | 68.20 | 96,50 | 97.60 | 96,50 |
| TaCl | 95.44 | 82.42 | 96,45 | 69,54 | 96,75 | 98.16 | 96,75 |
| Modellname | Modelladresse |
|---|---|
| Englisch ( Cambridgeltl/TaCl-Bert-Base-Unbekannt ) | Link |
| Chinesisch ( Cambridgeltl/Tacl-Bert-Base-Chinese ) | Link |
import torch
# initialize model
from transformers import AutoModel , AutoTokenizer
model_name = 'cambridgeltl/tacl-bert-base-uncased'
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
# create input ids
text = '[CLS] clbert is awesome. [SEP]'
tokenized_token_list = tokenizer . tokenize ( text )
input_ids = torch . LongTensor ( tokenizer . convert_tokens_to_ids ( tokenized_token_list )). view ( 1 , - 1 )
# compute hidden states
representation = model ( input_ids ). last_hidden_state # [1, seqlen, embed_dim] python version : 3.8
pip3 install -r requirements.txtWeitere Informationen finden Sie in ./Pretraining_Data -Verzeichnis.
Weitere Informationen finden Sie in ./Petretraining Directory.
Weitere Informationen finden Sie in ./English_Benchmark -Verzeichnis.
chmod +x ./download_benchmark_data.sh
./download_benchmark_data.sh Weitere Informationen finden Sie in ./Chinese_Benchmark -Verzeichnis.
Wir bieten alle wesentlichen Code zur Replikation der Ergebnisse (die folgenden Bilder), die in unserem Analyseabschnitt bereitgestellt werden. Die zugehörigen Codes und Anweisungen befinden sich im Verzeichnis ./Analysis. Viel Spaß!
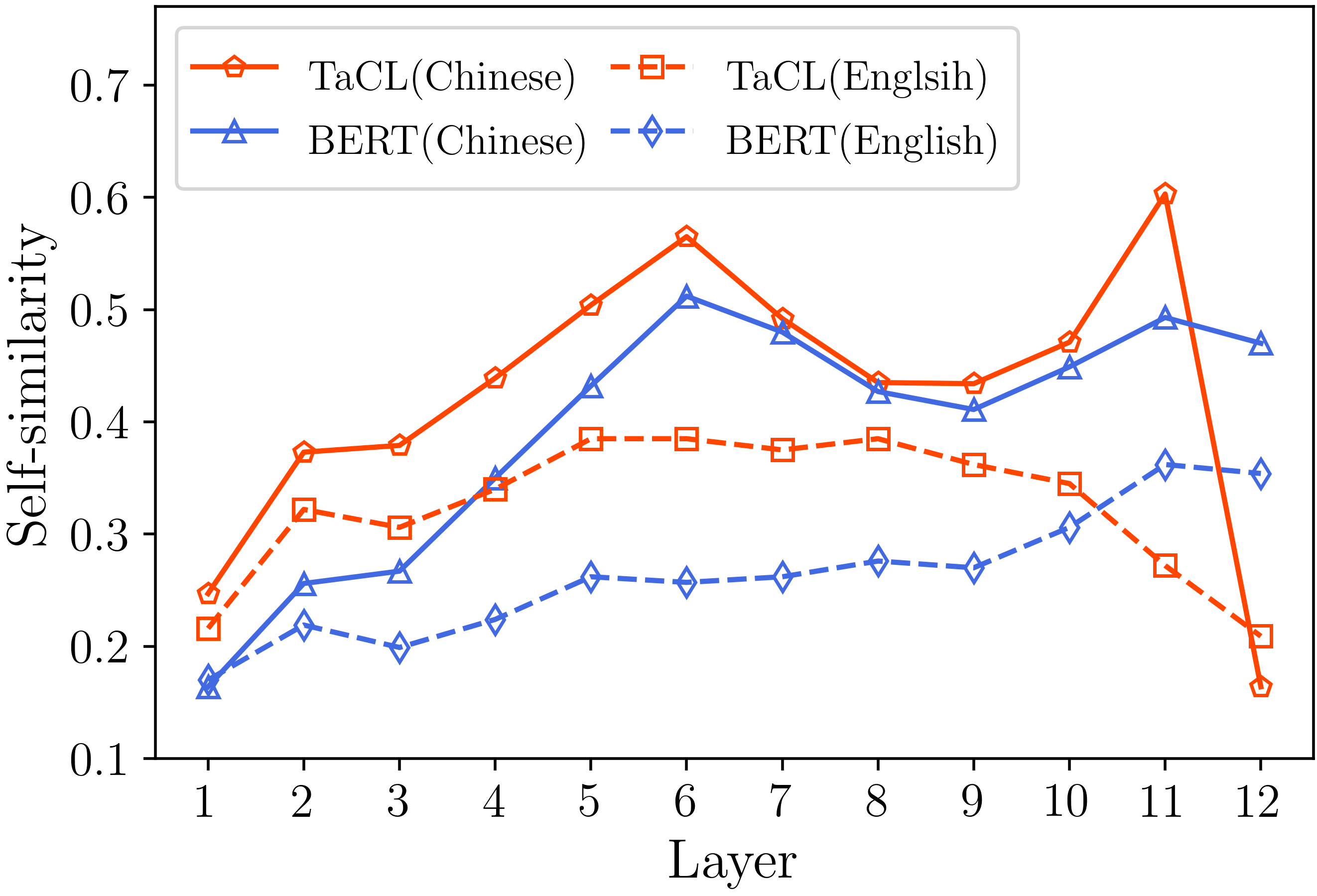
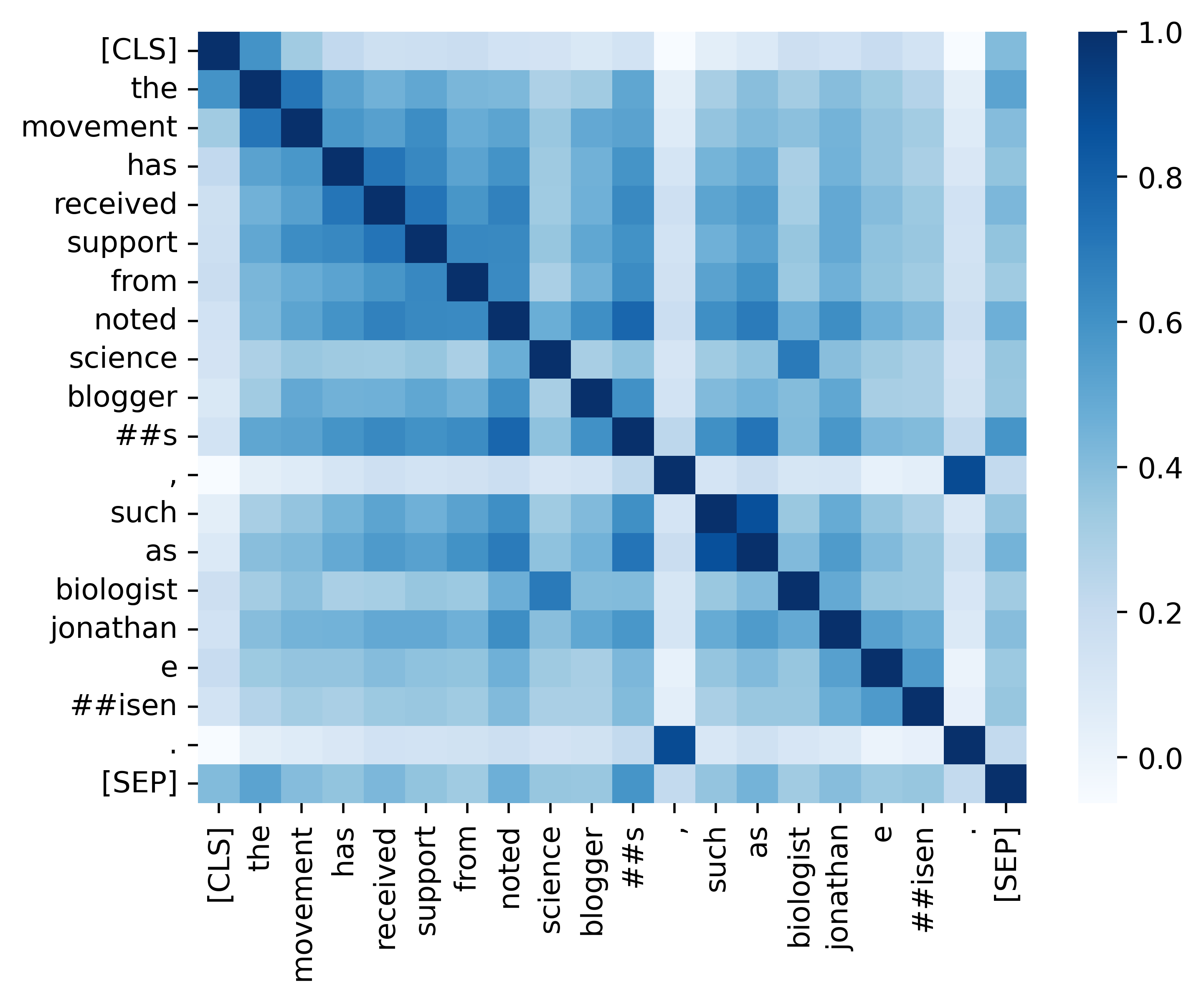
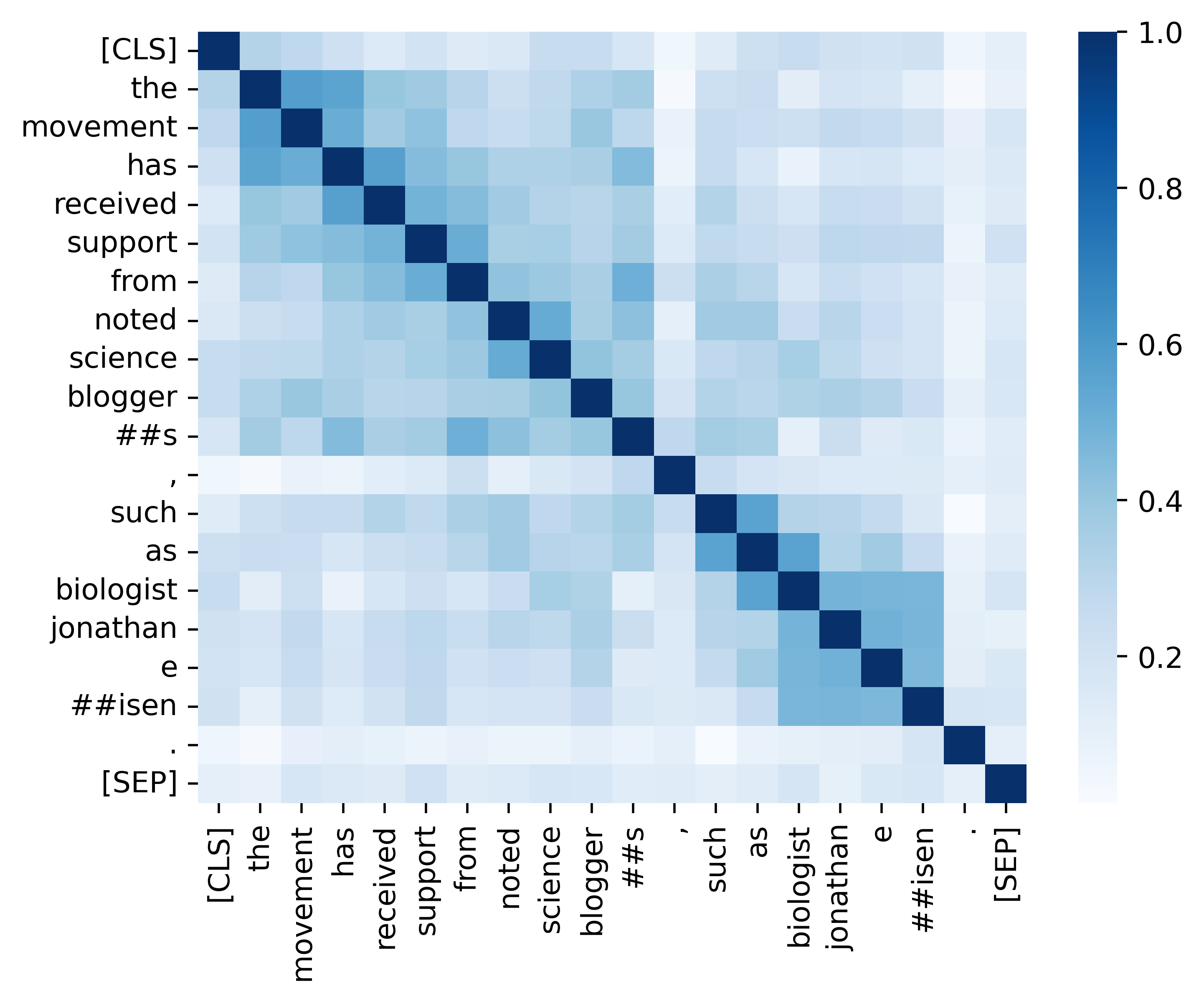
Wenn Sie unser Papier und unsere Ressourcen nützlich finden, zitieren Sie bitte unser Papier:
@article { DBLP:journals/corr/abs-2111-04198 ,
author = { Yixuan Su and
Fangyu Liu and
Zaiqiao Meng and
Tian Lan and
Lei Shu and
Ehsan Shareghi and
Nigel Collier } ,
title = { TaCL: Improving {BERT} Pre-training with Token-aware Contrastive Learning } ,
journal = { CoRR } ,
volume = { abs/2111.04198 } ,
year = { 2021 } ,
url = { https://arxiv.org/abs/2111.04198 } ,
eprinttype = { arXiv } ,
eprint = { 2111.04198 } ,
timestamp = { Wed, 10 Nov 2021 16:07:30 +0100 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2111-04198.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}Wenn Sie Fragen haben, können Sie mich gerne über ([email protected]) kontaktieren.


