TaCL
1.0.0
Penulis : Yixuan SU, Fangyu Liu, Zaiqiao Meng, Tian Lan, Lei Shu, Ehsan Shareghi, dan Nigel Collier
Kode Makalah Kami: TACL: Meningkatkan Bert Pra-Pelatihan dengan Pembelajaran Kontras Token-Aware
[使用中文 TACL-BERT 进行中文命名实体识别及中文分词教程]
Model Bahasa bertopeng (MLM) seperti Bert dan Roberta telah merevolusi bidang pemahaman bahasa alami dalam beberapa tahun terakhir. Namun, MLM pra-terlatih yang ada sering mengeluarkan distribusi anisotropik dari representasi token yang menempati subset sempit dari seluruh ruang representasi. Representasi token semacam itu tidak ideal, terutama untuk tugas -tugas yang menuntut makna semantik diskriminatif dari token yang berbeda. Dalam karya ini, kami mengusulkan TACL ( t oken- a ware c ontrastive l penghasilan), pendekatan pra-pelatihan terus-menerus baru yang mendorong Bert untuk mempelajari distribusi representasi token isotropik dan diskriminatif. TACL sepenuhnya tidak diawasi dan tidak memerlukan data tambahan. Kami secara luas menguji pendekatan kami pada berbagai tolok ukur bahasa Inggris dan Cina. Hasilnya menunjukkan bahwa TACL membawa perbaikan yang konsisten dan penting dibandingkan model Bert asli. Selain itu, kami melakukan analisis terperinci untuk mengungkapkan kelebihan dan pekerjaan dalam dari pendekatan kami.
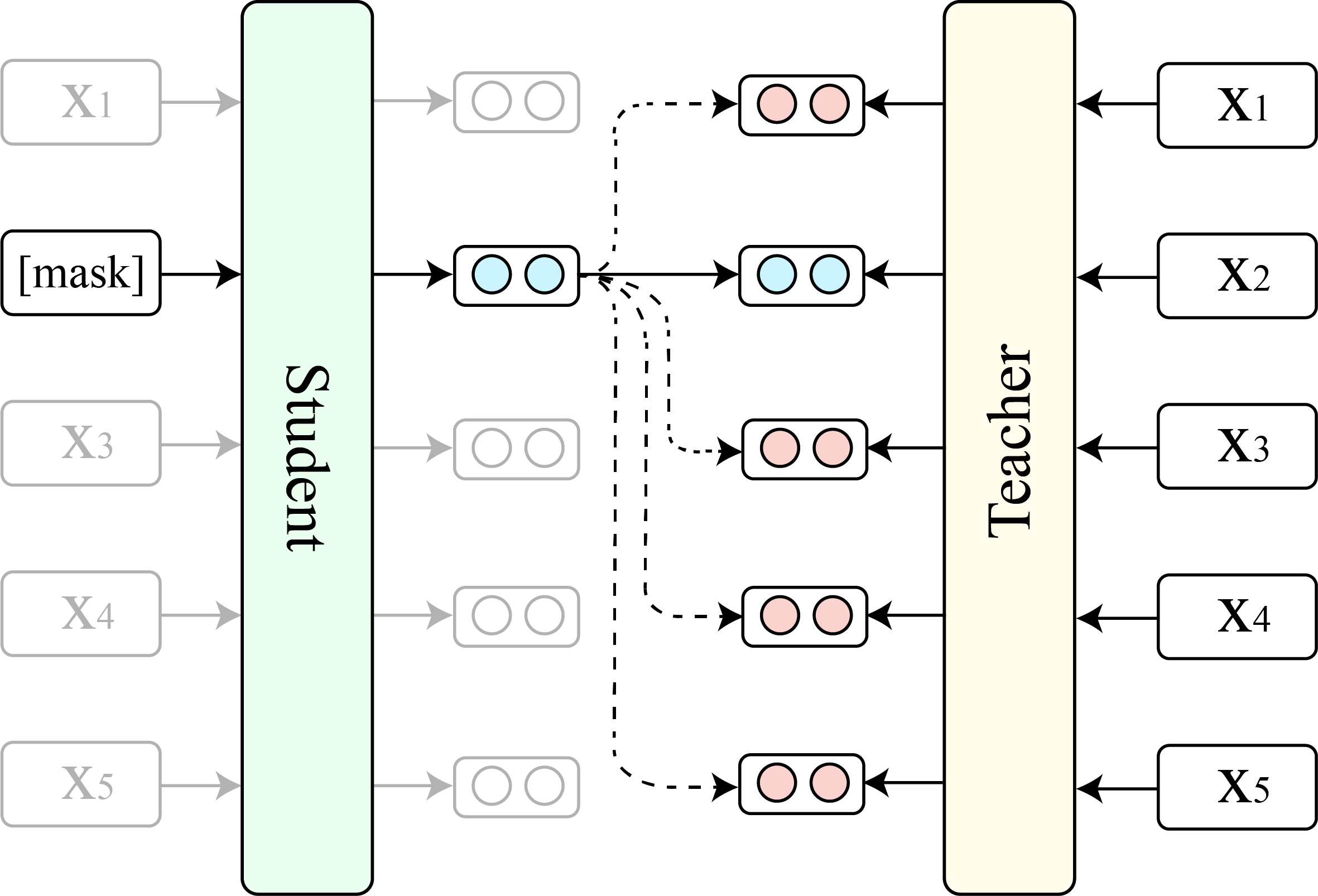
Kami menunjukkan perbandingan antara TACL (versi dasar) dan Bert asli (versi dasar).
(1) Hasil Benchmark Bahasa Inggris di Skuad (Rajpurkar et al., 2018) (set dev) dan skor rata -rata lem (Wang et al., 2019) .
| Model | Skuad 1.1 (EM/F1) | Skuad 2.0 (EM/F1) | Lem rata -rata |
|---|---|---|---|
| Bert | 80.8/88.5 | 73.4/76.8 | 79.6 |
| Tacl | 81.6/89.0 | 74.4/77.5 | 81.2 |
(2) Hasil Benchmark Cina (Tes Set F1) pada empat tugas NER (MSRA, Ontonotes, Resume, dan Weibo) dan tiga tugas Segmentasi Kata Cina (CWS) (PKU, Cityu, dan AS).
| Model | MSRA | Ontonotes | Melanjutkan | PKU | Cityu | SEBAGAI | |
|---|---|---|---|---|---|---|---|
| Bert | 94.95 | 80.14 | 95.53 | 68.20 | 96.50 | 97.60 | 96.50 |
| Tacl | 95.44 | 82.42 | 96.45 | 69.54 | 96.75 | 98.16 | 96.75 |
| Nama model | Alamat model |
|---|---|
| Bahasa Inggris ( Cambridgeltl/TACL-BERT-BASE-ONCASED ) | link |
| Cina ( Cambridgeltl/Tacl-Bert-Base-Chinese ) | link |
import torch
# initialize model
from transformers import AutoModel , AutoTokenizer
model_name = 'cambridgeltl/tacl-bert-base-uncased'
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
# create input ids
text = '[CLS] clbert is awesome. [SEP]'
tokenized_token_list = tokenizer . tokenize ( text )
input_ids = torch . LongTensor ( tokenizer . convert_tokens_to_ids ( tokenized_token_list )). view ( 1 , - 1 )
# compute hidden states
representation = model ( input_ids ). last_hidden_state # [1, seqlen, embed_dim] python version : 3.8
pip3 install -r requirements.txtSilakan merujuk ke detail yang disediakan di ./pretraining_data Directory.
Silakan merujuk ke detail yang disediakan di ./ Direktori PRRIRING.
Silakan merujuk ke detail yang disediakan di direktori ./English_Benchmark.
chmod +x ./download_benchmark_data.sh
./download_benchmark_data.sh Silakan merujuk ke detail yang disediakan di ./chinese_benchmark Directory.
Kami menyediakan semua kode penting untuk mereplikasi hasil (gambar di bawah) yang disediakan di bagian analisis kami. Kode dan instruksi terkait berada di direktori ./analisis. Selamat bersenang-senang!
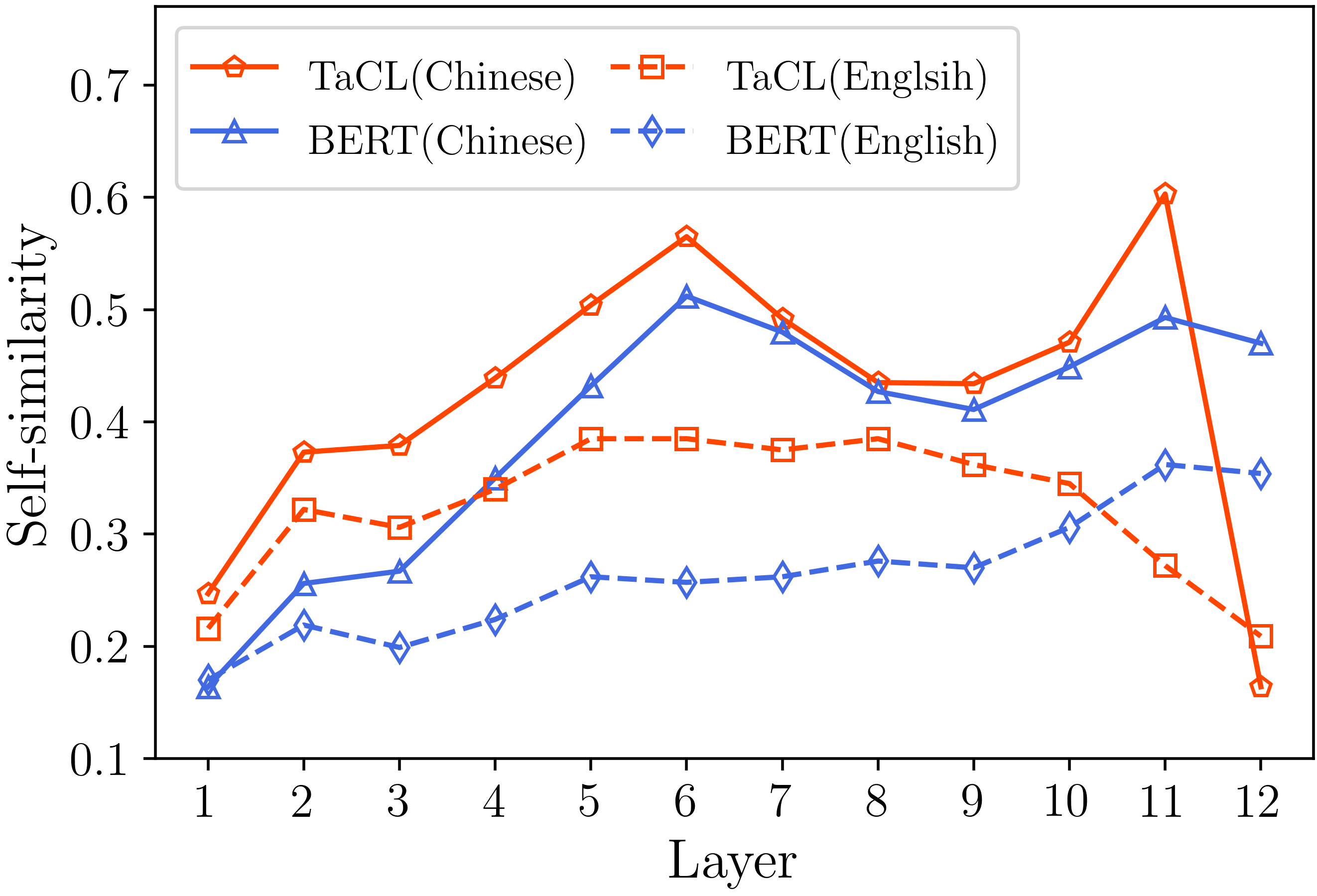
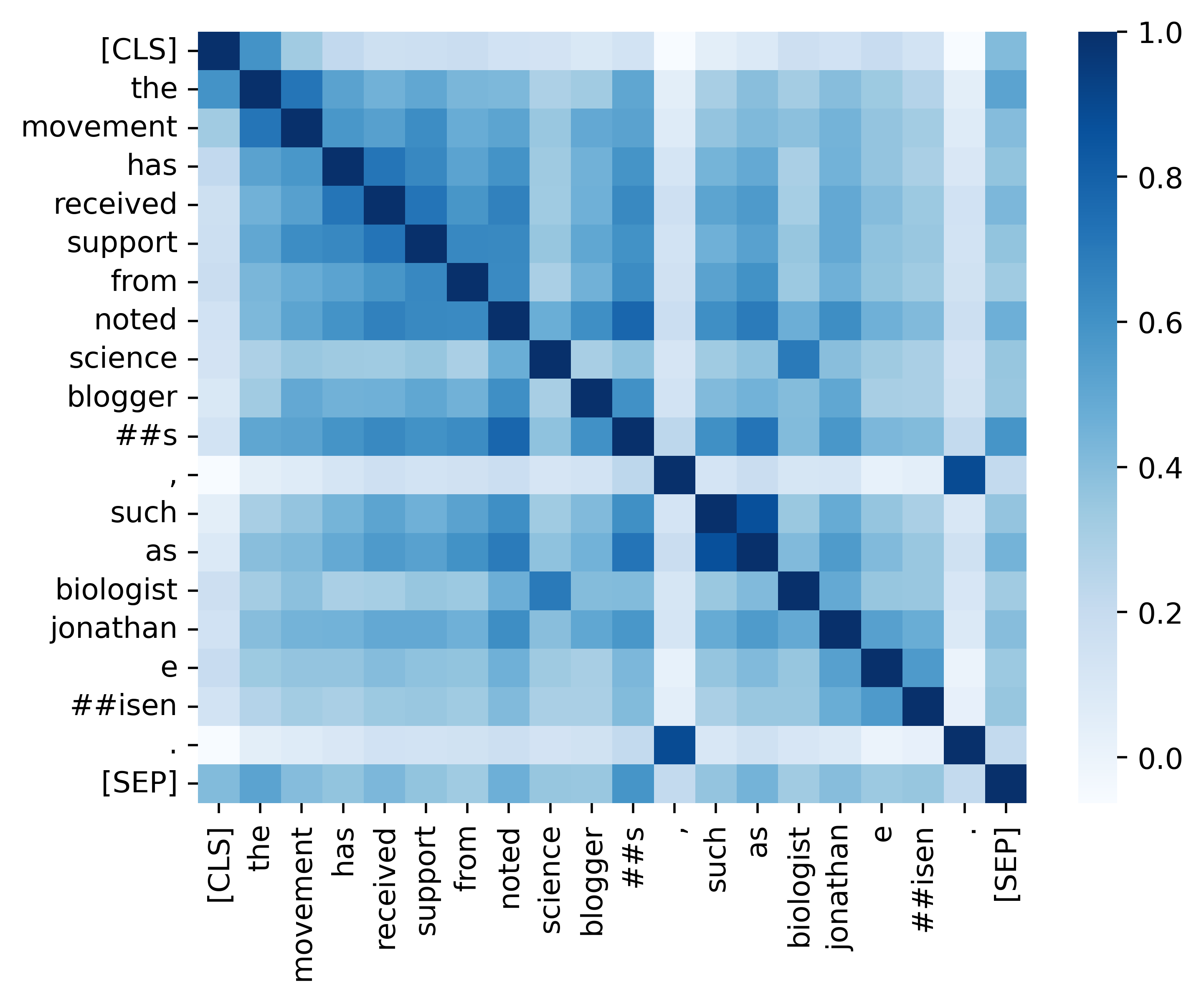
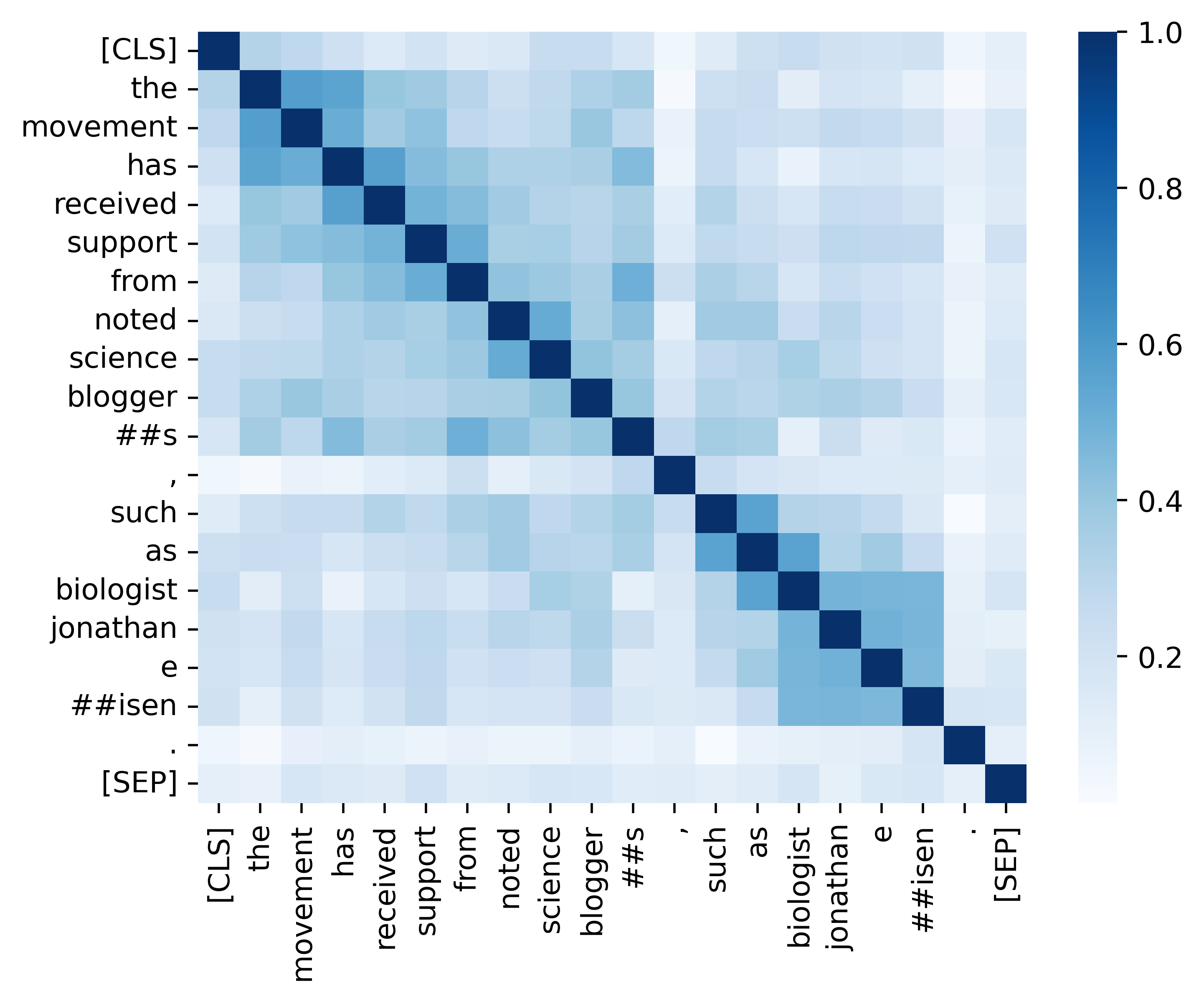
Jika Anda menemukan kertas dan sumber daya kami berguna, silakan kutip kertas kami:
@article { DBLP:journals/corr/abs-2111-04198 ,
author = { Yixuan Su and
Fangyu Liu and
Zaiqiao Meng and
Tian Lan and
Lei Shu and
Ehsan Shareghi and
Nigel Collier } ,
title = { TaCL: Improving {BERT} Pre-training with Token-aware Contrastive Learning } ,
journal = { CoRR } ,
volume = { abs/2111.04198 } ,
year = { 2021 } ,
url = { https://arxiv.org/abs/2111.04198 } ,
eprinttype = { arXiv } ,
eprint = { 2111.04198 } ,
timestamp = { Wed, 10 Nov 2021 16:07:30 +0100 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2111-04198.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}Jika Anda memiliki pertanyaan, jangan ragu untuk menghubungi saya melalui ([email protected]).


