TaCL
1.0.0
المؤلفون : Yixuan Su ، Fangyu Liu ، Zaiqiao Meng ، Tian Lan ، Lei Shu ، Ehsan Shareghi ، و Nigel Collier
مدونة ورقيتنا: TACL: تحسين التدريب قبل التدريب بيرت مع التعلم التباين المميز
[使用中文 taCl-bert 进行中文命名实体识别及中文分词教程]
أحدثت نماذج اللغة المقنعة (MLMs) مثل Bert و Roberta ثورة في مجال فهم اللغة الطبيعية في السنوات القليلة الماضية. ومع ذلك ، غالبًا ما يخرج MLMs الحالية التي تم تدريبها مسبقًا توزيعًا متباين الخواص لتمثيل الرمز المميز الذي يحتل مجموعة فرعية ضيقة من مساحة التمثيل بأكملها. مثل هذه التمثيلات الرمزية ليست مثالية ، خاصة بالنسبة للمهام التي تتطلب معاني الدلالية التمييزية للرموز المميزة. في هذا العمل ، نقترح TACL ( T oken- a ware c ontrastive l ) ، وهو نهج جديد مستمر قبل التدريب الذي يشجع بيرت على تعلم التوزيع المتناسق والتمييزي للتمثيل الرمزي. TACL غير خاضع للإشراف بالكامل ولا يتطلب أي بيانات إضافية. نختبر على نطاق واسع نهجنا على مجموعة واسعة من المعايير الإنجليزية والصينية. تظهر النتائج أن TACL يجلب تحسينات متسقة وملحقات على نموذج BERT الأصلي. علاوة على ذلك ، نجري تحليلًا مفصلاً للكشف عن مزايا الأعمال الداخلية لنهجنا.
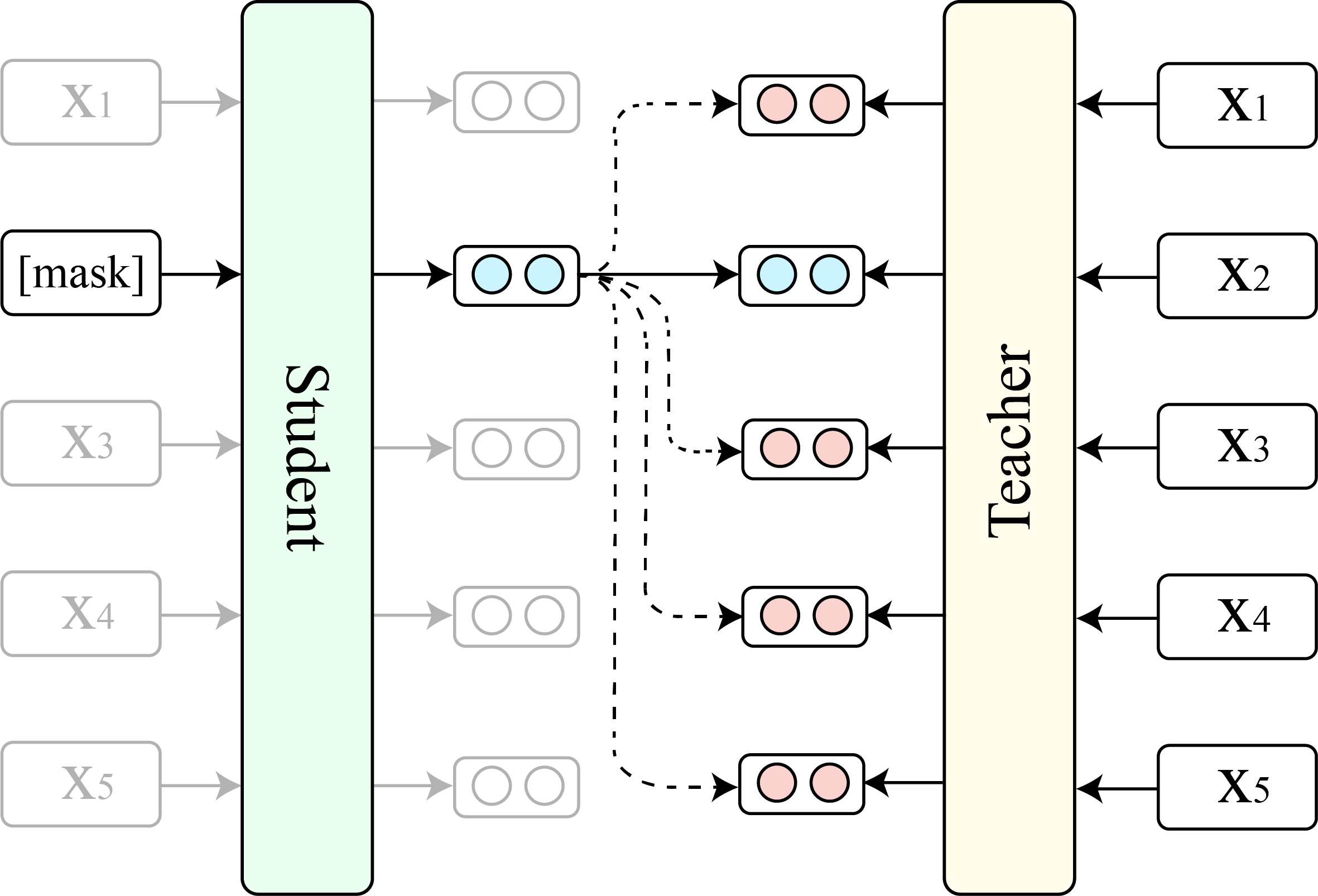
نعرض المقارنة بين TACL (الإصدار الأساسي) و BERT الأصلي (الإصدار الأساسي).
(1) النتائج القياسية الإنجليزية على Squad (Rajpurkar et al. ، 2018) (Dev Set) و Glue (Wang et al. ، 2019) متوسط درجة.
| نموذج | فرقة 1.1 (EM/F1) | فرقة 2.0 (EM/F1) | متوسط الغراء |
|---|---|---|---|
| بيرت | 80.8/88.5 | 73.4/76.8 | 79.6 |
| TACL | 81.6/89.0 | 74.4/77.5 | 81.2 |
(2) نتائج القياس الصينية (مجموعة الاختبار F1) على أربع مهام NER (MSRA ، Ontonotes ، استئناف ، و Weibo) وثلاث مهام تجزئة الكلمات الصينية (CWS) (PKU ، Cityu ، و AS).
| نموذج | MSRA | ontonotes | سيرة ذاتية | ويبو | PKU | سيتيو | مثل |
|---|---|---|---|---|---|---|---|
| بيرت | 94.95 | 80.14 | 95.53 | 68.20 | 96.50 | 97.60 | 96.50 |
| TACL | 95.44 | 82.42 | 96.45 | 69.54 | 96.75 | 98.16 | 96.75 |
| اسم النموذج | عنوان النموذج |
|---|---|
| اللغة الإنجليزية ( cambridgeltl/taCl-bert-base-uncsed ) | وصلة |
| الصينية ( Cambridgeltl/TACL-Bert-Base-Chinese ) | وصلة |
import torch
# initialize model
from transformers import AutoModel , AutoTokenizer
model_name = 'cambridgeltl/tacl-bert-base-uncased'
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
# create input ids
text = '[CLS] clbert is awesome. [SEP]'
tokenized_token_list = tokenizer . tokenize ( text )
input_ids = torch . LongTensor ( tokenizer . convert_tokens_to_ids ( tokenized_token_list )). view ( 1 , - 1 )
# compute hidden states
representation = model ( input_ids ). last_hidden_state # [1, seqlen, embed_dim] python version : 3.8
pip3 install -r requirements.txtيرجى الرجوع إلى التفاصيل المقدمة في ./pretraining_data دليل.
يرجى الرجوع إلى التفاصيل المقدمة في./دليل الدليل.
يرجى الرجوع إلى التفاصيل المقدمة في./english_benchmark دليل.
chmod +x ./download_benchmark_data.sh
./download_benchmark_data.sh يرجى الرجوع إلى التفاصيل المقدمة في ./Chinese_Benchmark دليل.
نحن نقدم جميع التعليمات البرمجية الأساسية لتكرار النتائج (الصور أدناه) الواردة في قسم التحليل الخاص بنا. توجد الرموز والتعليمات ذات الصلة في دليل التحليل. استمتع!
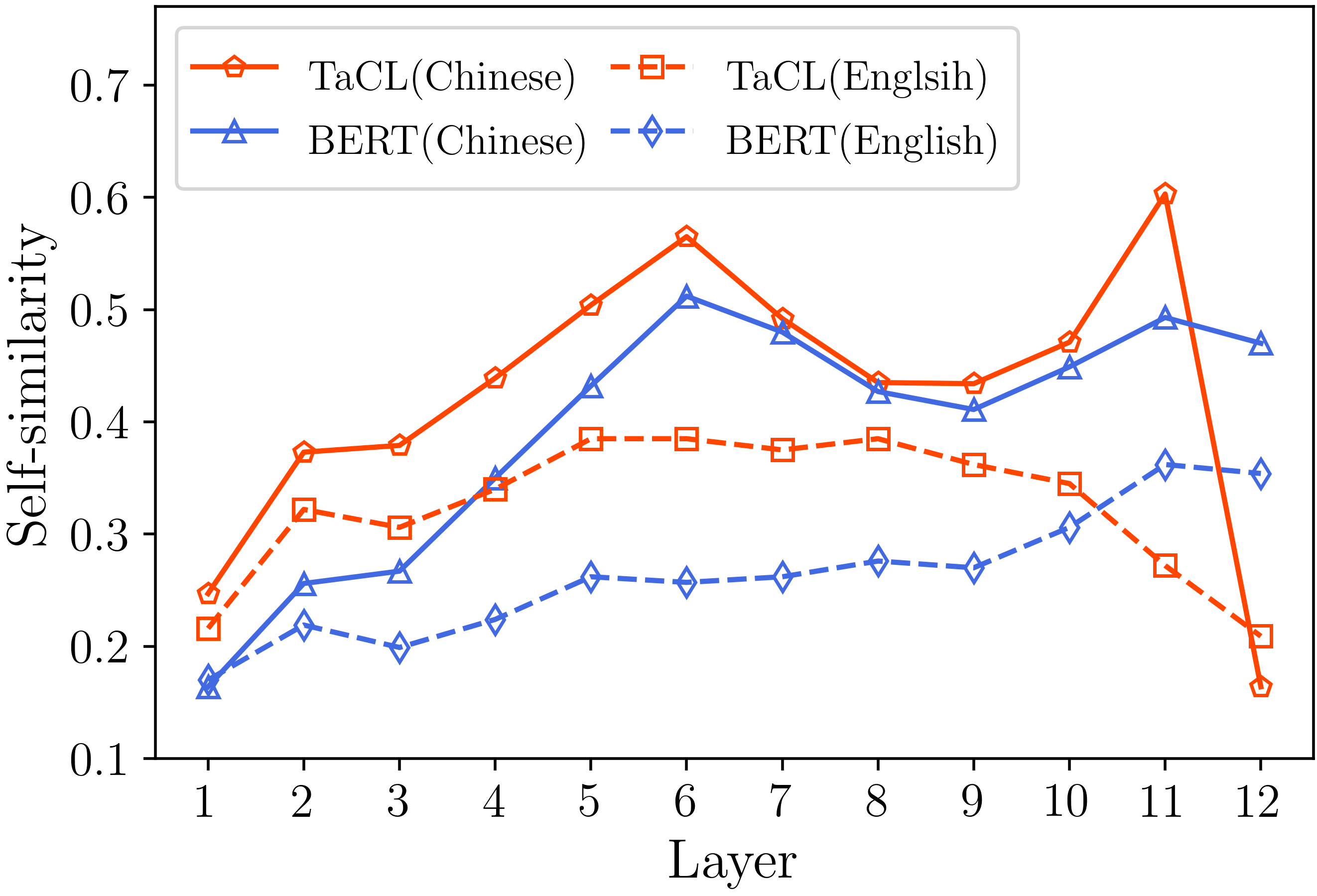
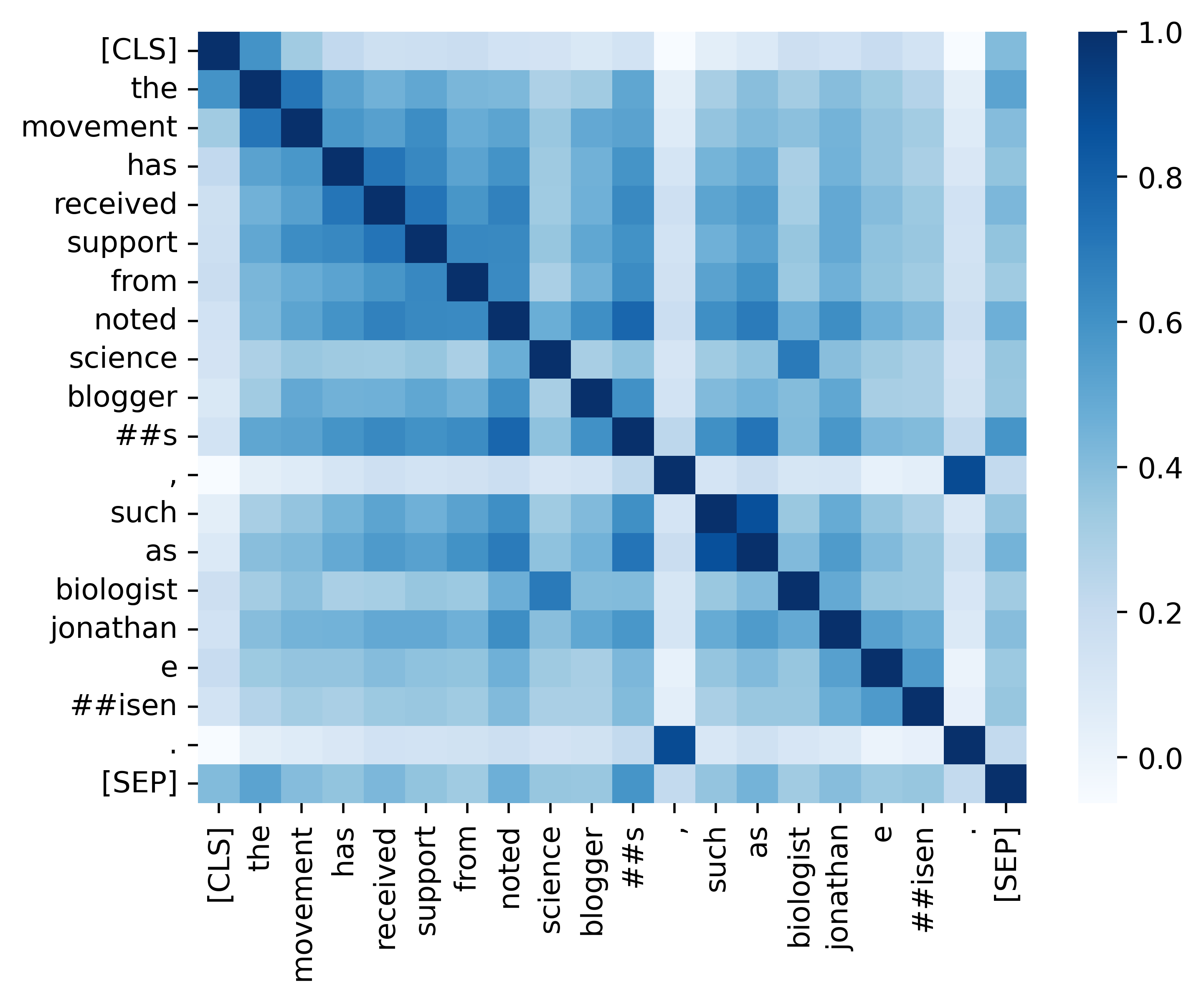
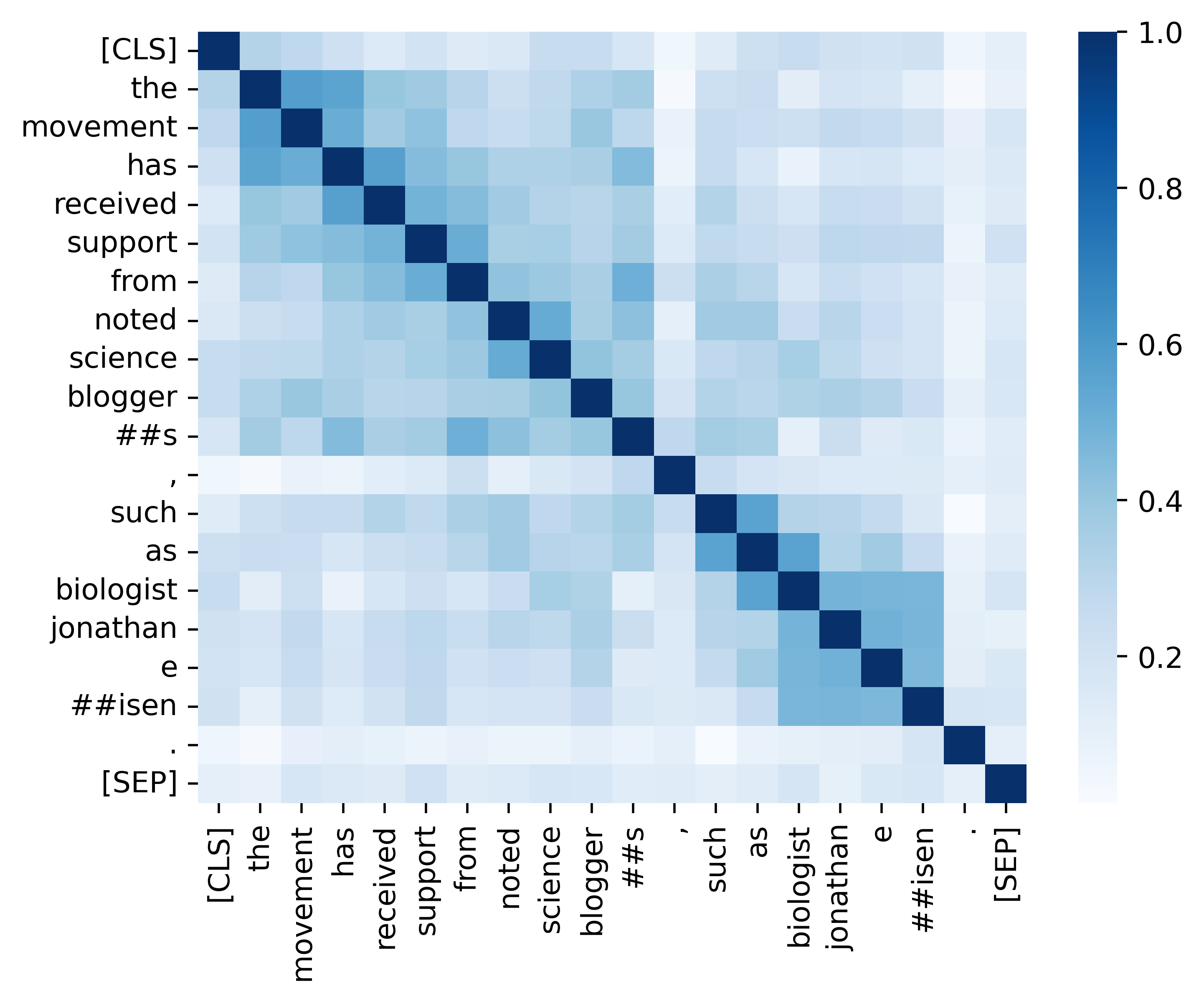
إذا وجدت ورقتنا ومواردنا مفيدة ، فيرجى الاستشهاد بورقنا:
@article { DBLP:journals/corr/abs-2111-04198 ,
author = { Yixuan Su and
Fangyu Liu and
Zaiqiao Meng and
Tian Lan and
Lei Shu and
Ehsan Shareghi and
Nigel Collier } ,
title = { TaCL: Improving {BERT} Pre-training with Token-aware Contrastive Learning } ,
journal = { CoRR } ,
volume = { abs/2111.04198 } ,
year = { 2021 } ,
url = { https://arxiv.org/abs/2111.04198 } ,
eprinttype = { arXiv } ,
eprint = { 2111.04198 } ,
timestamp = { Wed, 10 Nov 2021 16:07:30 +0100 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2111-04198.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}إذا كان لديك أي أسئلة ، فلا تتردد في الاتصال بي عبر ([email protected]).


