TaCL
1.0.0
저자 : Yixuan SU, Fangyu Liu, Zaiqiao Meng, Tian Lan, Lei Shu, Ehsan Sharghi 및 Nigel Collier
우리 논문 코드 : TACL : 토큰 인식 대조 학습으로 BERT 사전 훈련 개선
[Tacl-Bert 进行中文命名实体识别及中文分词教程]
Bert 및 Roberta와 같은 마스크 언어 모델 (MLM)은 지난 몇 년 동안 자연어 이해 분야에 혁명을 일으켰습니다. 그러나, 기존의 미리 훈련 된 MLM은 종종 전체 표현 공간의 좁은 서브 세트를 차지하는 토큰 표현의 이방성 분포를 출력합니다. 이러한 토큰 표현은 특히 독특한 토큰의 차별적 의미 론적 의미를 요구하는 작업에 이상적이지 않습니다. 이 작업에서, 우리는 Bert가 토큰 표현의 등방성 및 차별적 분포를 배우도록 장려하는 새로운 연속적인 사전 훈련 접근법 인 TACL ( T oken- a ware c ontrastive l byning)을 제안합니다. TACL은 완전히 감독되지 않았으며 추가 데이터가 필요하지 않습니다. 우리는 광범위한 영어 및 중국어 벤치 마크에 대한 접근 방식을 광범위하게 테스트합니다. 결과는 TACL이 원래 Bert 모델에 비해 일관되고 주목할만한 개선을 제공한다는 것을 보여줍니다. 또한, 우리는 접근 방식의 장점과 내부 작업을 밝히기 위해 자세한 분석을 수행합니다.
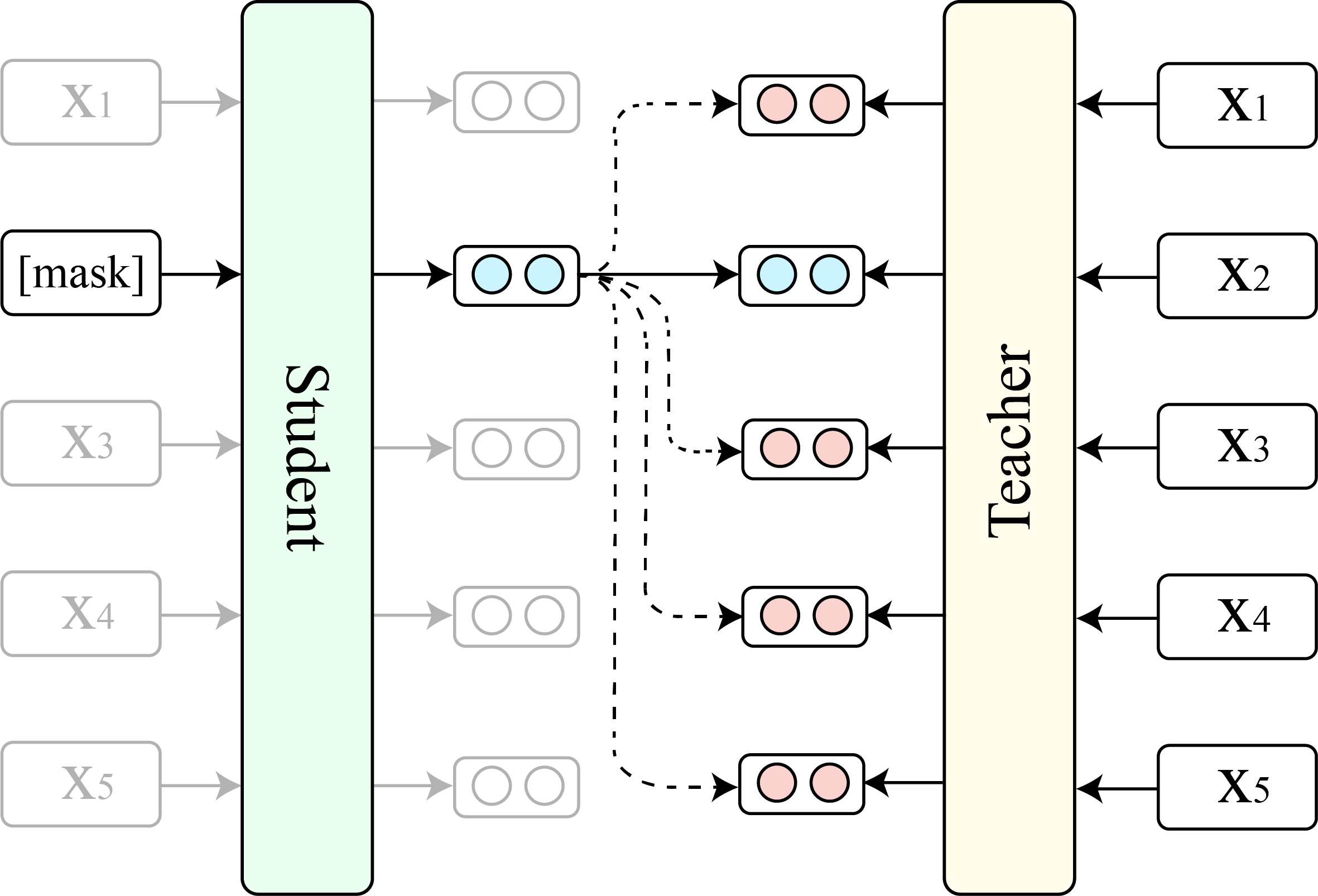
우리는 TaCl (기본 버전)과 원래 Bert (기본 버전)의 비교를 보여줍니다.
(1) 팀의 영어 벤치 마크 결과 (Rajpurkar et al., 2018) (개발 세트) 및 접착제 (Wang et al., 2019) 평균 점수.
| 모델 | 분대 1.1 (EM/F1) | 분대 2.0 (EM/F1) | 접착제 평균 |
|---|---|---|---|
| 버트 | 80.8/88.5 | 73.4/76.8 | 79.6 |
| TACL | 81.6/89.0 | 74.4/77.5 | 81.2 |
(2) 4 개의 NER 작업 (MSRA, Ontonotes, Resume 및 Weibo) 및 3 개의 중국어 단어 세분화 (CWS) 작업 (PKU, Cityu 등)에 대한 중국 벤치 마크 결과 (테스트 세트 F1).
| 모델 | MSRA | Ontonotes | 재개하다 | 와이보 | PKU | 도시 | 처럼 |
|---|---|---|---|---|---|---|---|
| 버트 | 94.95 | 80.14 | 95.53 | 68.20 | 96.50 | 97.60 | 96.50 |
| TACL | 95.44 | 82.42 | 96.45 | 69.54 | 96.75 | 98.16 | 96.75 |
| 모델 이름 | 모델 주소 |
|---|---|
| 영어 ( Cambridgeltl/Tacl-Bert-Base-uncased ) | 링크 |
| 중국어 ( Cambridgeltl/Tacl-Bert-Base-Chinese ) | 링크 |
import torch
# initialize model
from transformers import AutoModel , AutoTokenizer
model_name = 'cambridgeltl/tacl-bert-base-uncased'
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
# create input ids
text = '[CLS] clbert is awesome. [SEP]'
tokenized_token_list = tokenizer . tokenize ( text )
input_ids = torch . LongTensor ( tokenizer . convert_tokens_to_ids ( tokenized_token_list )). view ( 1 , - 1 )
# compute hidden states
representation = model ( input_ids ). last_hidden_state # [1, seqlen, embed_dim] python version : 3.8
pip3 install -r requirements.txt./pretraining_data 디렉토리에 제공된 세부 정보를 참조하십시오.
./pretraining 디렉토리에 제공된 세부 정보를 참조하십시오.
./english_benchmark 디렉토리에 제공된 세부 정보를 참조하십시오.
chmod +x ./download_benchmark_data.sh
./download_benchmark_data.sh ./chinese_benchmark 디렉토리에 제공된 세부 정보를 참조하십시오.
우리는 분석 섹션에 제공된 결과 (아래 이미지)를 복제하기위한 모든 필수 코드를 제공합니다. 관련 코드 및 지침은 ./analysis 디렉토리에 있습니다. 재미있게 보내세요!
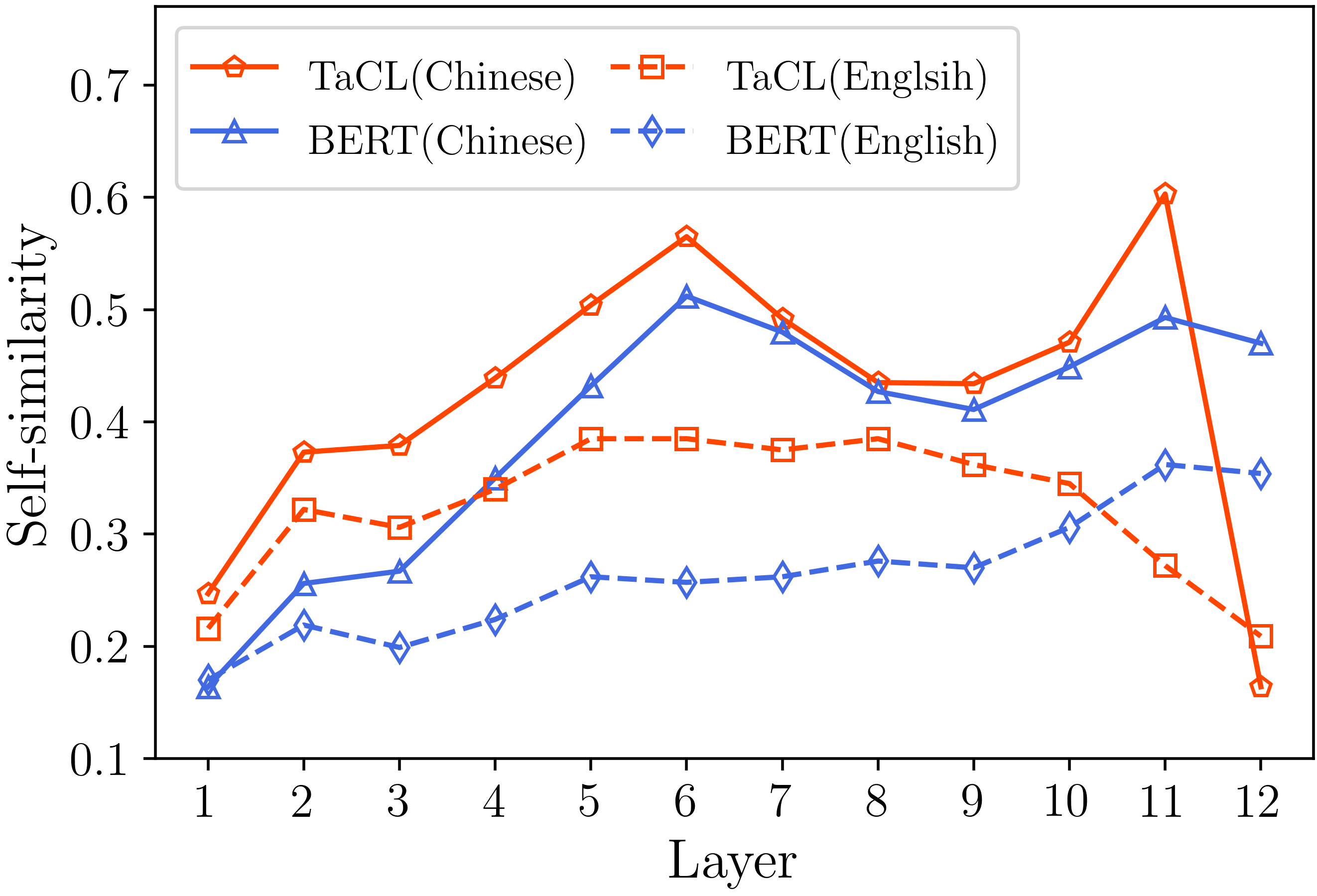
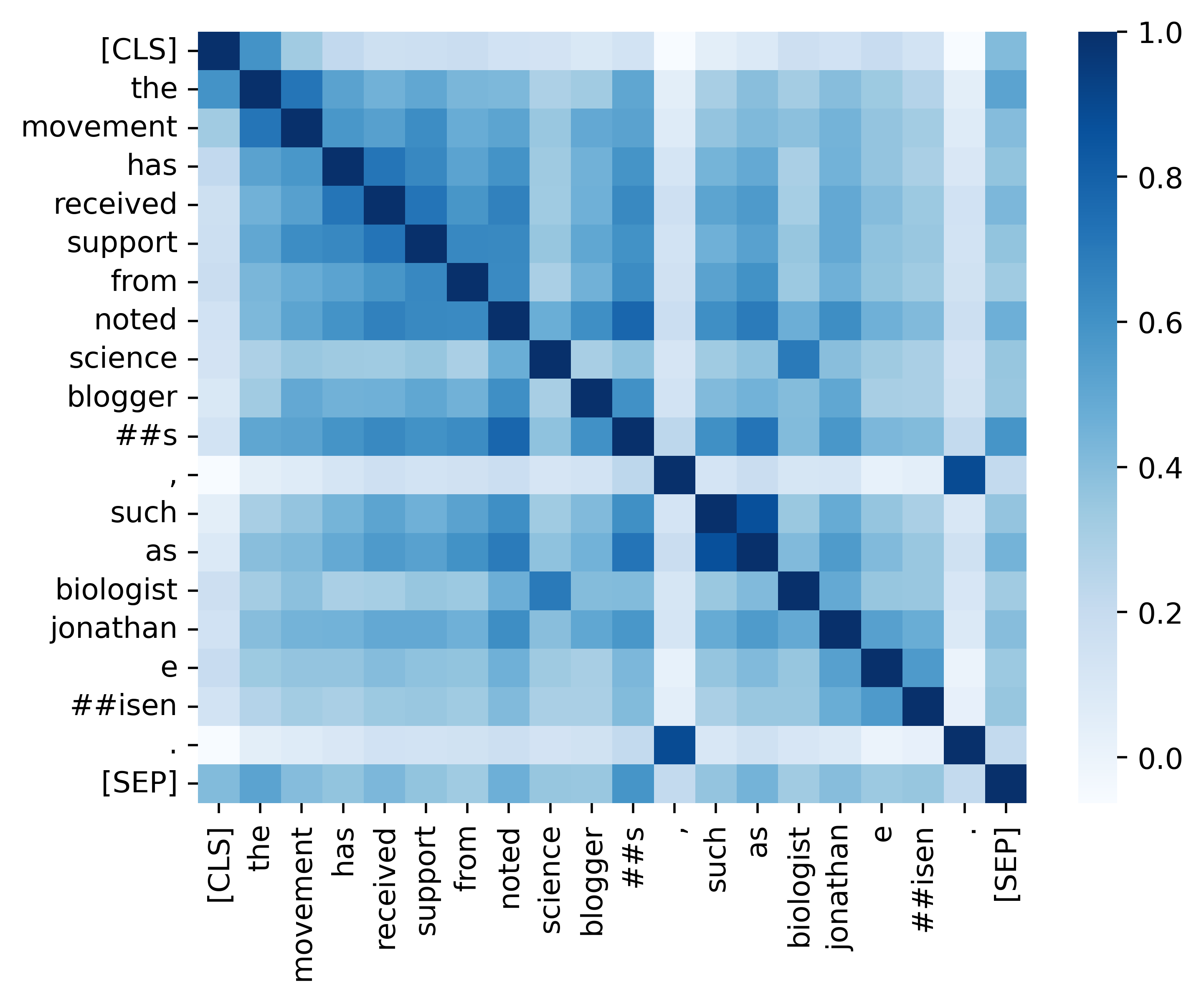
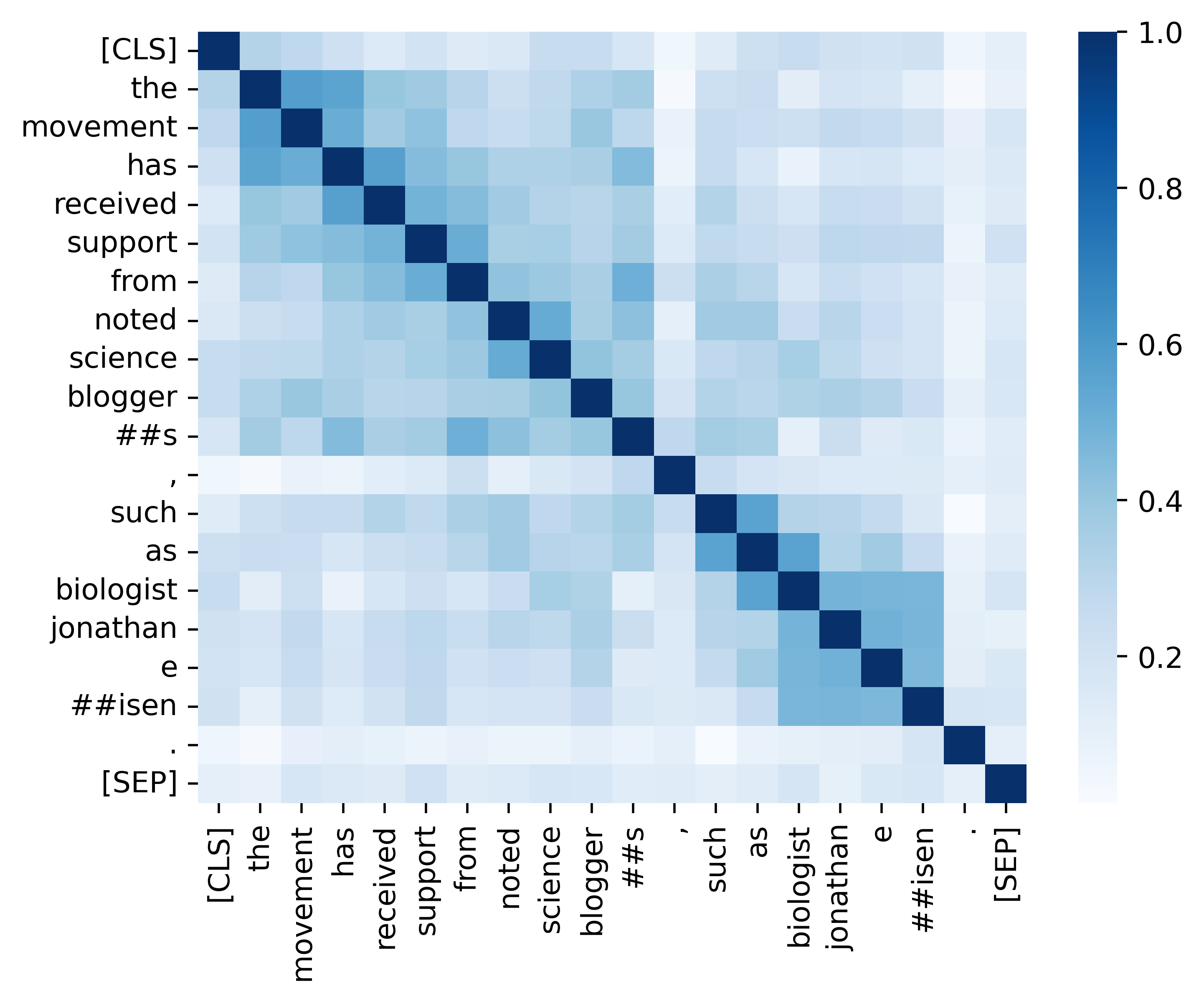
우리의 종이와 자료가 유용하다고 생각되면 친절하게 우리의 논문을 인용하십시오.
@article { DBLP:journals/corr/abs-2111-04198 ,
author = { Yixuan Su and
Fangyu Liu and
Zaiqiao Meng and
Tian Lan and
Lei Shu and
Ehsan Shareghi and
Nigel Collier } ,
title = { TaCL: Improving {BERT} Pre-training with Token-aware Contrastive Learning } ,
journal = { CoRR } ,
volume = { abs/2111.04198 } ,
year = { 2021 } ,
url = { https://arxiv.org/abs/2111.04198 } ,
eprinttype = { arXiv } ,
eprint = { 2111.04198 } ,
timestamp = { Wed, 10 Nov 2021 16:07:30 +0100 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2111-04198.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}궁금한 점이 있으시면 ([email protected])를 통해 저에게 연락하십시오.


