TaCL
1.0.0
Auteurs : Yixuan Su, Fangyu Liu, Zaiqiao Meng, Tian Lan, Lei Shu, Ehsan Shareghi et Nigel Collier
Code de notre article: TACL: Amélioration de la pré-formation Bert avec un apprentissage contrastif conscient des jetons
[使用中文 Tacl-Bert 进行中文命名实体识别及中文分词教程]
Les modèles de langage masqué (MLM) tels que Bert et Roberta ont révolutionné le domaine de la compréhension du langage naturel au cours des dernières années. Cependant, les MLM pré-formés existants produisent souvent une distribution anisotrope des représentations de jetons qui occupe un sous-ensemble étroit de l'ensemble de l'espace de représentation. Ces représentations de jeton ne sont pas idéales, en particulier pour les tâches qui exigent des significations sémantiques discriminantes de jetons distincts. Dans ce travail, nous proposons TACL ( t Oken- a Ware Contrastive l Garin), une nouvelle approche continue de pré-formation qui encourage Bert à apprendre une distribution isotrope et discriminante des représentations de jetons. TACL n'est pas totalement supervisé et ne nécessite aucune donnée supplémentaire. Nous testons largement notre approche sur un large éventail de repères anglais et chinois. Les résultats montrent que TACL apporte des améliorations cohérentes et notables par rapport au modèle Bert d'origine. De plus, nous effectuons une analyse détaillée pour révéler les mérites et les travailleurs intérieurs de notre approche.
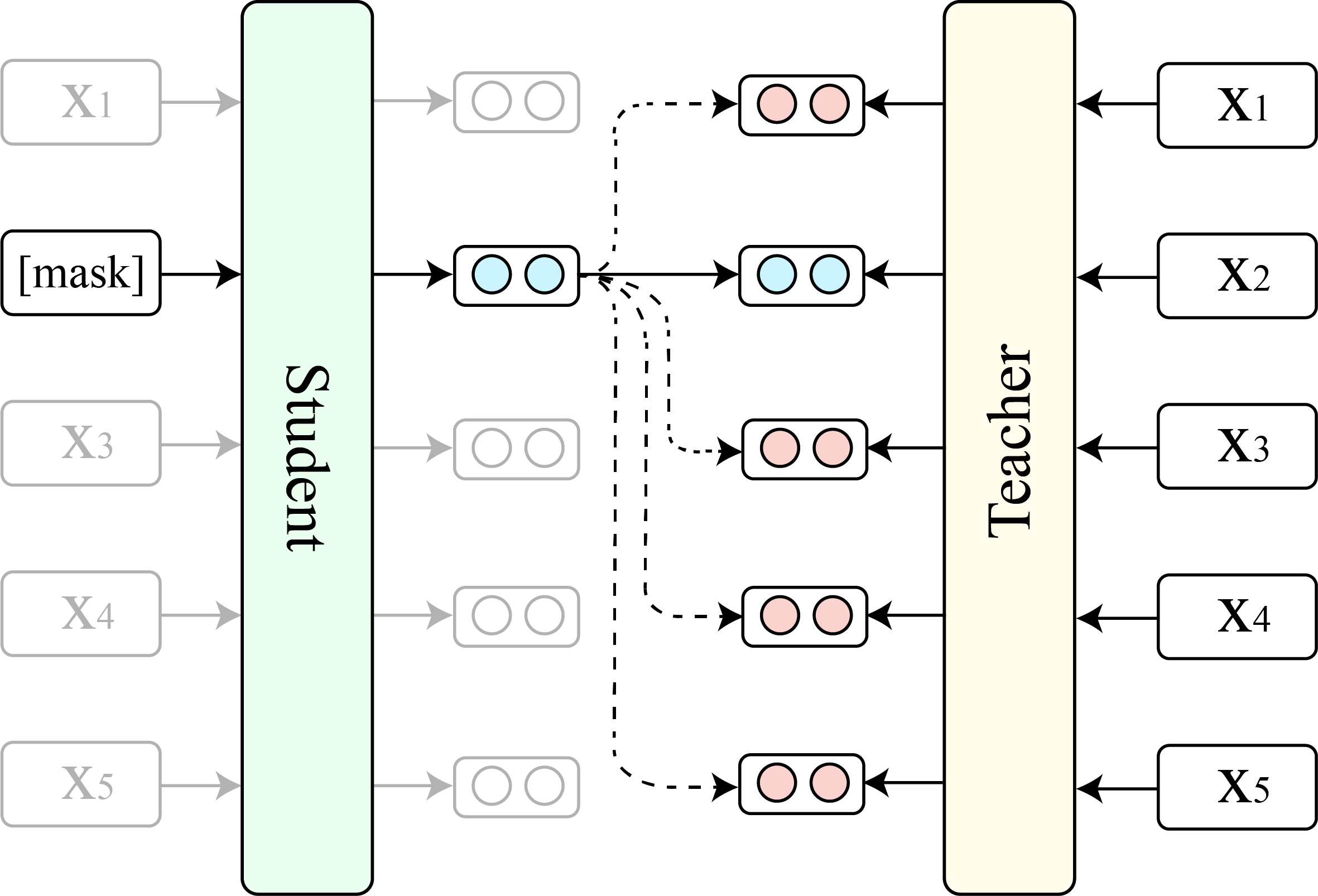
Nous montrons la comparaison entre TACL (version de base) et le Bert original (version de base).
(1) Résultats de référence en anglais sur Squad (Rajpurkar et al., 2018) (Dev set) et Glue (Wang et al., 2019) Score moyen.
| Modèle | Escouade 1.1 (EM / F1) | Squad 2.0 (EM / F1) | Moyenne de colle |
|---|---|---|---|
| Bert | 80.8 / 88.5 | 73.4 / 76.8 | 79.6 |
| Tacl | 81.6 / 89.0 | 74.4 / 77.5 | 81.2 |
(2) Résultats de référence chinois (Test Set F1) sur quatre tâches NER (MSRA, Ontonotes, CV et Weibo) et trois tâches de segmentation des mots chinois (CWS) (PKU, CITYU et AS).
| Modèle | MSRA | Ontonotes | CV | Pku | Cityu | COMME | |
|---|---|---|---|---|---|---|---|
| Bert | 94.95 | 80.14 | 95,53 | 68.20 | 96.50 | 97.60 | 96.50 |
| Tacl | 95.44 | 82.42 | 96.45 | 69.54 | 96.75 | 98.16 | 96.75 |
| Nom du modèle | Adresse du modèle |
|---|---|
| Anglais ( Cambridgeltl / Tacl-Bert-Base-Snecald ) | lien |
| Chinois ( Cambridgeltl / Tacl-Bert-Base-Chinese ) | lien |
import torch
# initialize model
from transformers import AutoModel , AutoTokenizer
model_name = 'cambridgeltl/tacl-bert-base-uncased'
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
# create input ids
text = '[CLS] clbert is awesome. [SEP]'
tokenized_token_list = tokenizer . tokenize ( text )
input_ids = torch . LongTensor ( tokenizer . convert_tokens_to_ids ( tokenized_token_list )). view ( 1 , - 1 )
# compute hidden states
representation = model ( input_ids ). last_hidden_state # [1, seqlen, embed_dim] python version : 3.8
pip3 install -r requirements.txtVeuillez vous référer aux détails fournis dans le répertoire ./pretraining_data.
Veuillez vous référer aux détails fournis dans le répertoire ./pretraining.
Veuillez vous référer aux détails fournis dans ./english_benchmark Directory.
chmod +x ./download_benchmark_data.sh
./download_benchmark_data.sh Veuillez vous référer aux détails fournis dans le répertoire ./Chinese_Benchmark.
Nous fournissons tout le code essentiel pour reproduire les résultats (les images ci-dessous) fournies dans notre section d'analyse. Les codes et instructions connexes se trouvent dans le répertoire ./analysis. Amusez-vous!
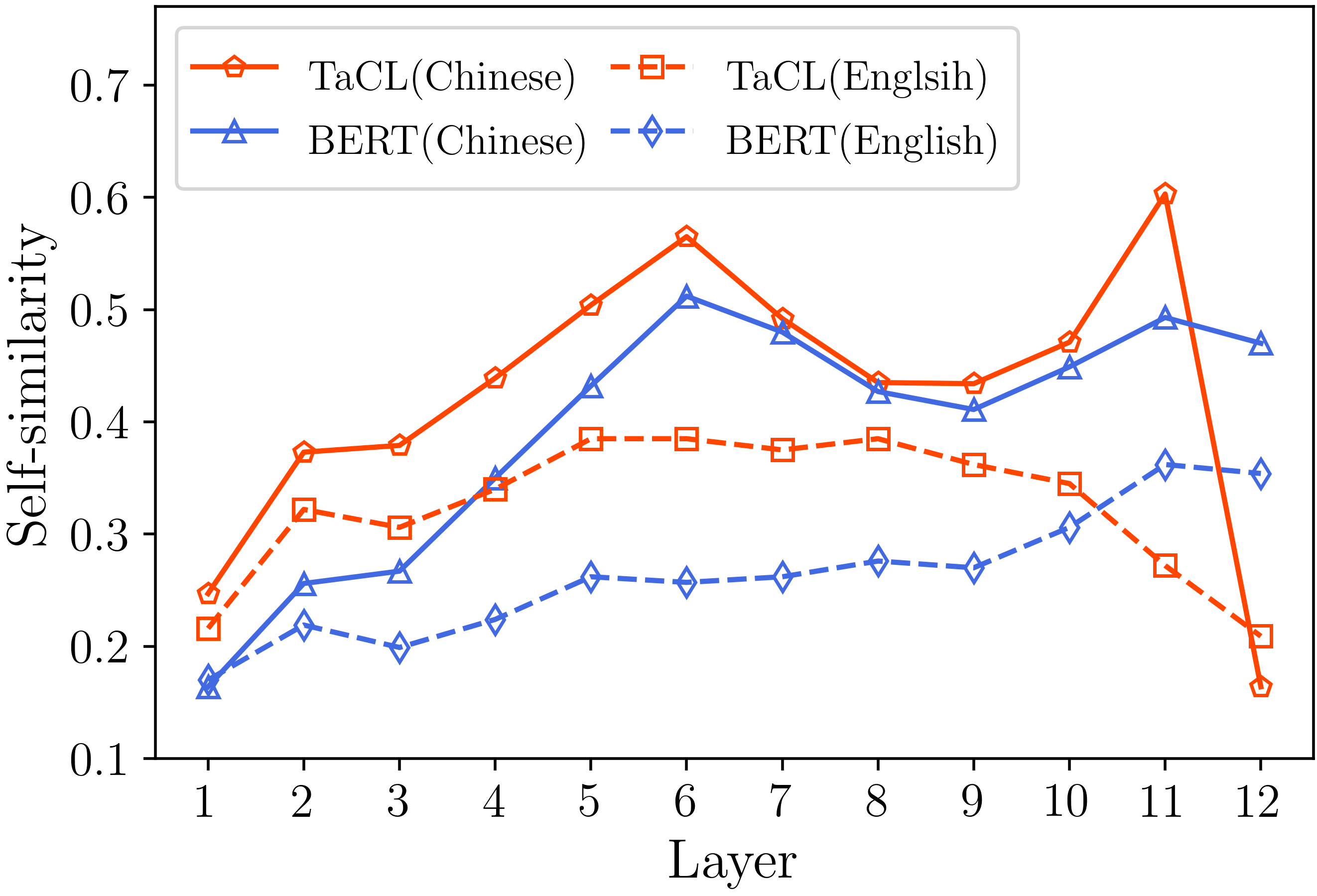
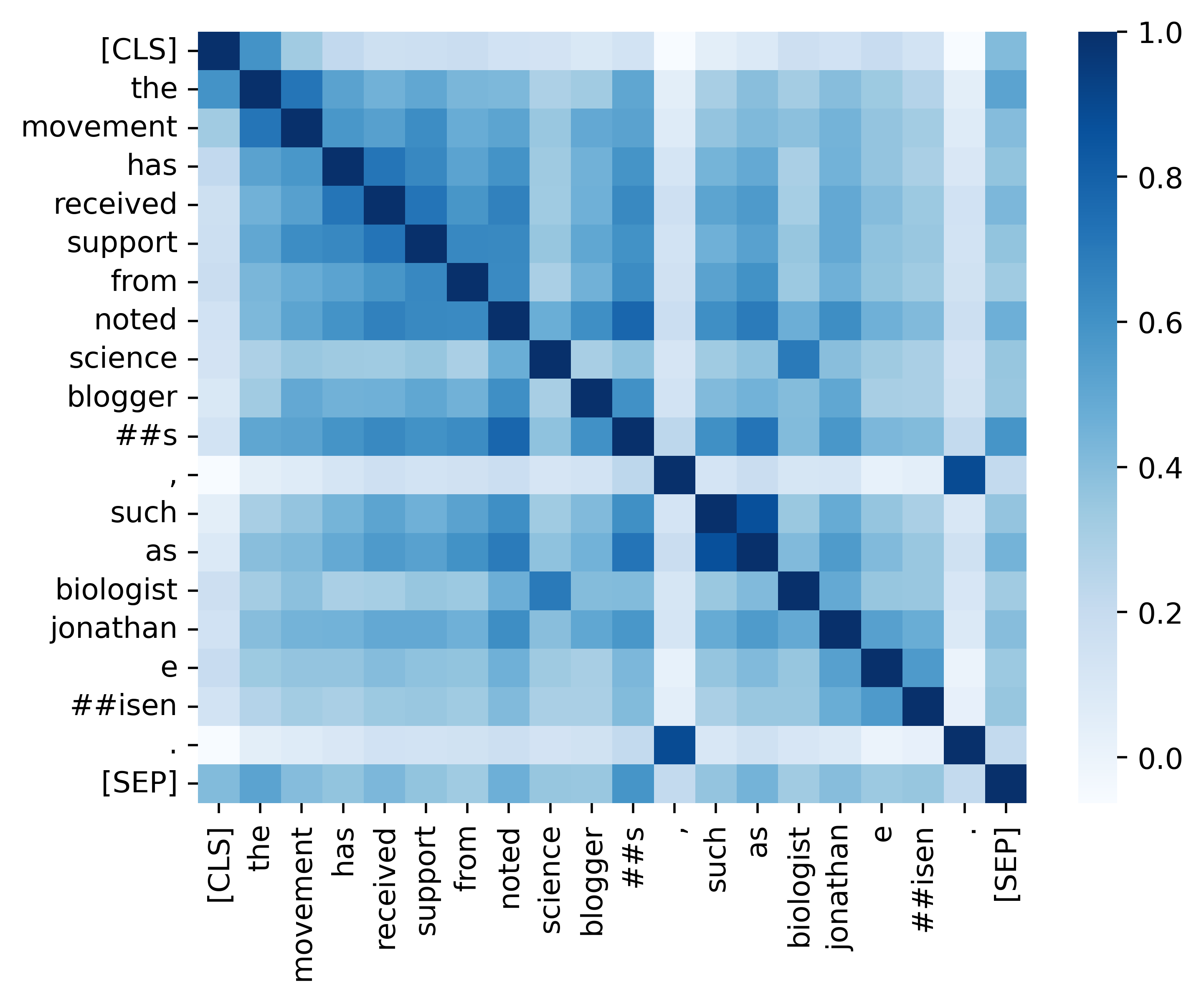
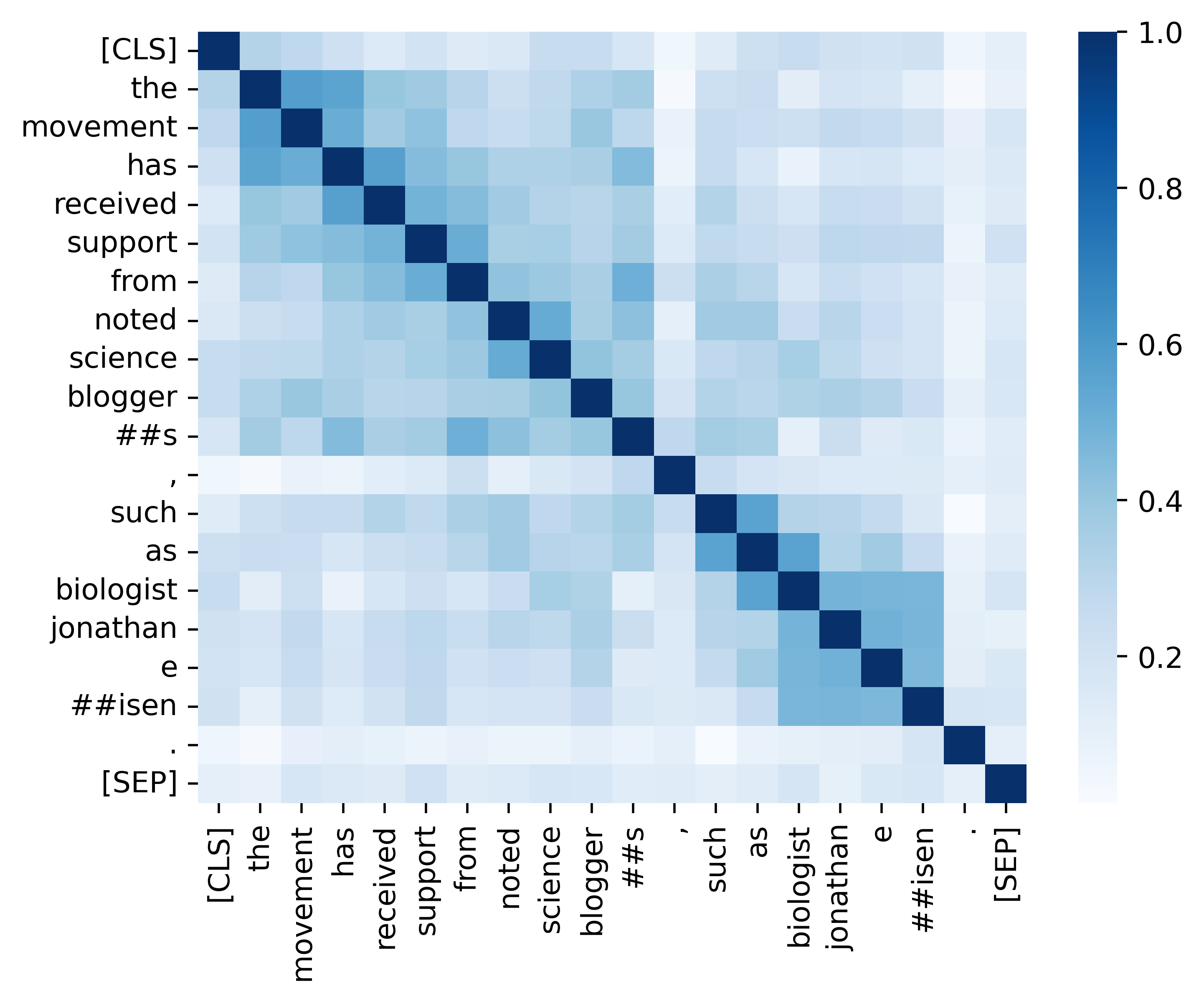
Si vous trouvez notre papier et nos ressources utiles, veuillez citer notre papier: notre papier: notre papier:
@article { DBLP:journals/corr/abs-2111-04198 ,
author = { Yixuan Su and
Fangyu Liu and
Zaiqiao Meng and
Tian Lan and
Lei Shu and
Ehsan Shareghi and
Nigel Collier } ,
title = { TaCL: Improving {BERT} Pre-training with Token-aware Contrastive Learning } ,
journal = { CoRR } ,
volume = { abs/2111.04198 } ,
year = { 2021 } ,
url = { https://arxiv.org/abs/2111.04198 } ,
eprinttype = { arXiv } ,
eprint = { 2111.04198 } ,
timestamp = { Wed, 10 Nov 2021 16:07:30 +0100 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2111-04198.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}Si vous avez des questions, n'hésitez pas à me contacter via ([email protected]).


