TaCL
1.0.0
著者:Yixuan Su、Fangyu Liu、Zaiqiao Meng、Tian Lan、Lei Shu、Ehsan Shareghi、およびNigel Collier
私たちの論文のコード:TACL:トークンを意識するコントラスト学習でバート前訓練を改善する
[使用中文tacl-bert进行中文命名实体识别及中文分词教程]
BertやRobertaなどの仮面言語モデル(MLM)は、過去数年間で自然言語の理解の分野に革命をもたらしました。ただし、既存の事前に訓練されたMLMは、表現空間全体の狭いサブセットを占めるトークン表現の異方性分布をしばしば出力します。このようなトークン表現は、特に明確なトークンの差別的な意味的な意味を要求するタスクにとって理想的ではありません。この作業では、 TACL ( t oken- aware c ontrastive lの獲得)を提案します。これは、トークン表現の等方性および識別的分布を学習することをBertが奨励する新しい継続的なトレーニング前アプローチです。 TACLは完全に監視されていないため、追加のデータは必要ありません。幅広い英語と中国のベンチマークでアプローチを広範囲にテストします。結果は、TACLが元のBertモデルに対して一貫した顕著な改善をもたらすことを示しています。さらに、詳細な分析を実施して、アプローチのメリットと内部労働を明らかにします。
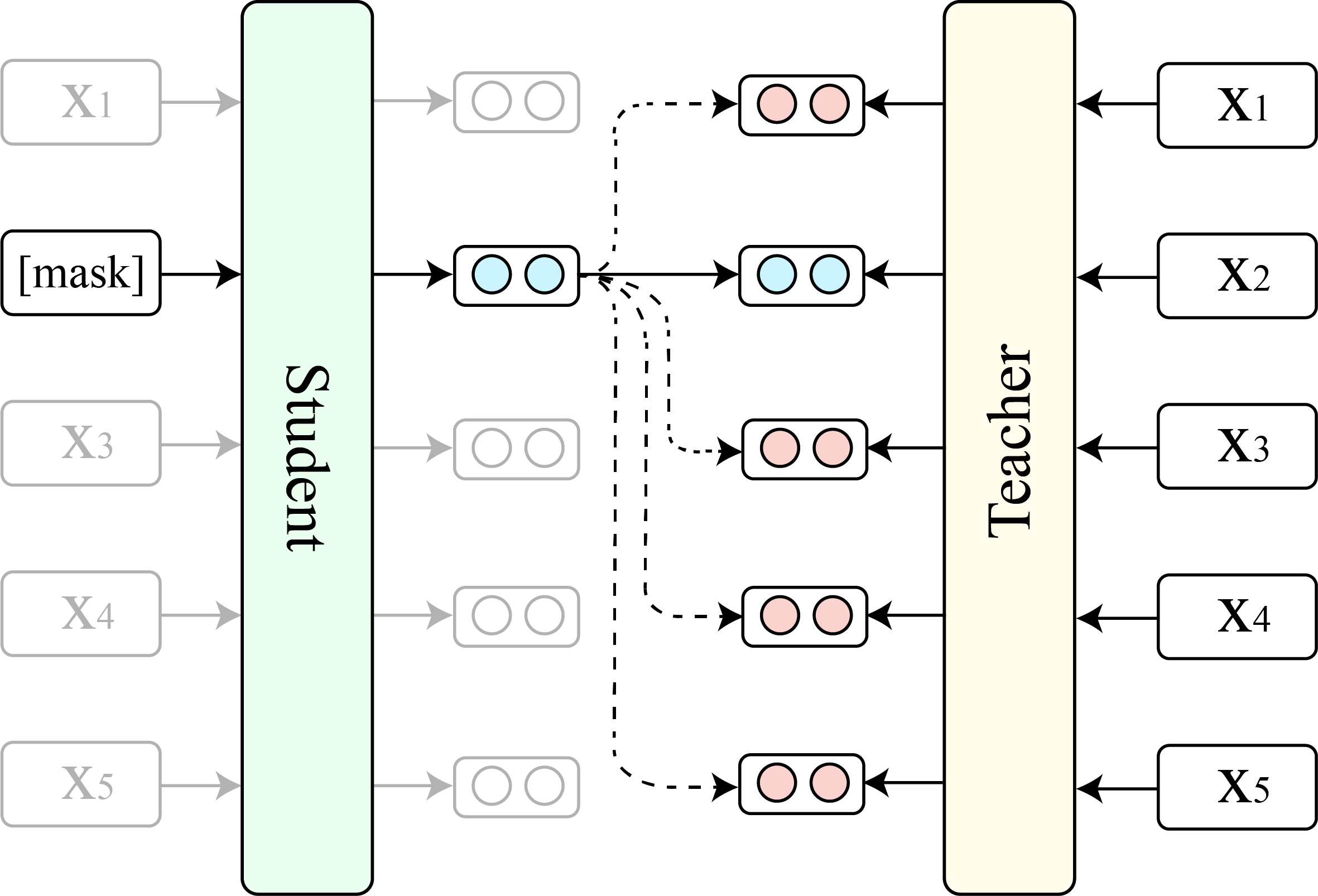
TACL(ベースバージョン)とオリジナルのBert(ベースバージョン)の比較を示します。
(1)チームの英語のベンチマーク結果(Rajpurkar et al。、2018) (dev set)および接着剤(Wang et al。、2019)平均スコア。
| モデル | 分隊1.1(em/f1) | 分隊2.0(EM/F1) | 接着平均 |
|---|---|---|---|
| バート | 80.8/88.5 | 73.4/76.8 | 79.6 |
| TACL | 81.6/89.0 | 74.4/77.5 | 81.2 |
(2)4つのNERタスク(MSRA、Ontonotes、Resume、およびWeibo)および3つの中国語単語セグメンテーション(CWS)タスク(PKU、Cityu、およびAS)の中国のベンチマーク結果(テストセットF1)。
| モデル | MSRA | ontonotes | 再開する | ワイボ | PKU | Cityu | として |
|---|---|---|---|---|---|---|---|
| バート | 94.95 | 80.14 | 95.53 | 68.20 | 96.50 | 97.60 | 96.50 |
| TACL | 95.44 | 82.42 | 96.45 | 69.54 | 96.75 | 98.16 | 96.75 |
| モデル名 | モデルアドレス |
|---|---|
| 英語( Cambridgeltl/TACL-BERT-BASE-UNCASED ) | リンク |
| 中国人( cambridgeltl/tacl-bert-base-chinese ) | リンク |
import torch
# initialize model
from transformers import AutoModel , AutoTokenizer
model_name = 'cambridgeltl/tacl-bert-base-uncased'
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
# create input ids
text = '[CLS] clbert is awesome. [SEP]'
tokenized_token_list = tokenizer . tokenize ( text )
input_ids = torch . LongTensor ( tokenizer . convert_tokens_to_ids ( tokenized_token_list )). view ( 1 , - 1 )
# compute hidden states
representation = model ( input_ids ). last_hidden_state # [1, seqlen, embed_dim] python version : 3.8
pip3 install -r requirements.txt./pretraining_dataディレクトリで提供される詳細を参照してください。
./pretrainingディレクトリで提供される詳細を参照してください。
./english_benchmarkディレクトリで提供される詳細を参照してください。
chmod +x ./download_benchmark_data.sh
./download_benchmark_data.sh ./chinese_benchmarkディレクトリで提供される詳細を参照してください。
分析セクションに記載されている結果(以下の画像)を再現するためのすべての重要なコードを提供します。関連するコードと命令は、./Analysisディレクトリにあります。楽しむ!
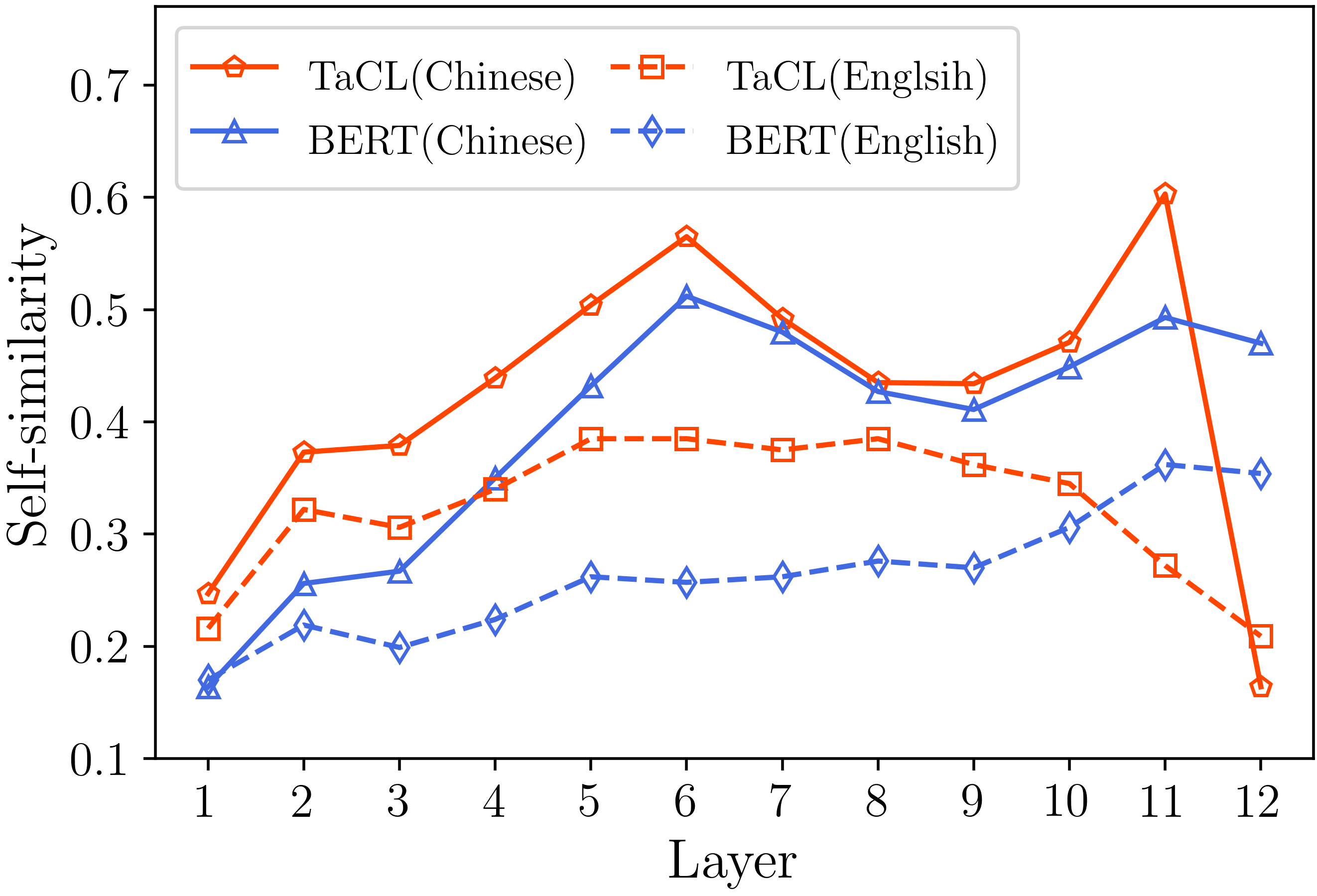
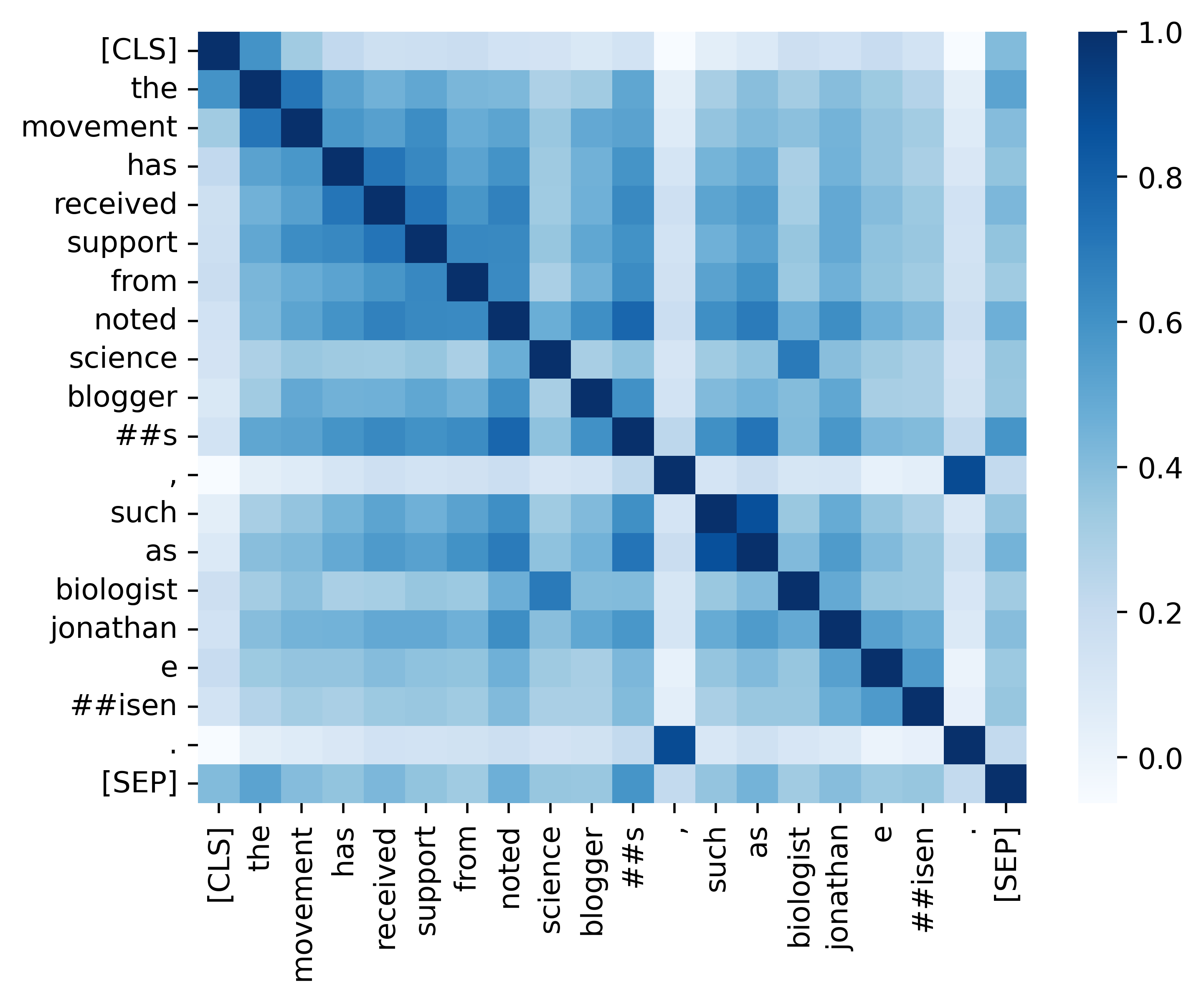
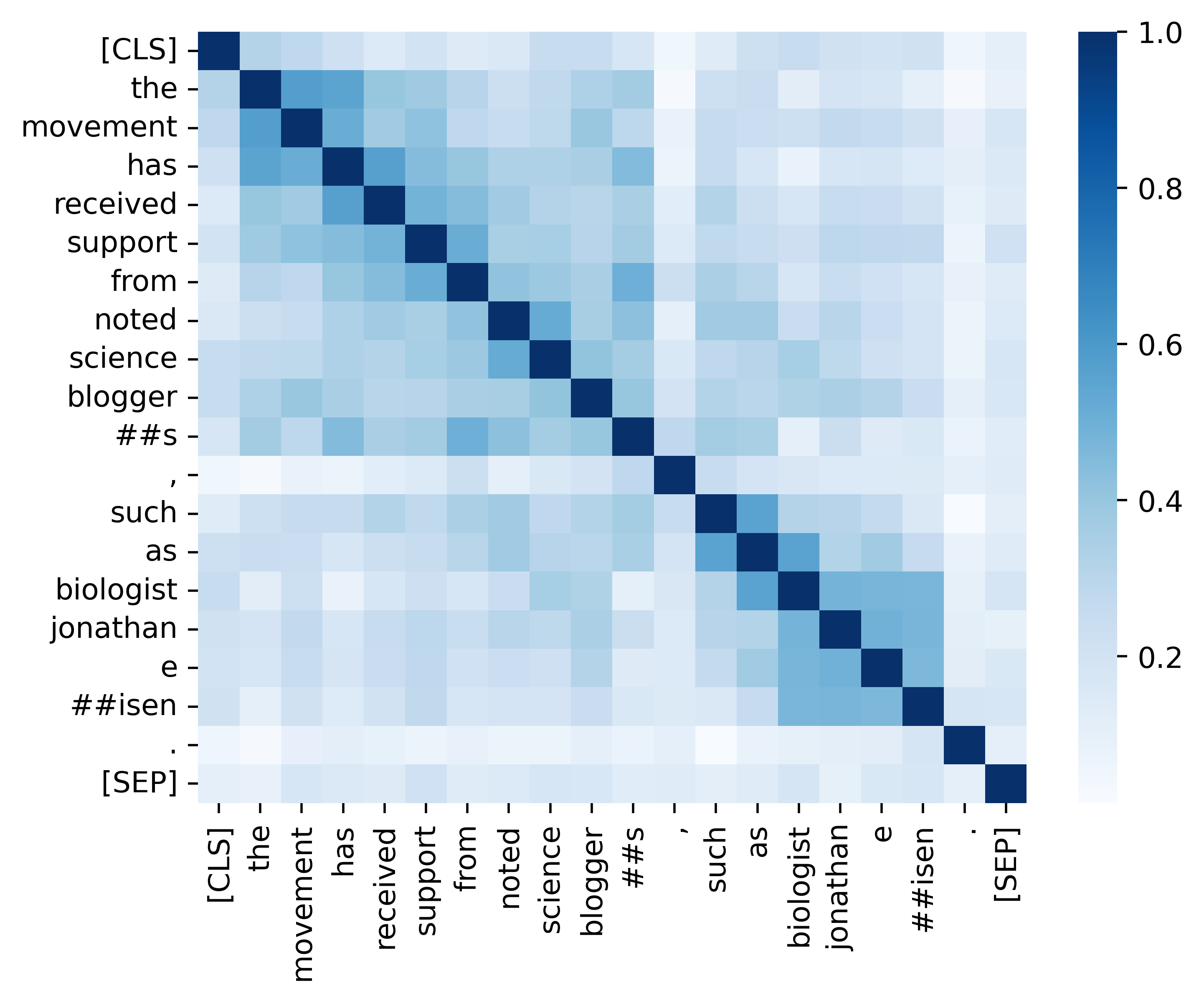
私たちの論文とリソースが便利だと思ったら、私たちの論文を引用してください。
@article { DBLP:journals/corr/abs-2111-04198 ,
author = { Yixuan Su and
Fangyu Liu and
Zaiqiao Meng and
Tian Lan and
Lei Shu and
Ehsan Shareghi and
Nigel Collier } ,
title = { TaCL: Improving {BERT} Pre-training with Token-aware Contrastive Learning } ,
journal = { CoRR } ,
volume = { abs/2111.04198 } ,
year = { 2021 } ,
url = { https://arxiv.org/abs/2111.04198 } ,
eprinttype = { arXiv } ,
eprint = { 2111.04198 } ,
timestamp = { Wed, 10 Nov 2021 16:07:30 +0100 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2111-04198.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
}ご質問がある場合は、([email protected])からお気軽にお問い合わせください。


