multi task cs lm
1.0.0
การใช้งานการสร้างแบบจำลองภาษาสลับรหัสโดยใช้การเรียนรู้หลายงานที่รับรู้แบบไวยากรณ์ (การประชุมเชิงปฏิบัติการครั้งที่ 3 ในแนวทางการคำนวณในการสลับรหัสภาษาศาสตร์ ACL 2018) รหัสถูกเขียนใน Python โดยใช้ Pytorch
วัสดุเสริม (รวมถึงการกระจายของรถไฟ dev และการทดสอบ) สามารถพบได้ที่นี่
หากคุณใช้ซอร์สโค้ดหรือชุดข้อมูลใด ๆ ที่รวมอยู่ในชุดเครื่องมือนี้ในงานของคุณโปรดอ้างอิงกระดาษต่อไปนี้ bibtex แสดงอยู่ด้านล่าง:
@inproceedings {W18-3207
ผู้แต่ง = "Winata, Genta Indra
และ Madotto, Andrea
และวู Chien-Sheng
และ Fung, Pascale ",
title = "การสร้างแบบจำลองภาษาสลับโค้ดโดยใช้การเรียนรู้หลายงานที่รับรู้ไวยากรณ์"
booktitle = "การดำเนินการประชุมเชิงปฏิบัติการครั้งที่สามเกี่ยวกับวิธีการคำนวณเพื่อการสลับรหัสภาษาศาสตร์"
ปี = "2018"
Publisher = "สมาคมเพื่อการคำนวณภาษาศาสตร์"
หน้า = "62--67"
ตำแหน่ง = "เมลเบิร์นออสเตรเลีย"
url = "http://aclweb.org/anthology/w18-3207"
-
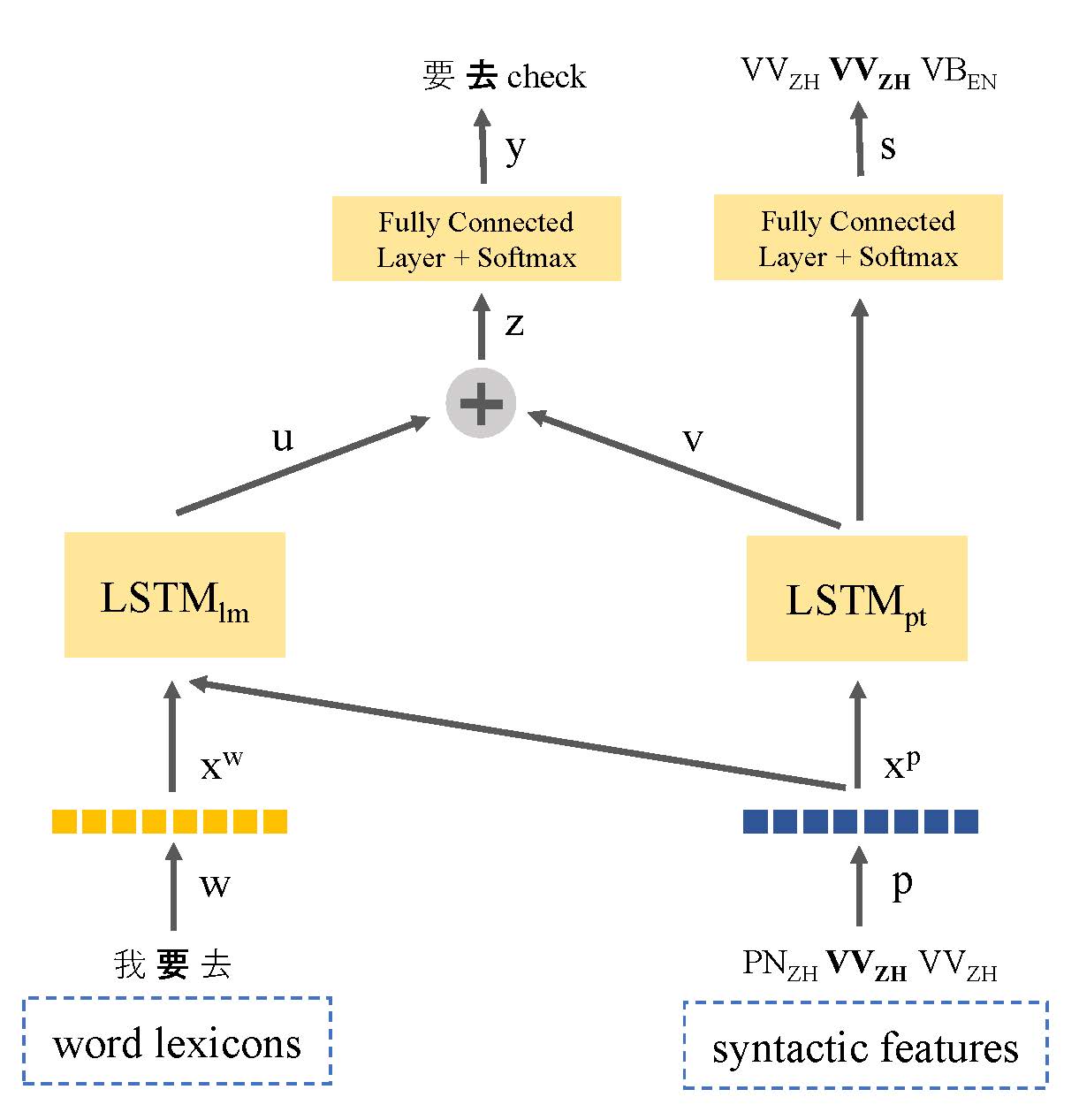
การขาดข้อมูลข้อความเป็นปัญหาสำคัญในการสร้างแบบจำลองภาษาสลับรหัส ในบทความนี้เราแนะนำรูปแบบภาษาที่ใช้การเรียนรู้แบบหลายงานซึ่งแบ่งปันการแสดงทางไวยากรณ์ของภาษาเพื่อใช้ประโยชน์จากข้อมูลภาษาศาสตร์และแก้ไขปัญหาข้อมูลทรัพยากรต่ำ โมเดลของเราร่วมกันเรียนรู้ทั้งการสร้างแบบจำลองภาษาและการติดแท็กส่วนหนึ่งของคำพูดที่สลับรหัส ด้วยวิธีนี้แบบจำลองสามารถระบุตำแหน่งของจุดเปลี่ยนรหัสและปรับปรุงการทำนายคำถัดไป วิธีการของเรามีประสิทธิภาพสูงกว่ารูปแบบภาษาที่ใช้มาตรฐาน LSTM โดยมีการปรับปรุง 9.7% และ 7.4% ในความงุนงงในชุดข้อมูล Seame Phase I และ Phase II ตามลำดับ
Seame Corpus จาก LDC: การสลับรหัสภาษาจีน-อังกฤษในเอเชียตะวันออกเฉียงใต้
งานหลายชิ้น
❱❱❱ python main_multi_task.py --tied --clip=0.25 --dropout=0.4 --postagdropout=0.4 --p=0.25 --nhid=500 --postagnhid=500 --emsize=500 --postagemsize=500 --cuda --data=../data/seame_phase2

