multi task cs lm
1.0.0
구문 인식 멀티 태스킹 학습 (언어 코드 전환, ACL 2018의 계산 접근법의 3 번째 워크숍)을 사용한 코드 전환 언어 모델링 구현. 이 코드는 Pytorch를 사용하여 파이썬으로 작성됩니다.
보충 자료 (열차, 개발 및 시험의 분포 포함)는 여기에서 찾을 수 있습니다.
작업 에서이 툴킷에 포함 된 소스 코드 또는 데이터 세트를 사용하는 경우 다음 논문을 인용하십시오. Bibtex는 다음과 같습니다.
@InProCeedings {W18-3207,
저자 = "Winata, Genta Indra
그리고 Madotto, Andrea
그리고 Wu, Chien-Sheng
그리고 Fung, Pascale ",
title = "구문 인식 멀티 태스킹 학습을 사용한 코드 전환 언어 모델링",
Booktitle = "언어 코드 전환에 대한 계산 접근 방식에 대한 세 번째 워크숍의 절차",
년 = "2018",
게시자 = "계산 언어학 협회",
pages = "62--67",
위치 = "호주 멜버른",
url = "http://aclweb.org/anthology/w18-3207"
}
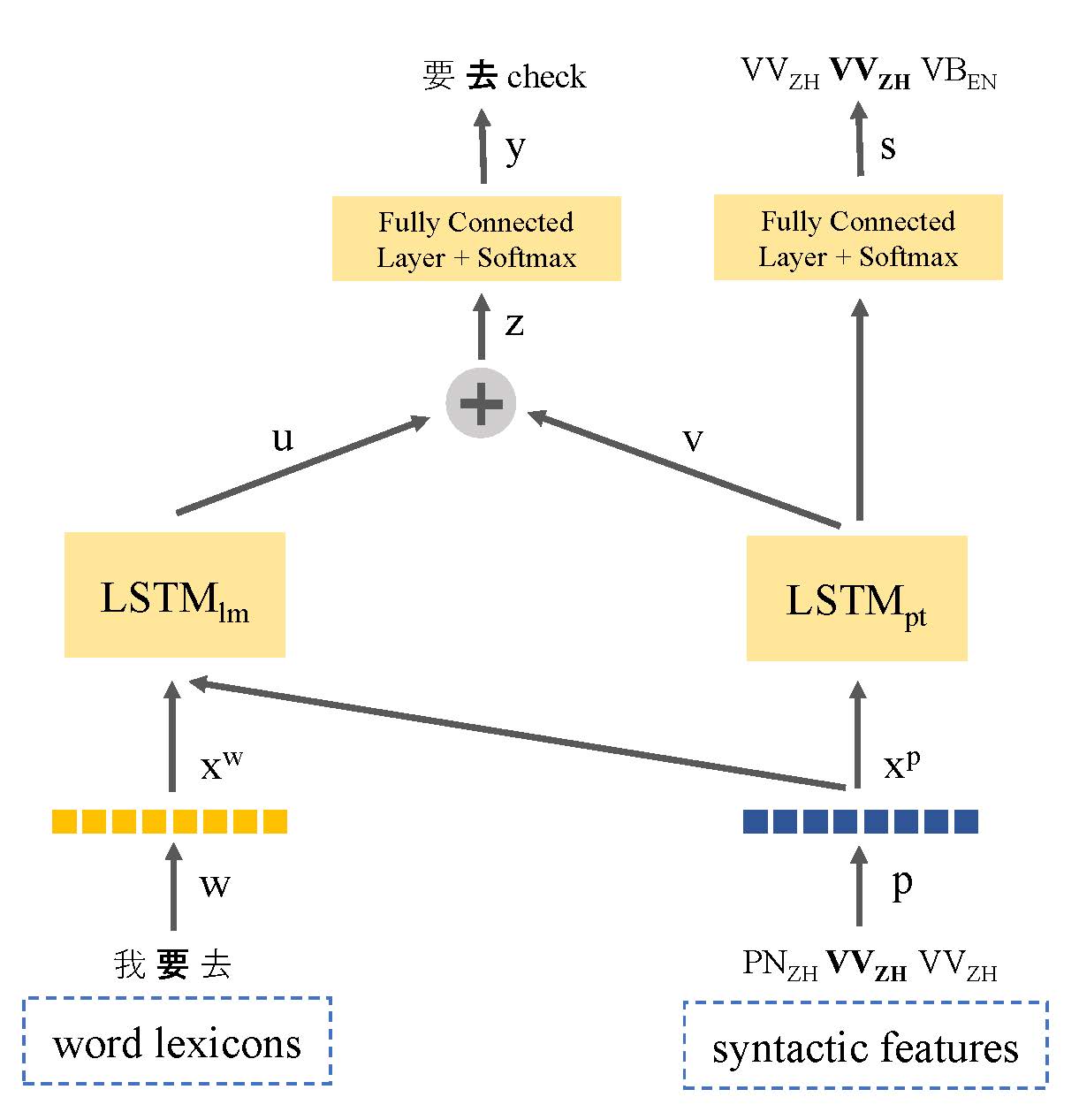
텍스트 데이터 부족은 코드 전환 언어 모델링의 주요 문제였습니다. 이 논문에서는 언어 정보를 활용하고 낮은 리소스 데이터 문제를 해결하기 위해 언어의 구문 표현을 공유하는 멀티 태스킹 학습 기반 언어 모델을 소개합니다. 우리의 모델은 코드 전환 발화에 대한 언어 모델링과 부품 태그를 모두 배웁니다. 이러한 방식으로 모델은 코드 전환점의 위치를 식별하고 다음 단어의 예측을 향상시킬 수 있습니다. 우리의 접근 방식은 표준 LSTM 기반 언어 모델을 능가하며 Seame Phase I 및 Phase II 데이터 세트에서 각각 9.7% 및 7.4%의 개선이 가능합니다.
LDC의 Seame Corpus : 동남아시아의 만다린-영어 코드 전환
멀티 태스크
❱❱❱ python main_multi_task.py --tied --clip=0.25 --dropout=0.4 --postagdropout=0.4 --p=0.25 --nhid=500 --postagnhid=500 --emsize=500 --postagemsize=500 --cuda --data=../data/seame_phase2

