multi task cs lm
1.0.0
La mise en œuvre de la modélisation du langage de commutation de code à l'aide de l'apprentissage multi-tâches (3e atelier dans les approches de calcul linguistique dans le commutateur de code linguistique, ACL 2018). Le code est écrit en python à l'aide de pytorch.
Des documents supplémentaires (y compris la distribution du train, du développement et du test) peuvent être trouvés ici.
Si vous utilisez des codes source ou des ensembles de données inclus dans cette boîte à outils dans votre travail, veuillez citer l'article suivant. Le bibtex est répertorié ci-dessous:
@Inproceedings {w18-3207,
Auteur = "Winata, Genta Indra
Et Madotto, Andrea
et wu, chien-sheng
et fung, pascale ",
title = "Modélisation du langage de commutation de code à l'aide d'apprentissage multi-tâches de syntaxe",
booktitle = "Actes du troisième atelier sur les approches informatiques de la commutation linguistique du code",
année = "2018",
Publisher = "Association for Computational Linguistics",
pages = "62--67",
emplacement = "Melbourne, Australie",
url = "http://aclweb.org/anthology/w18-3207"
}
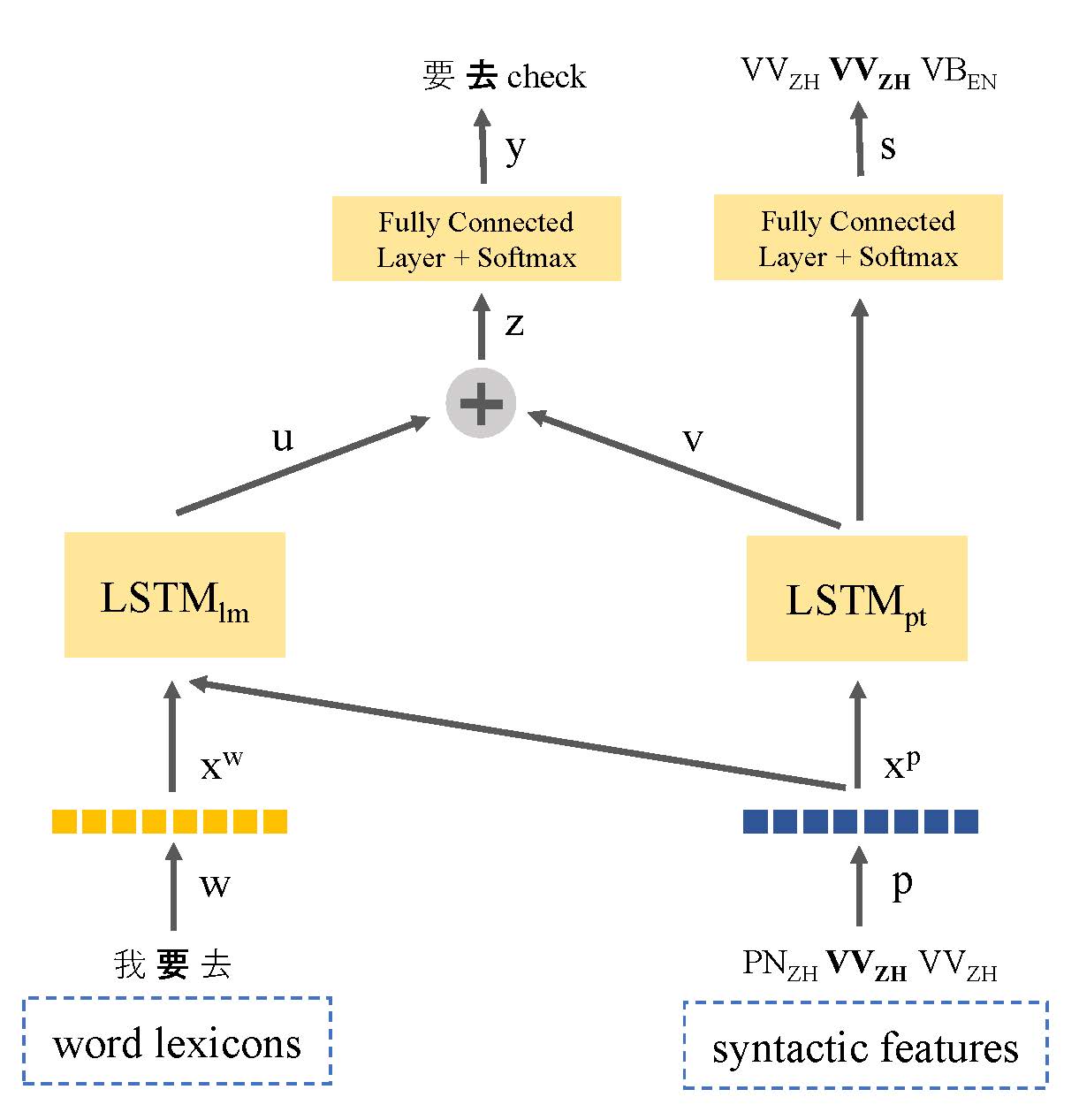
Le manque de données texte a été le problème majeur sur la modélisation du langage de commutation de code. Dans cet article, nous introduisons un modèle de langue basé sur l'apprentissage multi-tâches qui partage la représentation de la syntaxe des langues pour tirer parti des informations linguistiques et aborder le problème de données de ressources faible. Notre modèle apprend conjointement à la fois la modélisation du langage et le marquage d'une partie du discours sur les énoncés à commutation de code. De cette façon, le modèle est en mesure d'identifier l'emplacement des points de changement de code et améliore la prédiction du mot suivant. Notre approche surpasse le modèle de langage basé sur LSTM standard, avec une amélioration de 9,7% et 7,4% en perplexité sur le jeu de données de phase I et de phase II Seame respectivement.
Seame Corpus de LDC: commutation de code Mandarin-English en Asie du Sud-Est
Multi-tâches
❱❱❱ python main_multi_task.py --tied --clip=0.25 --dropout=0.4 --postagdropout=0.4 --p=0.25 --nhid=500 --postagnhid=500 --emsize=500 --postagemsize=500 --cuda --data=../data/seame_phase2

