multi task cs lm
1.0.0
Syntax-awareマルチタスク学習を使用したコードスイッチング言語モデリングの実装(言語コードスイッチング、ACL 2018の計算アプローチの第3ワークショップ)論文。このコードは、Pytorchを使用してPythonで記述されています。
補足資料(列車、開発、テストの流通を含む)はここにあります。
このツールキットに含まれるソースコードまたはデータセットを使用している場合は、次の論文を引用してください。 bibtexは以下にリストされています。
@inproceedings {w18-3207、
Author = "Winata、Genta Indra
マドット、アンドレア
ウー、チエン・シェン
とfung、Pascale」、
title = "構文対応マルチタスク学習を使用したコードスイッチング言語モデリング"、
booktitle = "言語コードスイッチングへの計算アプローチに関する3回目のワークショップの議事録"、
year = "2018"、
Publisher = "Computational Linguisticsの協会"、
pages = "62--67"、
場所= "オーストラリア、メルボルン"、
url = "http://aclweb.org/anthology/w18-3207"
}
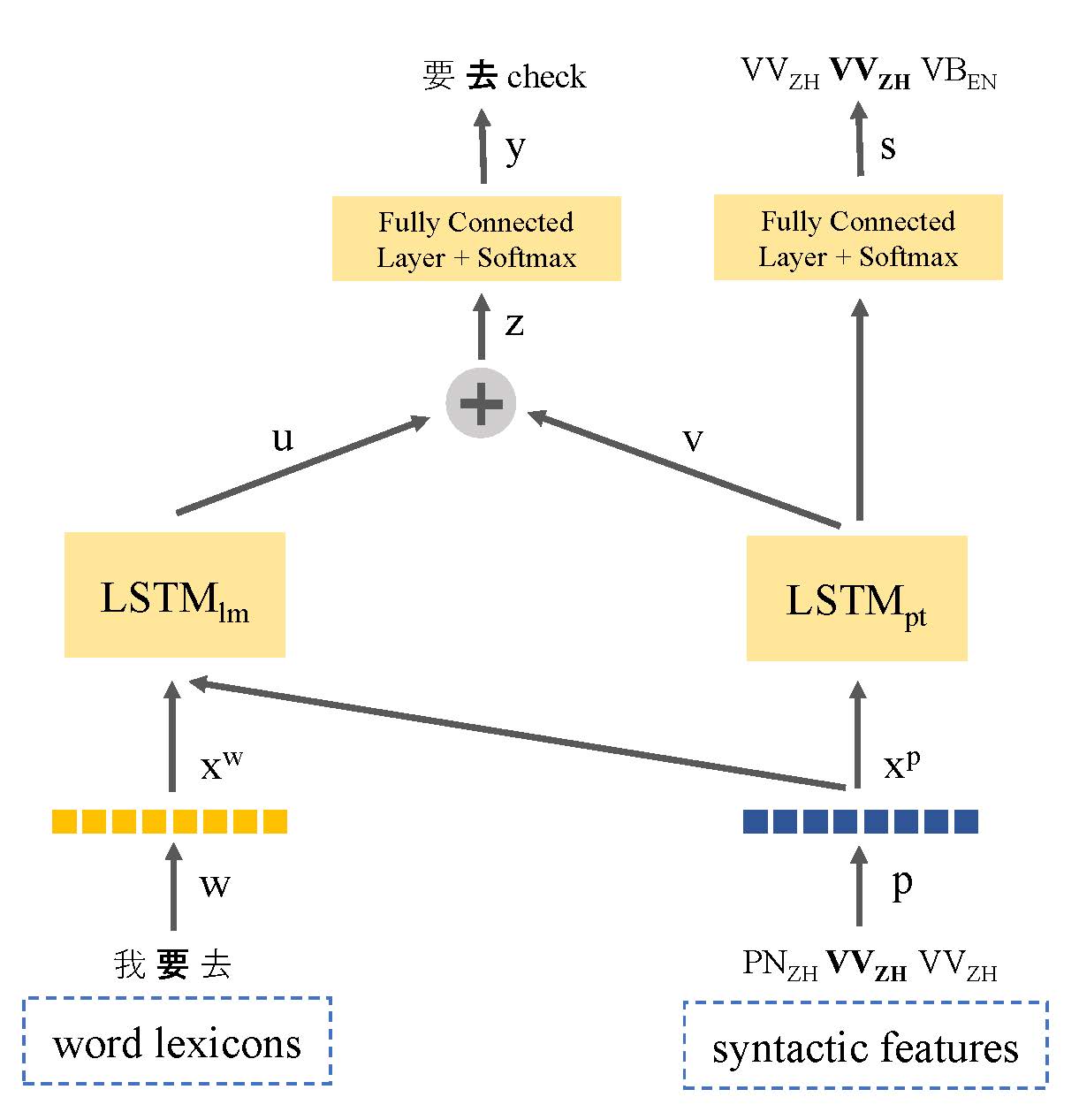
テキストデータの欠如は、コードスイッチング言語モデリングに関する主要な問題です。この論文では、言語情報を活用して低リソースデータの問題に取り組むために言語の構文表現を共有するマルチタスク学習ベースの言語モデルを紹介します。私たちのモデルは、コードスイッチされた発話に関する言語モデリングとスピーチの一部のタグ付けの両方を共同で学習します。このようにして、モデルはコードスイッチングポイントの位置を識別し、次の単語の予測を改善することができます。当社のアプローチは、標準のLSTMベースの言語モデルよりも優れており、SeameフェーズIとフェーズIIデータセットでそれぞれ9.7%と7.4%の困惑が改善されています。
LDCのSeame Corpus:東南アジアのマンダリン - 英語コードスイッチング
マルチタスク
❱❱❱ python main_multi_task.py --tied --clip=0.25 --dropout=0.4 --postagdropout=0.4 --p=0.25 --nhid=500 --postagnhid=500 --emsize=500 --postagemsize=500 --cuda --data=../data/seame_phase2

