multi task cs lm
1.0.0
Die Implementierung von Code-Switching-Sprachmodellierung mithilfe von Syntax-bewusstem Multitasking-Lernmodell (3. Workshop in rechnerischen Ansätzen im sprachlichen Code-Switching, ACL 2018) Papier. Der Code ist in Python mit Pytorch geschrieben.
Zusätzliche Materialien (einschließlich der Verteilung von Zug, Entwickler und Test) finden Sie hier.
Wenn Sie Quellcodes oder Datensätze verwenden, die in diesem Toolkit in Ihrer Arbeit enthalten sind, geben Sie bitte das folgende Papier an. Das Bibtex ist unten aufgeführt:
@InProceedings {W18-3207,
Autor = "Winata, Genta Indra
und Madotto, Andrea
und Wu, Chien-Sheng
und Pilze, Pascale ",
title = "Code-Switching-Sprachmodellierung mit syntax-bewusstem Multi-Task-Lernen",
boottitle = "Proceedings des dritten Workshops zu rechnerischen Ansätzen für sprachliche Code-Switching",
Jahr = "2018",
Publisher = "Assoziation für Computer -Linguistik",
Seiten = "62-67",
Ort = "Melbourne, Australien",
url = "http://aclweb.org/anthology/w18-3207"
}
Die mangelnden Textdaten waren das Hauptproblem bei der Modellierung von Code-Switching-Sprachen. In diesem Artikel führen wir ein multi-task-lernbasiertes Sprachmodell vor, das die Syntax-Darstellung von Sprachen zur Nutzung sprachlicher Informationen und Anpassung des Problems mit niedriger Ressourcendaten aufweist. Unser Modell lernt gemeinsam sowohl die Sprachmodellierung als auch das Teil des Speech-Taggens für Code-Schalter-Äußerungen. Auf diese Weise kann das Modell den Ort von Code-Switching-Punkten identifizieren und die Vorhersage des nächsten Wortes verbessert. Unser Ansatz übertrifft das LSSTM -basierte Sprachmodell von Standard -LSTM -Basis mit einer Verbesserung von 9,7% bzw. 7,4% im Datensatz von Seame Phase I bzw. Phase II.
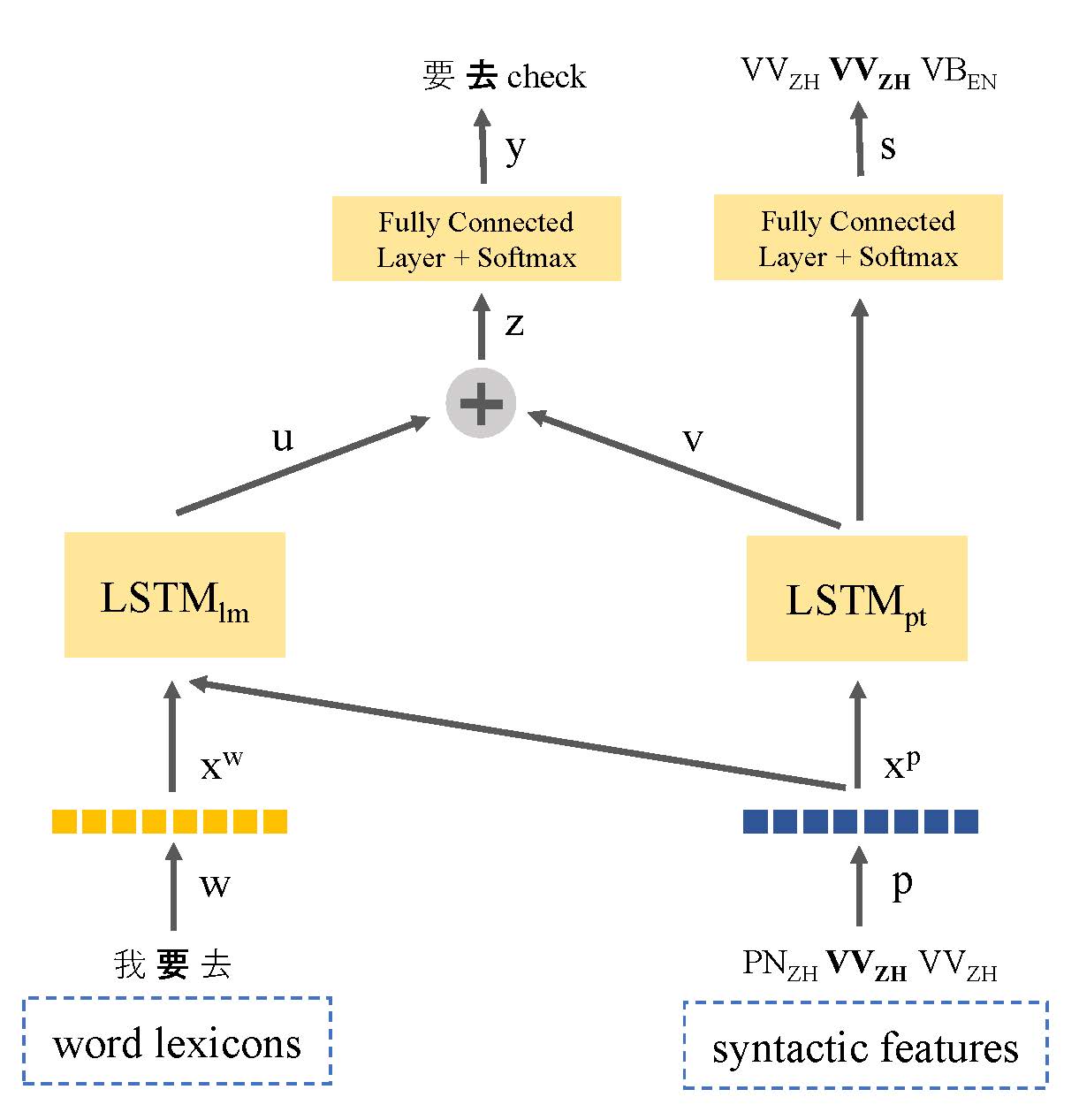
Seame Corpus von LDC: Mandarin-English-Code-Schalter in Südostasien
Multi-Task
❱❱❱ python main_multi_task.py --tied --clip=0.25 --dropout=0.4 --postagdropout=0.4 --p=0.25 --nhid=500 --postagnhid=500 --emsize=500 --postagemsize=500 --cuda --data=../data/seame_phase2

