multi task cs lm
1.0.0
تنفيذ نمذجة لغة تبديل التعليمات البرمجية باستخدام بناء الجملة المتعددة المهام (ورشة العمل الثالثة في الأساليب الحسابية في تبديل الكود اللغوي ، ACL 2018). الكود مكتوب في Python باستخدام Pytorch.
يمكن العثور على المواد التكميلية (بما في ذلك توزيع القطار ، DEV ، واختبار) هنا.
إذا كنت تستخدم أي رموز مصدر أو مجموعات بيانات مدرجة في مجموعة الأدوات هذه في عملك ، فيرجى الاستشهاد بالورقة التالية. bibtex مدرج أدناه:
inproceedings {W18-3207 ،
المؤلف = "Winata ، Genta Indra
ومادووتو ، أندريا
و وو ، شين شنغ
و Fung ، Pascale "،
TITLE = "نمذجة لغة تبديل الكود باستخدام التعلم متعدد المهام في بناء الجملة" ،
booktitle = "وقائع ورشة العمل الثالثة حول الأساليب الحسابية لتبديل الكود اللغوي" ،
السنة = "2018" ،
Publisher = "جمعية اللغويات الحسابية" ،
الصفحات = "62--67" ،
الموقع = "ملبورن ، أستراليا" ،
url = "http://aclweb.org/anthology/w18-3207"
}
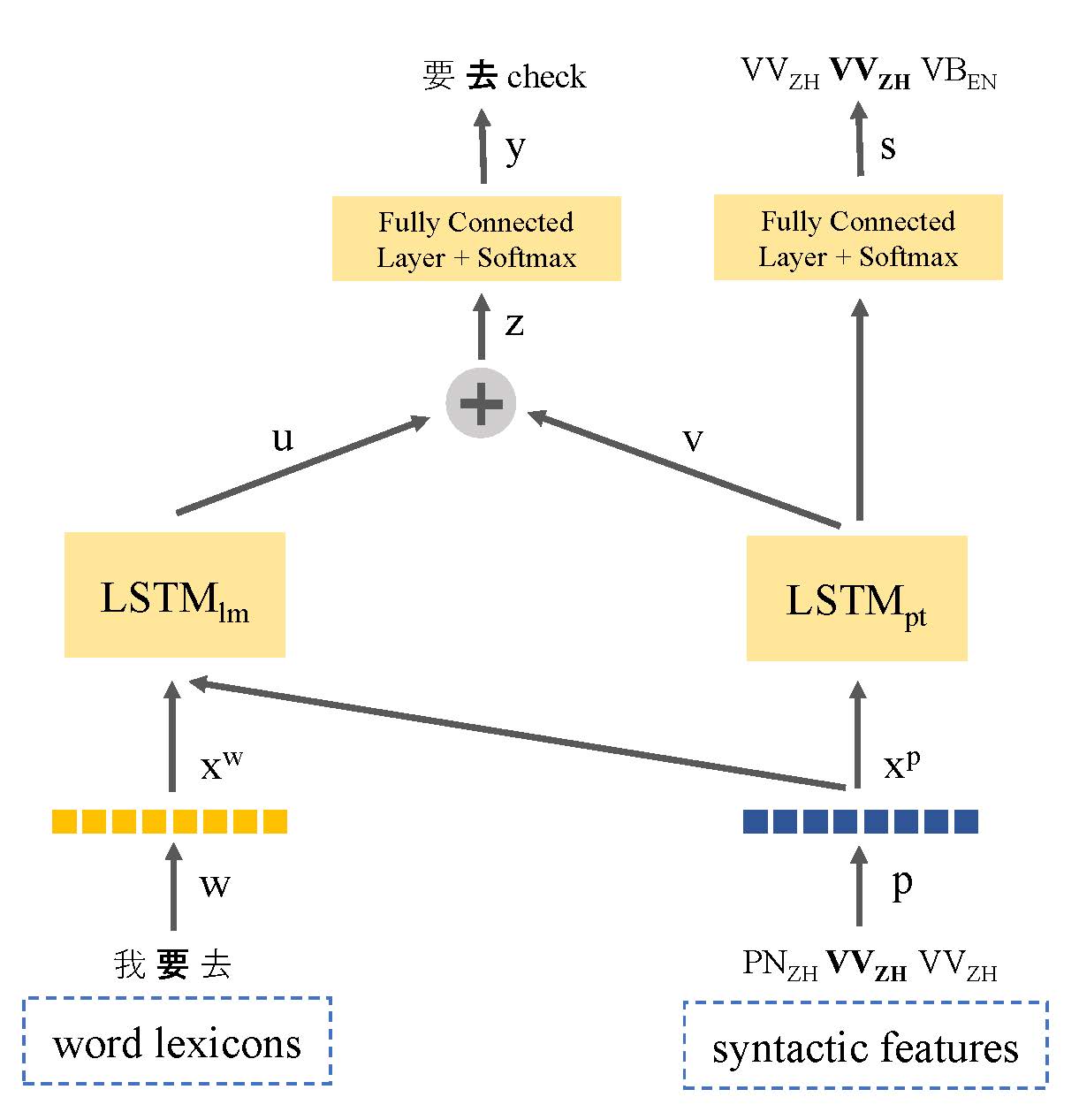
كان نقص بيانات النص هو المشكلة الرئيسية في نمذجة لغة تبديل الكود. في هذه الورقة ، نقدم نموذج لغة تعليمي متعدد المهام يشترك في تمثيل بناء الجملة للغات للاستفادة من المعلومات اللغوية ومعالجة مشكلة بيانات الموارد المنخفضة. يتعلم نموذجنا بشكل مشترك كل من نمذجة اللغة ووضع علامات على جزء من الكلام على الكلام التي يتم تبديل الكود. وبهذه الطريقة ، يكون النموذج قادرًا على تحديد موقع نقاط تبديل التعليمات البرمجية ويحسن التنبؤ بالكلمة التالية. يتفوق نهجنا على نموذج لغة LSTM القياسية ، مع تحسن قدره 9.7 ٪ و 7.4 ٪ في الحيرة في مجموعة بيانات المرحلة الأولى والمرحلة الثانية على التوالي.
Seame Corpus من LDC: تبديل الرمز الماندرين-الإنجليزي في جنوب شرق آسيا
متعددة المهام
❱❱❱ python main_multi_task.py --tied --clip=0.25 --dropout=0.4 --postagdropout=0.4 --p=0.25 --nhid=500 --postagnhid=500 --emsize=500 --postagemsize=500 --cuda --data=../data/seame_phase2

