multi task cs lm
1.0.0
Реализация языкового моделирования с переключением кода с использованием многозадачного обучения синтаксиса (3-й семинар в вычислительных подходах в лингвистическом переключении кода, ACL 2018). Код написан на Python с использованием Pytorch.
Дополнительные материалы (включая распределение поезда, разработчиков и теста) можно найти здесь.
Если вы используете какие -либо исходные коды или наборы данных, включенные в этот инструментарий в вашей работе, укажите следующую статью. Bibtex перечислен ниже:
@Inproceedings {w18-3207,
Автор = "Winata, Genta Indra
и Мадотто, Андреа
и Ву, Чиен-Шенг
и Fung, Pascale »,
title = "Моделирование языка переключения кода с использованием многозадачного обучения синтаксиса",
BookTitle = "Труды третьего семинара по вычислительным подходам к лингвистическому переключению кода",
Год = "2018",
Publisher = "Ассоциация вычислительной лингвистики",
страницы = "62--67",
местоположение = "Мельбурн, Австралия",
url = "http://aclweb.org/anthology/w18-3207"
}
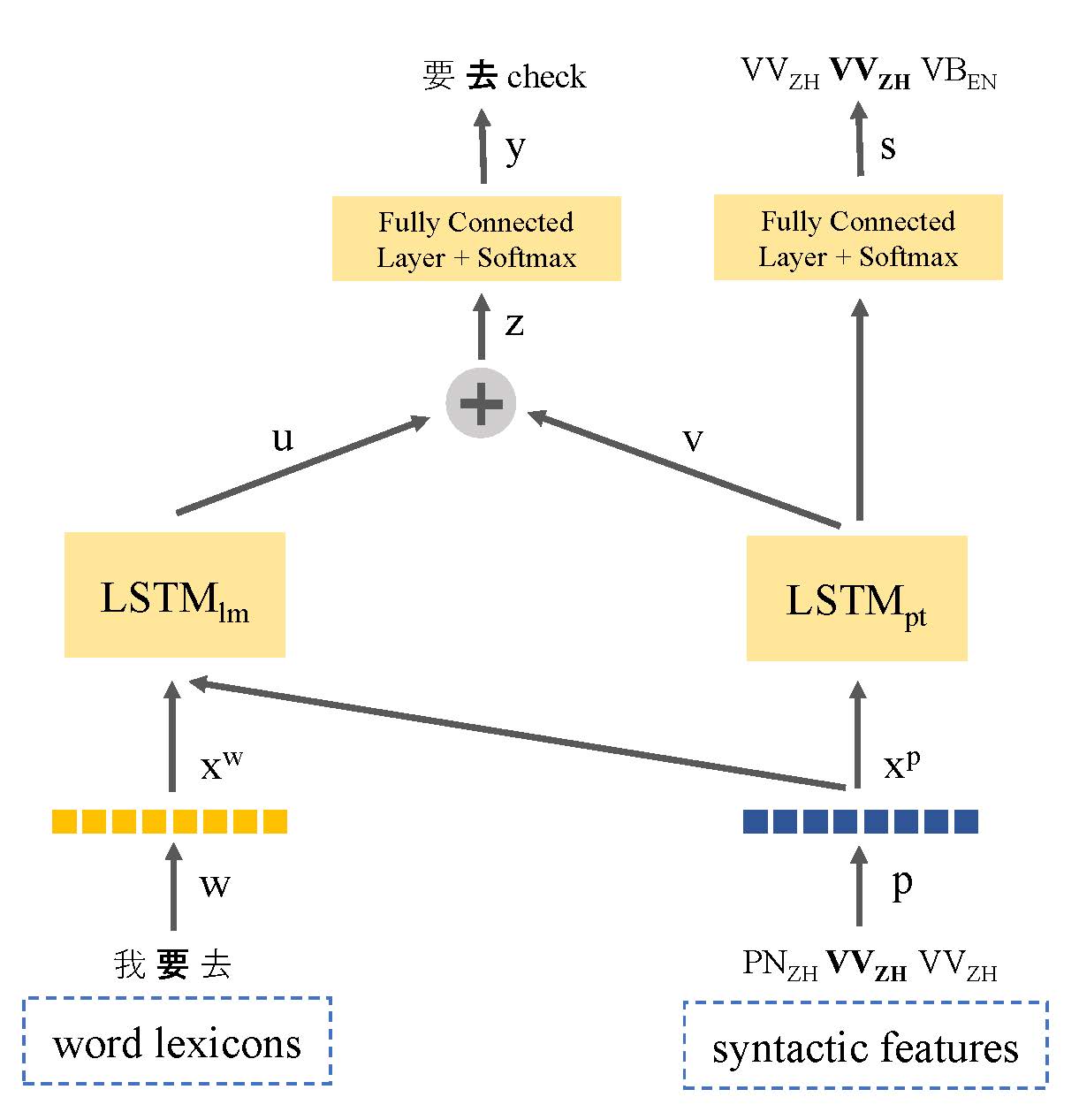
Отсутствие текстовых данных стало основной проблемой в отношении языкового моделирования кода. В этой статье мы вводим модель языка на основе многозадачке, которая разделяет синтаксис-представление языков для использования лингвистической информации и решения проблемы с низким ресурсом. Наша модель совместно изучает как языковое моделирование, так и теги-теги с речью на высказываниях, связанных с кодом. Таким образом, модель способна определить местоположение точек переключения кода и улучшать прогноз следующего слова. Наш подход превосходит стандартную языковую модель на основе LSTM с улучшением 9,7% и 7,4% в недоумении в наборе данных Meabe Fase I и Fase II соответственно.
Корпус Seade от LDC: переключение кодов мандарина в Юго-Восточной Азии
Многозадачная
❱❱❱ python main_multi_task.py --tied --clip=0.25 --dropout=0.4 --postagdropout=0.4 --p=0.25 --nhid=500 --postagnhid=500 --emsize=500 --postagemsize=500 --cuda --data=../data/seame_phase2

