multi task cs lm
1.0.0
Implementasi pemodelan bahasa pengalihan kode menggunakan Sintaks-Sadar Multi-Task Learning (Workshop ke-3 dalam Pendekatan Komputasi dalam Kertas Linguistic Code-Switching, ACL 2018). Kode ini ditulis dalam Python menggunakan Pytorch.
Bahan tambahan (termasuk distribusi kereta, dev, dan tes) dapat ditemukan di sini.
Jika Anda menggunakan kode sumber atau set data yang termasuk dalam toolkit ini dalam pekerjaan Anda, silakan kutip makalah berikut. Bibtex tercantum di bawah ini:
@InprOcedings {W18-3207,
penulis = "winata, genta indra
dan Madotto, Andrea
dan Wu, Chien-Sheng
dan fung, Pascale ",
title = "Pemodelan Bahasa Pengalihan Kode Menggunakan Pembelajaran Multi-Tass Sintaks-Aware",
booktitle = "Prosiding Lokakarya Ketiga tentang Pendekatan Komputasi untuk Pengalihan Kode Linguistik",
tahun = "2018",
Penerbit = "Asosiasi Linguistik Komputasi",
halaman = "62--67",
Lokasi = "Melbourne, Australia",
url = "http://aclweb.org/anthology/w18-3207"
}
Kurangnya data teks telah menjadi masalah utama pada pemodelan bahasa pengalihan kode. Dalam makalah ini, kami memperkenalkan model bahasa berbasis pembelajaran multi-tugas yang berbagi representasi sintaks bahasa untuk memanfaatkan informasi linguistik dan mengatasi masalah data sumber daya rendah. Model kami bersama-sama mempelajari pemodelan bahasa dan penandaan sebagian pada ucapan yang digerakkan oleh kode. Dengan cara ini, model ini dapat mengidentifikasi lokasi titik pengalihan kode dan meningkatkan prediksi kata berikutnya. Pendekatan kami mengungguli model bahasa berbasis LSTM standar, dengan peningkatan 9,7% dan 7,4% dalam kebingungan masing -masing pada dataset Fase I dan Fase II.
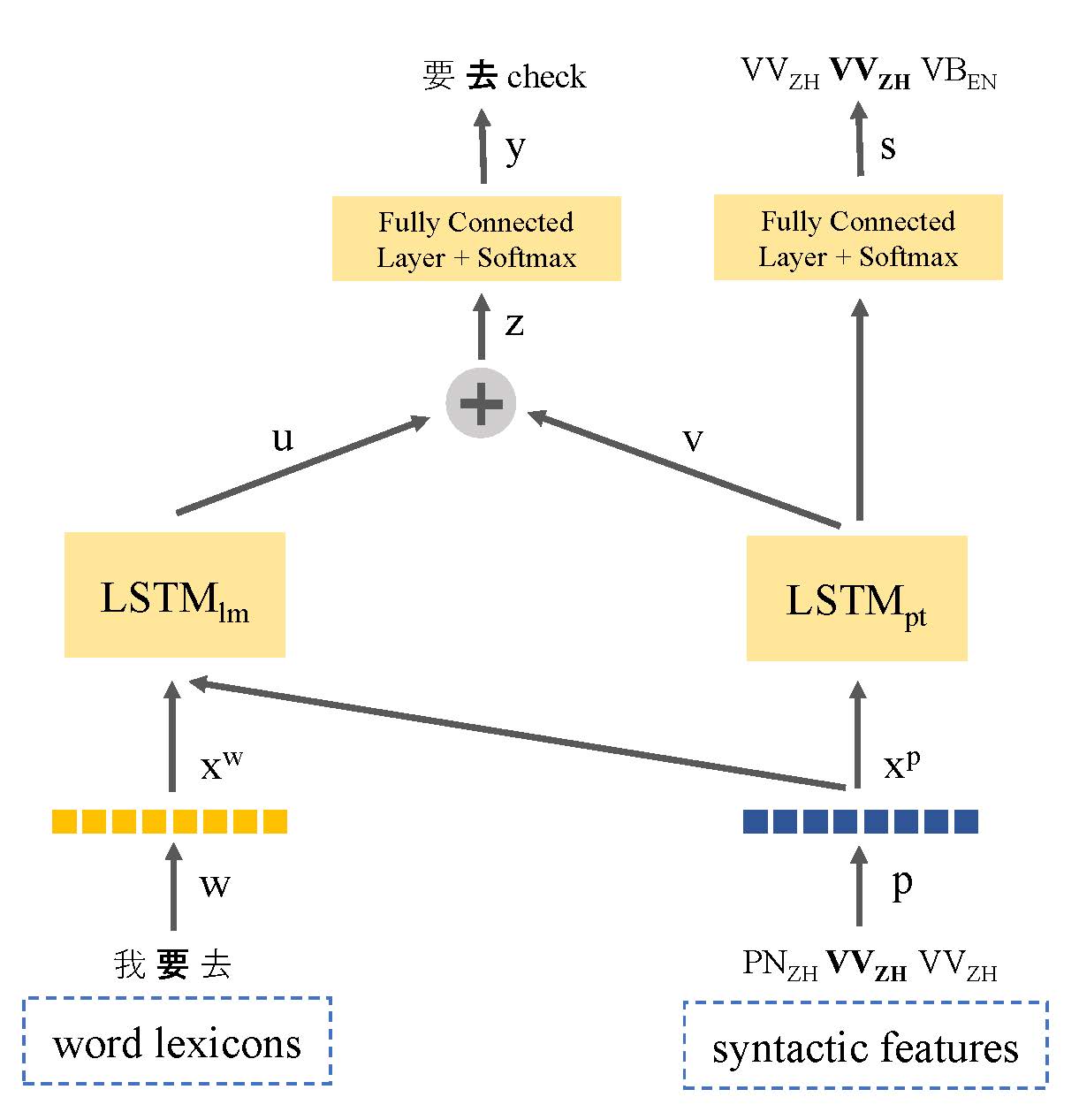
Seame Corpus dari LDC: Mandarin-English Code-Switching di Asia Tenggara
Multi-tugas
❱❱❱ python main_multi_task.py --tied --clip=0.25 --dropout=0.4 --postagdropout=0.4 --p=0.25 --nhid=500 --postagnhid=500 --emsize=500 --postagemsize=500 --cuda --data=../data/seame_phase2

