LLM-LORA-PEFT_ACCUMULATE
ยินดีต้อนรับสู่ที่เก็บ LLM-Lora-Peft_Accumulate !
พื้นที่เก็บข้อมูลนี้มีการใช้งานและการทดลองที่เกี่ยวข้องกับแบบจำลองภาษาขนาดใหญ่ (LLMS) โดยใช้ PEFT (การปรับค่าพารามิเตอร์ที่มีประสิทธิภาพอย่างละเอียด), LORA (การปรับระดับต่ำของแบบจำลองภาษาขนาดใหญ่) และ QLORA (ปริมาณ LLMs ที่มีอะแดปเตอร์ระดับต่ำ)
การโหลดโมเดลในความแม่นยำ 8 บิตสามารถบันทึกหน่วยความจำได้สูงสุด 4x เมื่อเทียบกับรุ่นที่มีความแม่นยำเต็มรูปแบบ

Peft ทำอะไร?
คุณเพิ่มอะแดปเตอร์ในโมเดล 8 บิตแช่แข็งได้อย่างง่ายดายซึ่งจะช่วยลดความต้องการหน่วยความจำของสถานะเครื่องมือเพิ่มประสิทธิภาพโดยการฝึกพารามิเตอร์เพียงเล็กน้อย
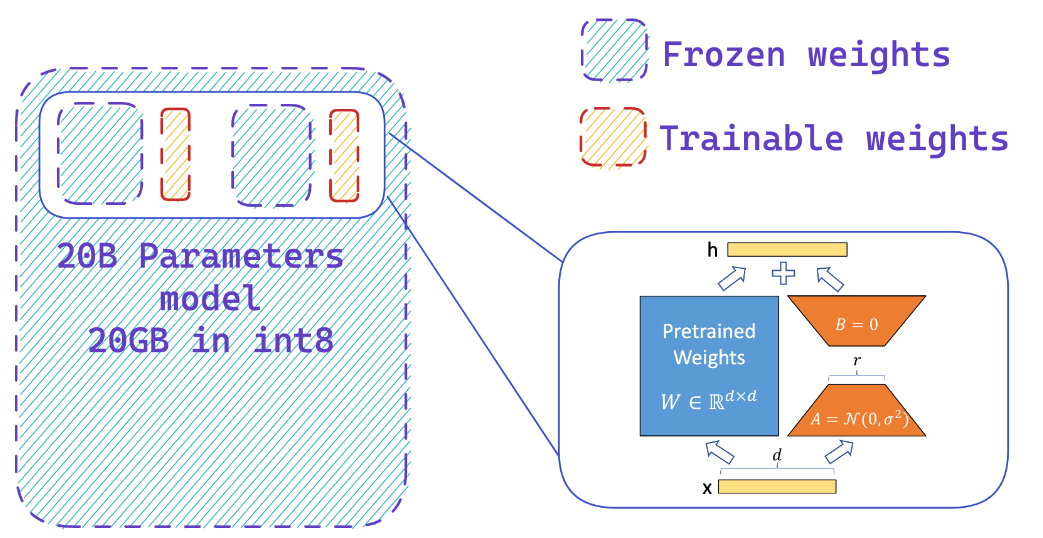
ทรัพยากร
เว็บไซต์
- HF-Bitsandbytes-intigration
- - PEFT: การปรับแต่งพารามิเตอร์อย่างละเอียดของรุ่นพันล้านรุ่นบนฮาร์ดแวร์ที่มีทรัพยากรต่ำ
- llm.int8 () และคุณสมบัติฉุกเฉิน
- Tensorfloat-32-ความแม่นยำ
- rlhf-llm
- Finetuning Falcon LLMs มีประสิทธิภาพมากขึ้นกับ Lora และอะแดปเตอร์โดย Sebastian Raschka
วิดีโอ YouTube
- เพิ่มประสิทธิภาพการปรับแต่งอย่างละเอียดของ LLM: สถาปัตยกรรมที่ดีที่สุดพร้อมการปรับแต่งอะแดปเตอร์ Lora บน GPU ของคุณ
- วิธี finetune alpaca 7b ของคุณเอง
- เอกสาร
- PEFT: พารามิเตอร์การปรับจูนที่มีประสิทธิภาพ
- LORA: การปรับระดับต่ำของแบบจำลองภาษาขนาดใหญ่
- Qlora: LLM แบบเชิงปริมาณพร้อมอะแดปเตอร์ระดับต่ำ
- llm.int8 (): การคูณเมทริกซ์ 8 บิตสำหรับหม้อแปลงในระดับ
- SPQR: การเป็นตัวแทนแบบเบาบางสำหรับการบีบอัดน้ำหนัก LLM ใกล้สูญเสีย
- ที่เก็บ GitHub
- โน๊ตบุ๊ค Python
- Bitsandbytes-4bit-training
Swot of LLMS
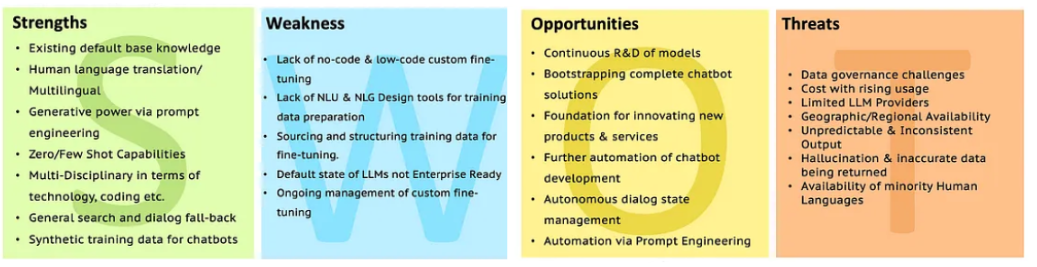 ไปที่การวิเคราะห์ LLM ด้วย SWOT เพื่อการชี้แจงเพิ่มเติม
ไปที่การวิเคราะห์ LLM ด้วย SWOT เพื่อการชี้แจงเพิ่มเติม


