Llm-lora-peft_accumulate
Willkommen im LLM-Lora-Peft_Accumulate Repository!
Dieses Repository enthält Implementierungen und Experimente, die sich auf Großsprachenmodelle (LLMs) unter Verwendung von PEFT (Parametereffizienter Feinabstimmung), LORA (Low-Rang-Anpassung von Großsprachenmodellen) und Qlora (quantisierte LLMs mit niedrigem Adaptern) beziehen.
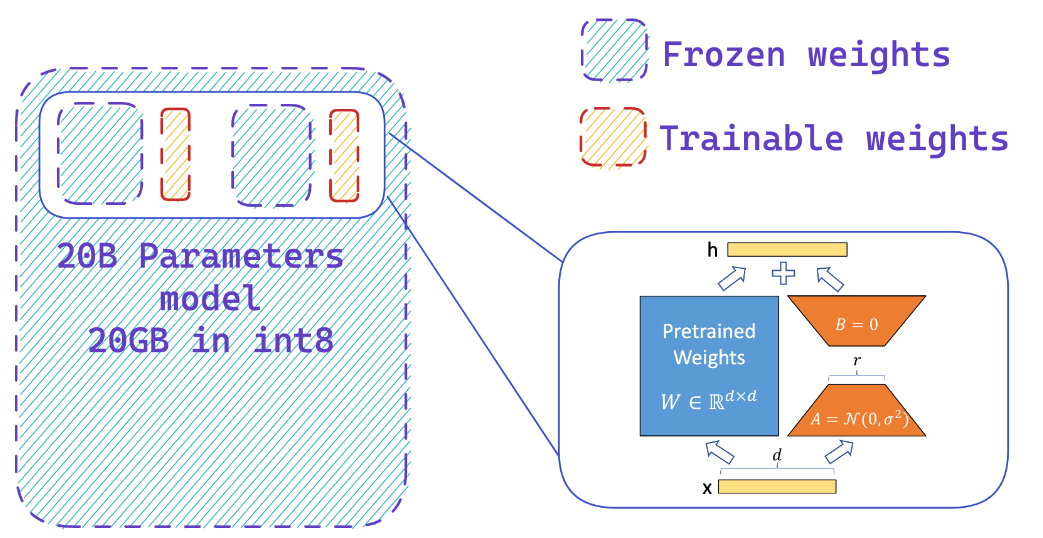
Das Laden eines Modells in 8-Bit-Genauigkeit kann im Vergleich zum vollständigen Präzisionsmodell bis zu 4x Speicher sparen

Was macht PEFT?
Sie fügen leicht Adapter auf einem gefrorenen 8-Bit
Ressourcen
Websites
- Hf-Bitsandbytes-Integration
- ? PEFT: Parametereffiziente Feinabstimmung von Milliardenskala-Modellen auf Hardware mit niedriger Ressourcen
- Llm.int8 () und aufstrebende Merkmale
- Tensorfloat-32-Precision-Format
- Rlhf-llm
- Fonetuning Falcon LLMs effizienter mit Lora und Adaptern von Sebastian Raschka
YouTube -Videos
- Steigern Sie die Feinabstimmung von LLM: Optimale Architektur mit Peft Lora Adapter-Tuning auf Ihrer GPU
- So füllen Sie Ihr eigenes Alpaka 7b
? Papiere
- PEFT: Parameter Effiziente Feinabstimmung
- LORA: Niedrige Anpassung von Großsprachmodellen
- Qlora: Quantisierte LLMs mit niedrigen Adaptern
- LLM.Int8 (): 8-Bit-Matrix-Multiplikation für Transformatoren im Maßstab
- SPQR: Eine spärlich-quantisierte Darstellung für nahezu verlustfreie LLM-Gewichtskompression
? Github -Repositories
? Python -Notizbücher
- Bitsandbytes-4bit-Training
SWOT von LLMs
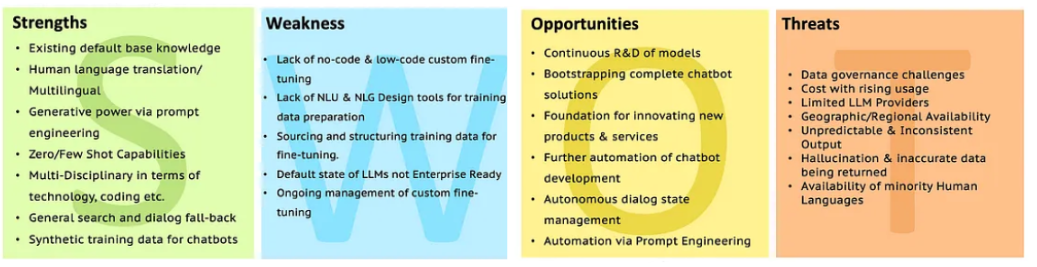 Gehen Sie mit SWOT zur LLM -Analyse, um mehr Klärung zu erhalten.
Gehen Sie mit SWOT zur LLM -Analyse, um mehr Klärung zu erhalten.


