Llm-lora-peft_accumulate
Добро пожаловать в репозиторий LLM-LORA-PEFT_ACCUMULE !
Этот репозиторий содержит реализации и эксперименты, связанные с большими языковыми моделями (LLMS) с использованием PEFT (эффективная настройка параметров), LORA (адаптация с низким уровнем высокого уровня крупных языковых моделей) и Qlora (квантовые LLM с адаптерами с низким уровнем ранга).
Загрузка модели в 8-битной точности может сохранить до 4x памяти по сравнению с полной точностью

Что делает Пефт?
Вы легко добавляете адаптеры на замороженную 8-битную модель, тем самым уменьшая требования к памяти состояний оптимизатора, путем обучения небольшой доли параметров
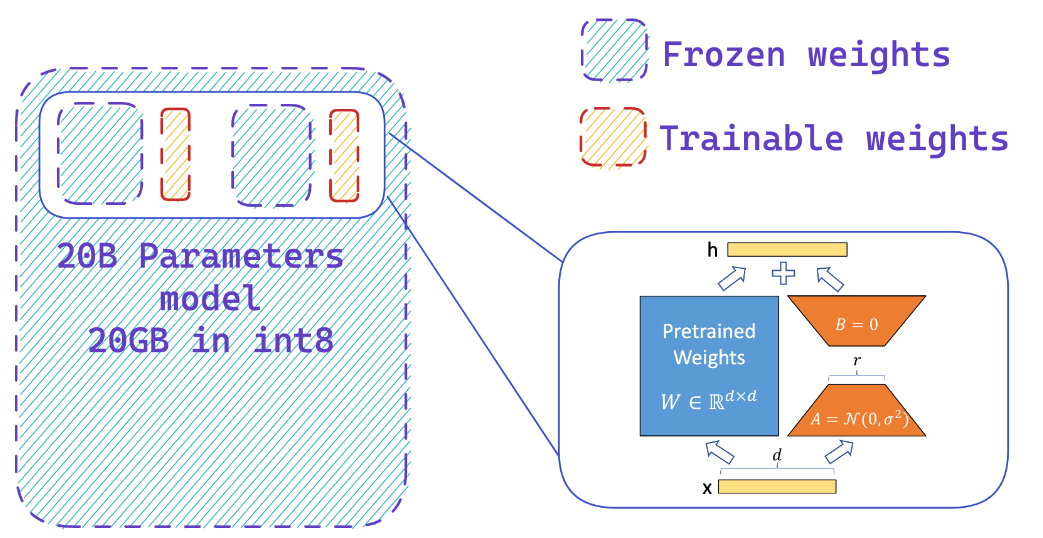
Ресурсы
Веб -сайты
- HF-BitsAndbytes-Integration
- ? PEFT: Параметр-эффективная тонкая настройка моделей миллиарда масштабов на оборудовании с низким разрешением
- Llm.int8 () и возникающие особенности
- Tensorfloat-32-refision-format
- Rlhf-llm
- Senetuning Falcon LLMS более эффективно с Lora и адаптерами Sebastian Raschka
YouTube видео
- Увеличьте производительность тонкой настройки LLM: оптимальная архитектура с адаптером Peft Lora на вашем GPU
- Как фиксировать свою собственную альпаку 7b
? Документы
- PEFT: эффективная настройка параметра
- Лора: адаптация с низким уровнем моделей крупных языков
- Qlora: квантованные LLM с низкими адаптерами
- LLM.Int8 (): 8-битная матрица умножение для трансформаторов в масштабе
- SPQR: разреженное квалифицированное представление для сжатия веса LLM, почти без пожизненного.
? Репозитории GitHub
? Питоны ноутбуки
- Битсандбит-4-битные тренировки
Swot of LLMS
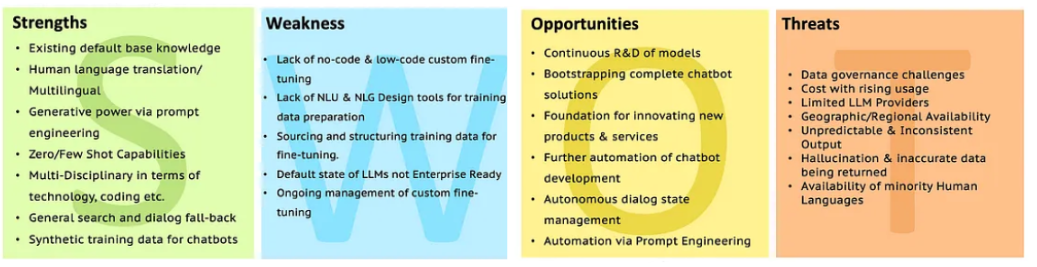 Перейдите в анализ LLM с SWOT, чтобы получить больше разъяснений.
Перейдите в анализ LLM с SWOT, чтобы получить больше разъяснений.


