llm-lora-peft_accumulate
LLM-LORA-PEFT_ACCUMULATEリポジトリへようこそ!
このリポジトリには、 PEFT (パラメーター効率的な微調整)、 LORA (大規模な言語モデルの低ランク適応)、およびQlora (低ランクアダプターを使用した量子化LLM)を使用した大規模な言語モデル(LLMS)に関連する実装と実験が含まれています。
モデルを8ビット精度でロードすると、完全な精度モデルと比較して最大4倍のメモリを節約できます

Peftは何をしますか?
凍結した8ビットモデルにアダプターを簡単に追加するため、少数のパラメーターをトレーニングすることにより、オプティマイザー状態のメモリ要件を削減します。
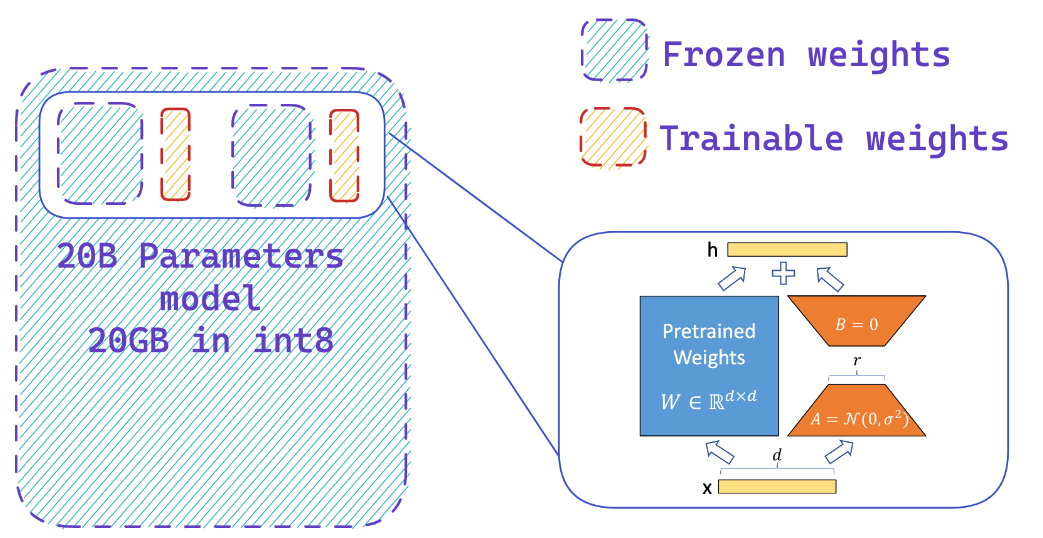
リソース
ウェブサイト
- hf-bitsandbytes-統合
- ? PEFT:低リソースハードウェア上の10億個のスケールモデルのパラメーター効率の高い微調整
- llm.int8()および緊急機能
- Tensorfloat-32 crecision-format
- rlhf-llm
- Sebastian RaschkaによるLoraとAdaptersを使用して、より効率的にFalcon LLMS
YouTubeビデオ
- LLMの微調整パフォーマンスをブースト:GPUのPEFT LORAアダプターチューニング付き最適なアーキテクチャ
- 独自のAlpaca 7bを凝視する方法
?論文
- PEFT:パラメーター効率的な微調整
- LORA:大規模な言語モデルの低ランク適応
- Qlora:低ランクアダプターを備えた量子化LLMS
- llm.int8():大規模な変圧器の8ビットマトリックス増殖
- SPQR:losslessに近いLLM重量圧縮のためのまばらな定量化された表現
? Githubリポジトリ
? Pythonノートブック
LLMSのSWOT
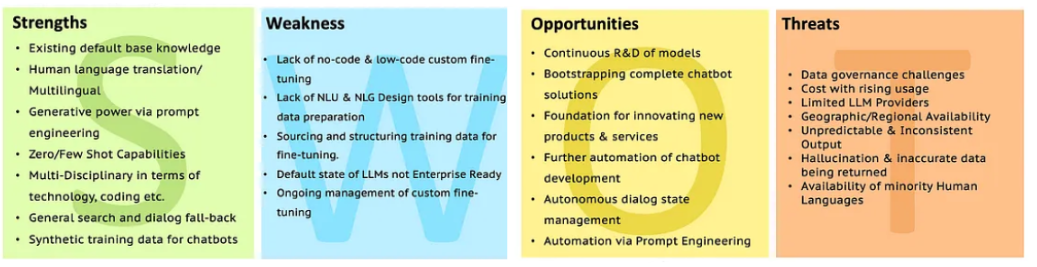 より明確にするために、SWOTを使用してLLM分析に移動します。
より明確にするために、SWOTを使用してLLM分析に移動します。


