LLM-Lora-PEFT_ACCUMULE
¡Bienvenido al repositorio LLM-Lora-Peft_accumulate !
Este repositorio contiene implementaciones y experimentos relacionados con modelos de lenguaje grandes (LLM) utilizando PEFT (ajuste fino eficiente de parámetros), LORA (adaptación de bajo rango de modelos de lenguaje grandes) y qlora (LLM cuantificados con adaptadores de bajo rango).
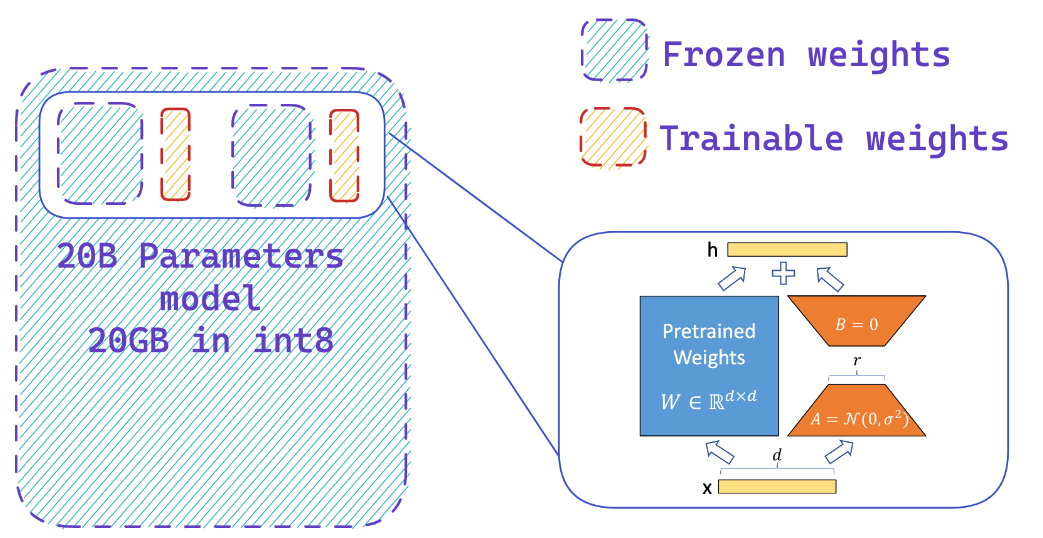
Cargar un modelo en una precisión de 8 bits puede ahorrar hasta 4x memoria en comparación con el modelo de precisión completo

¿Qué hace Peft?
Agrega fácilmente adaptadores en un modelo congelado de 8 bits, reduciendo así los requisitos de memoria de los estados optimizadores, entrenando una pequeña fracción de parámetros
Recursos
Sitios web
- HF-bitsandbytes-integración
- ? PEFT: ajuste fino de los parámetros de modelos a escala de miles de millones en hardware de baja recursos
- LLM.Int8 () y características emergentes
- Tensorfloat-32-precisión formato
- Rlhf-llm
- Finetuning Falcon LLMS de manera más eficiente con Lora y adaptadores de Sebastian Raschka
Videos de YouTube
- BOOST Rendimiento de ajuste fino de LLM: Arquitectura óptima con adaptador de PEFT LORA en su GPU
- Cómo finetune su propio Alpaca 7b
? Papeles
- PEFT: parámetros de ajuste fino eficiente
- Lora: adaptación de bajo rango de modelos de idiomas grandes
- Qlora: LLM cuantificados con adaptadores de bajo rango
- LLM.Int8 (): multiplicación de matriz de 8 bits para transformadores a escala
- SPQR: una representación de sese-cuantizada para la compresión de peso LLM casi sin pérdida
? Repositorios de Github
? Cuadernos de Python
- Bitsandbytes-4bit-entrenamiento
FODA de LLMS
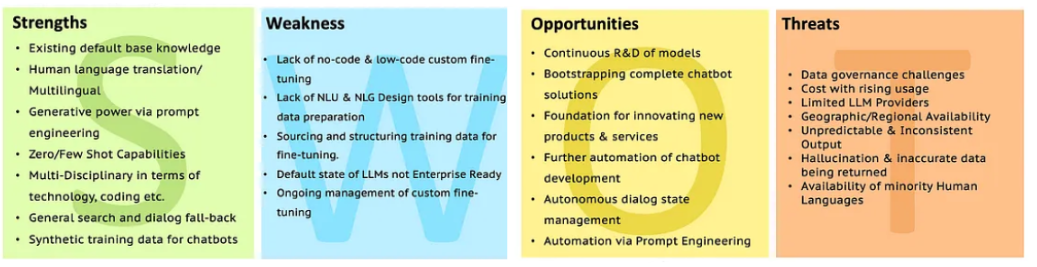 Vaya al análisis LLM con SWOT para obtener más aclaraciones.
Vaya al análisis LLM con SWOT para obtener más aclaraciones.


