LLM-LORA-PEFT_ACCUMULE
Bem-vindo ao repositório LLM-LORA-PEFT_ACCUMULE !
Esse repositório contém implementações e experimentos relacionados a grandes modelos de linguagem (LLMS) usando PEFT (ajuste fino com eficiência de parâmetro), Lora (adaptação de baixo rank de modelos de linguagem grande) e Qlora (LLMS quantizados com adaptadores de baixa classificação).
Carregar um modelo em precisão de 8 bits pode economizar até 4x memória em comparação com o modelo de precisão total

O que Peft faz?
Você adiciona facilmente adaptadores em um modelo congelado de 8 bits, reduzindo assim os requisitos de memória dos estados do otimizador, treinando uma pequena fração de parâmetros
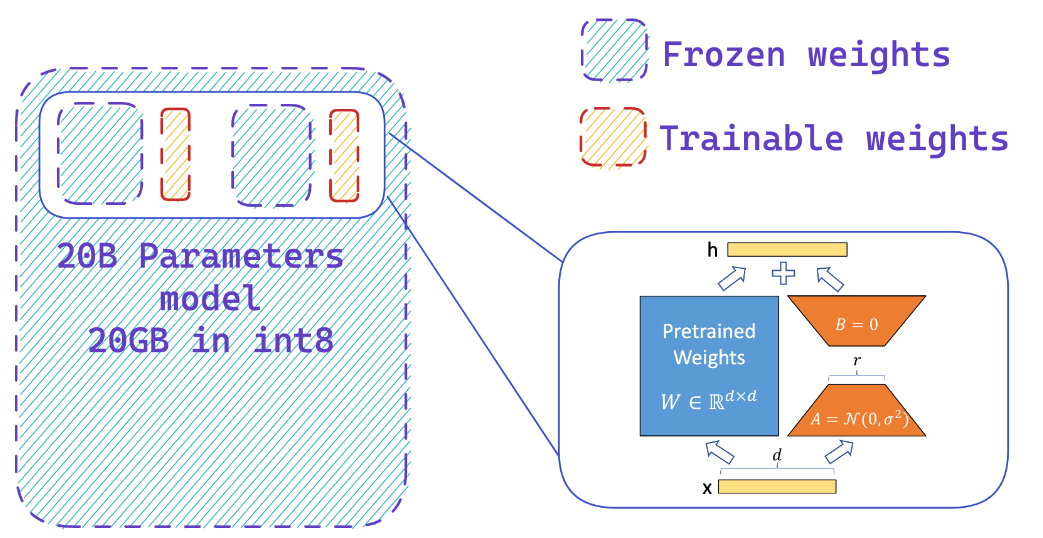
Recursos
Sites
- Integração HF-BitsandBytes
- ? PEFT: ajuste fino com eficiência de parâmetro de modelos de escala de bilhão em hardware de baixo recurso
- Llm.int8 () e recursos emergentes
- Tensorfloat-32-Precision-format
- RlHf-llm
- Finetuning Falcon LLMs com mais eficiência com Lora e adaptadores de Sebastian Raschka
Vídeos do YouTube
- Aumente o desempenho de ajuste fino do LLM: arquitetura ideal com ajuste do Adaptador de Peft Lora na sua GPU
- Como finalizar sua própria alpaca 7b
? Papéis
- Peft: Parâmetro Eficiente Fina Fina
- Lora: adaptação de baixo rank de grandes modelos de linguagem
- Qlora: LLMs quantizados com adaptadores de baixo rank
- LLM.INT8 (): multiplicação de matriz de 8 bits para transformadores em escala
- SPQR: Uma representação desconhecida para a compressão de peso LLM quase sem perda
? Repositórios do GitHub
? Notebooks Python
- Bitsandbytes-4bit-treinamento
Swot of LLMS
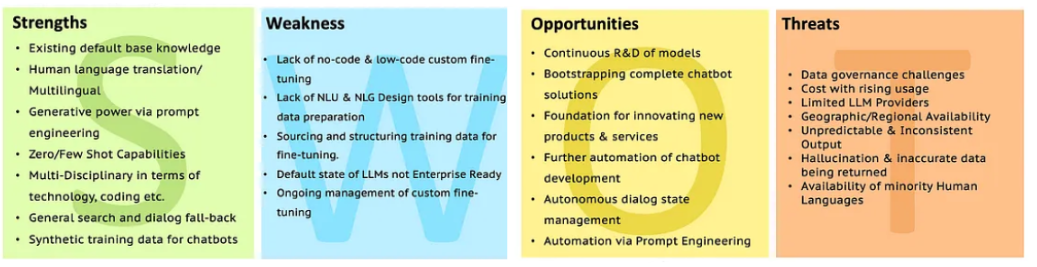 Vá para a análise LLM com SWOT para obter mais esclarecimentos.
Vá para a análise LLM com SWOT para obter mais esclarecimentos.


