llm-lora-peft_accumulate
LLM-LORA-PEFT_ACCUMULATE 저장소에 오신 것을 환영합니다!
이 저장소에는 PEFT (매개 변수 효율적인 미세 튜닝), LORA (대형 언어 모델의 낮은 순위 적응) 및 Qlora (낮은 순위 어댑터가있는 정량화 된 LLM)를 사용한 대형 언어 모델 (LLMS)과 관련된 구현 및 실험이 포함되어 있습니다.
8 비트 정밀도로 모델을로드하면 전체 정밀 모델에 비해 최대 4 배의 메모리를 절약 할 수 있습니다.

Peft는 무엇을합니까?
냉동 8 비트 모델에 어댑터를 쉽게 추가하여 소량의 매개 변수를 훈련시켜 최적화 상태의 메모리 요구 사항을 줄입니다.
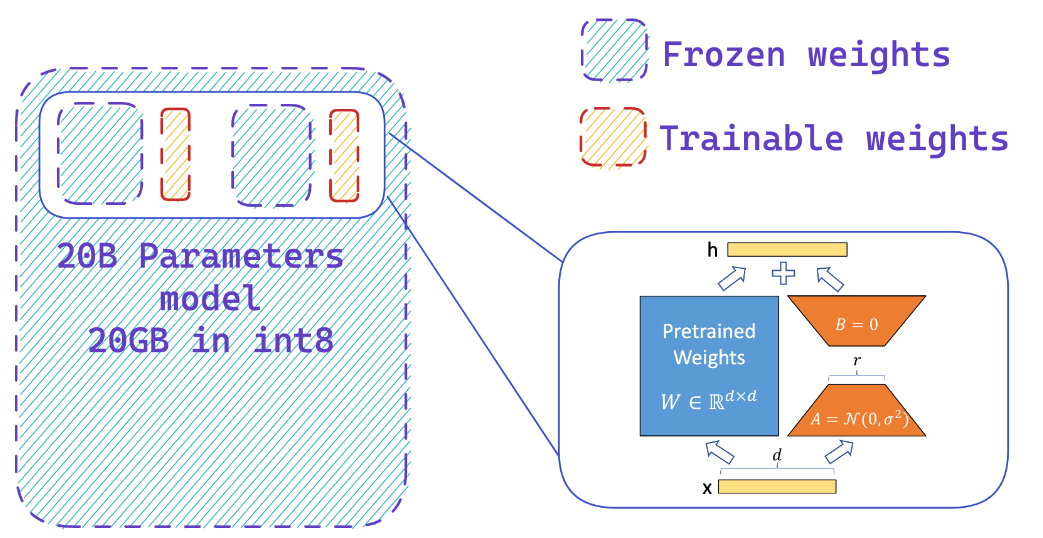
자원
웹 사이트
- HF 비트 및 비트 통합
- ? PEFT : 저주적 하드웨어에서 10 억 규모의 모델의 매개 변수 효율적인 미세 조정
- llm.int8 () 및 출현 기능
- Tensorfloat-32-Precision-Format
- rlhf-llm
- Sebastian Raschka의 LORA 및 어댑터를 사용하여 Falcon LLM을보다 효율적으로 Falcon LLMS
YouTube 동영상
- LLM의 미세 조정 성능 향상 : GPU에서 PEFT LORA 어댑터 조정이있는 최적의 아키텍처
- 자신의 Alpaca 7B를 미세하게하는 방법 7B
? 서류
- PEFT : 매개 변수 효율적인 미세 튜닝
- LORA : 대형 언어 모델의 낮은 순위 적응
- Qlora : 저급 어댑터가있는 양자화 된 LLM
- LLM.INT8 () : 스케일의 변압기에 대한 8 비트 행렬 곱셈
- SPQR : 거의 손이없는 LLM 중량 압축에 대한 희소 정량 표현
? Github 리포지토리
? 파이썬 노트북
LLMS의 SWOT
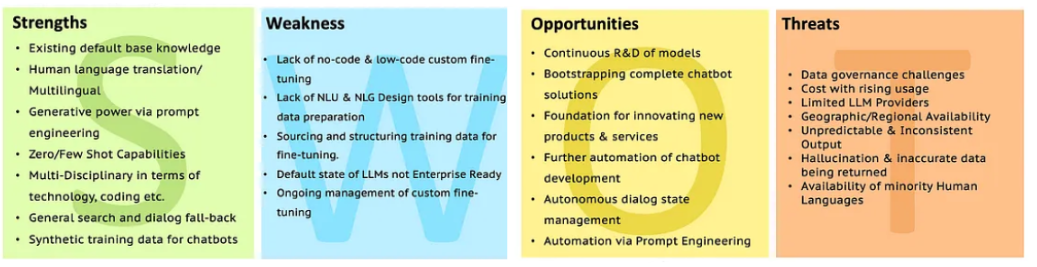 자세한 설명을 위해 SWOT를 사용하여 LLM 분석으로 이동하십시오.
자세한 설명을 위해 SWOT를 사용하여 LLM 분석으로 이동하십시오.


