llm-lora-peft_accumulate
مرحبًا بك في مستودع LLM-Lora-PEFT_ACCUMULITE !
يحتوي هذا المستودع على تطبيقات وتجارب تتعلق بنماذج اللغة الكبيرة (LLMs) باستخدام PEFT (ضبط دقيق فعال للمعلمة) ، و LORA (التكيف المنخفض الرتبة لنماذج اللغة الكبيرة) ، و QLORA (LLMs الكمية مع محولات منخفضة الرتبة).
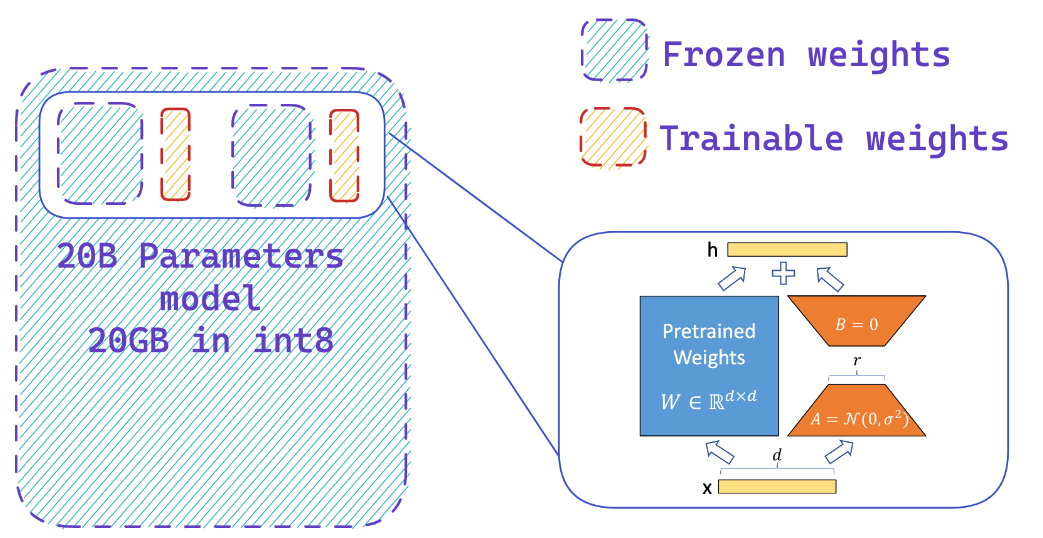
يمكن أن يؤدي تحميل نموذج بدقة 8 بت إلى توفير ما يصل إلى ذاكرة 4x مقارنة بالنموذج الدقيق الكامل

ماذا تفعل PEFT؟
يمكنك بسهولة إضافة محولات على نموذج 8 بتات مجمدة مما يقلل من متطلبات الذاكرة في حالات المُحسّن ، من خلال تدريب جزء صغير من المعلمات
موارد
مواقع الويب
- HF-bitsandbytes-integration
- ؟ PEFT: صقل دقيق للمعلمة من نماذج على نطاق مليار على الأجهزة ذات الموارد المنخفضة
- llm.int8 () والميزات الناشئة
- Tensorfloat-32-Decision-Format
- RLHF-LLM
- Finetuning Falcon LLMS بشكل أكثر كفاءة مع Lora والمحولات من قبل Sebastian Raschka
مقاطع فيديو يوتيوب
- تعزيز الأداء الناعم لـ LLM: العمارة الأمثل ث/ PEFT LORA محول على GPU الخاص بك
- كيفية FineTune الخاص بك الألبكة 7 ب
؟ أوراق
- PEFT: ضبط دقيق فعال
- لورا: التكيف منخفض الرتبة لنماذج اللغة الكبيرة
- qlora: LLMs كمية مع محولات منخفضة الرفاز
- llm.int8 (): مضاعفة مصفوفة 8 بت للمحولات على نطاق واسع
- SPQR: تمثيل متناثر مسبق لضغط وزن LLM شبه الخسارة
؟ مستودعات جيثب
؟ دفاتر بيثون
- bitsandbytes-4bit training
Swot من LLMS
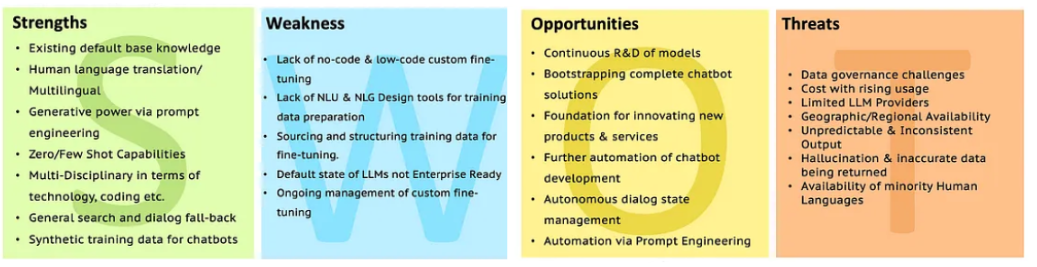 انتقل إلى تحليل LLM مع SWOT لمزيد من التوضيح.
انتقل إلى تحليل LLM مع SWOT لمزيد من التوضيح.


