Llm-lora-peft_accumulate
Selamat datang di Repositori LLM-LORA-PEFT_ACCUMULATE !
Repositori ini berisi implementasi dan eksperimen yang terkait dengan model bahasa besar (LLM) menggunakan PEFT (parameter efisien tuning), LORA (adaptasi rendah dari model bahasa besar), dan qlora (LLM terkuantisasi dengan adaptor rendah).
Memuat model dalam presisi 8-bit dapat menghemat hingga 4x memori dibandingkan dengan model presisi penuh

Apa yang dilakukan Peft?
Anda dengan mudah menambahkan adaptor pada model 8-bit beku sehingga mengurangi persyaratan memori dari negara pengoptimal, dengan melatih sebagian kecil parameter
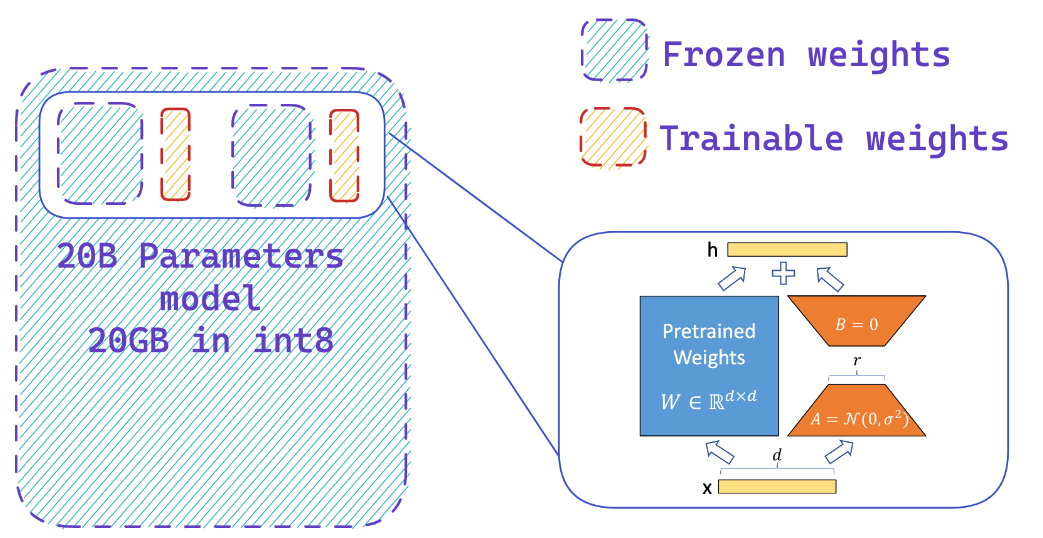
Sumber daya
Situs web
- HF-Bitsandbytes-Integrasi
- ? PEFT: Parameter-efisien menyempurnakan model skala miliaran pada perangkat keras sumber daya rendah
- Llm.int8 () dan fitur yang muncul
- TensorFloat-32-precision-format
- Rlhf-llm
- Finetuning Falcon LLMS lebih efisien dengan Lora dan adaptor oleh Sebastian Raschka
Video YouTube
- Boost Kinerja Fine-Tuning LLM: Arsitektur Optimal W/ Peft Lora Adapter-Tuning di GPU Anda
- Cara finetune alpaca 7b Anda sendiri
? Dokumen
- PEFT: Parameter Efisien Fine Tuning
- Lora: Adaptasi Rendah dari Model Bahasa Besar
- Qlora: LLMS Terkuantisasi dengan adaptor rendah
- Llm.int8 (): multiplikasi matriks 8-bit untuk transformator pada skala
- SPQR: Representasi yang sangat jarang untuk kompresi berat LLM hampir tanpa kehilangan
? Repositori gitub
? Notebook Python
- Bitsandbytes-4bit-Training
SWOT LLMS
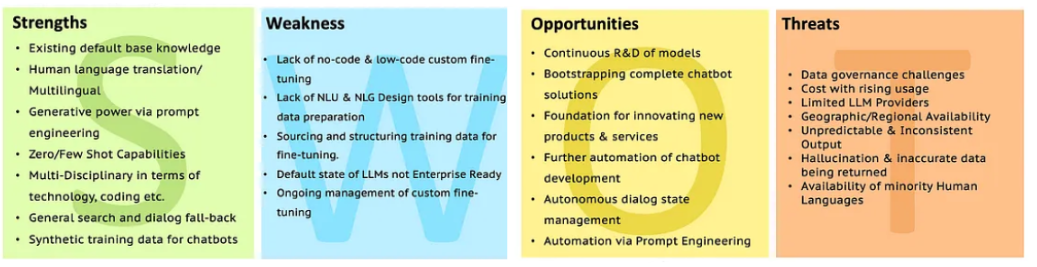 Pergi ke analisis LLM dengan SWOT untuk klarifikasi lebih lanjut.
Pergi ke analisis LLM dengan SWOT untuk klarifikasi lebih lanjut.


