Llm-lora-peft_accumulate
Bienvenue dans le référentiel llm-lora-peft_accumulate !
Ce référentiel contient des implémentations et des expériences liées aux modèles de langage grand (LLMS) à l'aide de PEFT (paramètre Efficient Fine Tuning), LORA (adaptation de faible rang des modèles de grands langues) et Qlora (LLM quantifiée avec des adaptateurs de faible rang).
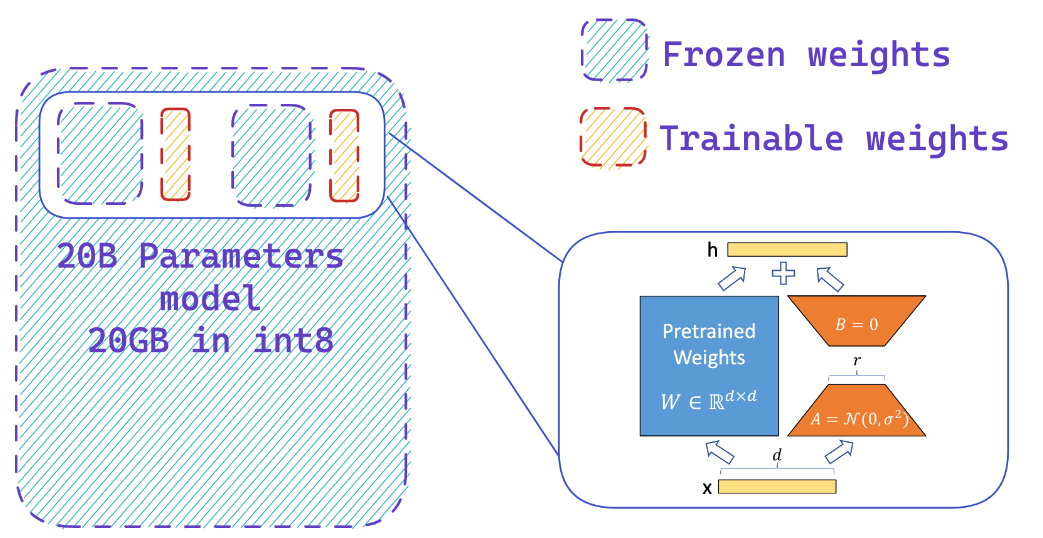
Le chargement d'un modèle en précision 8 bits peut enregistrer jusqu'à 4x mémoire par rapport au modèle de précision complet

Que fait PEFT?
Vous ajoutez facilement des adaptateurs sur un modèle 8 bits congelé réduisant ainsi les exigences de mémoire des états d'optimiseur, en formant une petite fraction de paramètres
Ressources
Sites Web
- Hf-bitsandbytes-intégration
- ? PEFT: Fonction d'adaptation économe en paramètres de modèles à l'échelle des milliards sur le matériel à faible ressource
- Llm.int8 () et caractéristiques émergentes
- Tensorfloat-32-PRÉCISION-FORMAT
- Rlhf-llm
- Finetuning Falcon LLMS plus efficacement avec Lora et les adaptateurs de Sebastian Raschka
Vidéos youtube
- Booster les performances de réglage fin de LLM: Architecture optimale avec adaptateur LORA PEFT sur votre GPU
- Comment finetune votre propre alpaga 7b
? Papiers
- PEFT: paramètre Autonissement fin efficace
- LORA: Adaptation de faible rang des modèles de grandes langues
- QLORA: LLMS quantifiés avec des adaptateurs de bas rang
- Llm.int8 (): multiplication matricielle 8 bits pour les transformateurs à grande échelle
- SPQR: une représentation clairsemée pour une compression de poids LLM presque sans perte
? Référentiels GitHub
? Cahiers python
- BitsandBytes-4 bits-entraînement
SWOT de LLMS
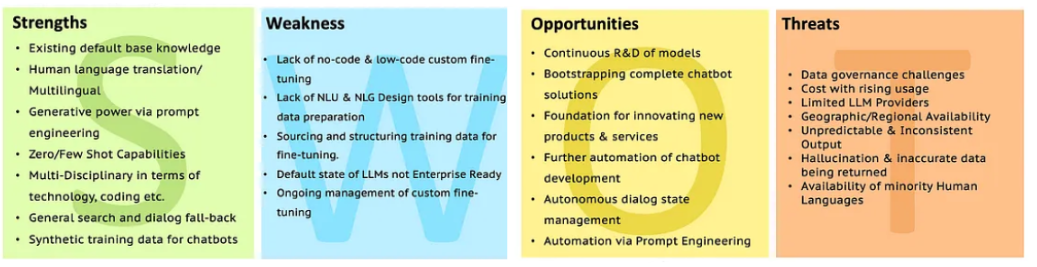 Accédez à l'analyse LLM avec SWOT pour plus de clarification.
Accédez à l'analyse LLM avec SWOT pour plus de clarification.


